Il existe de nombreuses méthodes pour la détection de divers types de features – de quoi en faire un cours entier ! Dans ce chapitre, nous expliquerons deux méthodes couramment utilisées pour détecter des features classiques : le filtre de Canny pour les bords, puis le détecteur de Harris-Stephens pour les coins. Pour cela, nous devons dans un premier temps étudier la notion de gradient d'une image.
Le gradient d'une image
Le gradient d'une image est un outil très utile pour la détection de features. Il s'agit d'un vecteur composé des dérivées partielles de la fonction d'intensité, et calculé en chaque pixel :
Les dérivées partielles sont définies formellement comme des limites de taux d'accroissement :
La dérivée partielle par rapport à (ou ) permet d'étudier les variations d'intensités de l'image dans la direction de l'axe des abscisses (ou des ordonnées).
Le gradient étant un vecteur, il possède une norme (ou amplitude) et une direction donnée par l'angle :
Les dérivées partielles sont alors approximées avec la méthode des différences finies :
Nous pouvons facilement calculer ces approximations en filtrant l'image de matrice :
Ces noyaux de convolution ne s'utilisent jamais en pratique puisqu'ils ne sont pas centrés : on préfère pour approximer , et pour .
Ces nouveaux masques exploitent les informations provenant de part et d'autre du pixel, et non d'un seul côté. Par exemple, l'application du premier en renvoie , qui n'est autre que la somme de (approximation de par la droite) et (approximation par la gauche).
La détection des bords avec le filtre de Canny
Les bords ou contours (edges en anglais) fournissent beaucoup d'information à propos d'une image : ils délimitent les objets présents dans la scène représentée, les ombres ou encore les différentes textures.
Un moyen pour détecter les bords serait de segmenter l'image en objets, mais il s'agit d'un problème difficile. Le filtre de Canny développé en 1986 est une solution plus simple, qui repose sur l'étude du gradient.
Les bords se situent dans les régions de l'image qui présentent de forts changements. En effet, les contours des objets correspondent à des changements de profondeur (on passe d'un objet à un autre situé en arrière-plan), et les ombres et différentes textures à des changements d'illumination.
Mathématiquement, la détection des bords revient donc à chercher les points de l'image où la fonction d'intensité varie brusquement. Or, nous savons qu'une amplitude du gradient élevée indique un fort changement d'intensité. Le but est donc de chercher les maxima locaux de .
La méthode de détection des bords par le filtre de Canny comporte cinq étapes :
Etape 1. Réduction du bruit
Le bruit de l'image peut nous induire en erreur : les pixels aux valeurs aberrantes provoquent des forts changements d'intensité alors qu'ils n'appartiennent à aucun contour.
L'image doit donc être débruitée au préalable avec un filtre adapté. Comme étudié dans la première partie du cours, on utilisera un filtre gaussien pour éliminer le bruit additif, et un filtre médian pour le "poivre et sel" (très rare).
Etape 2. Calcul du gradient de l'image
Le gradient de l'image débruitée est approximé par filtrage de convolution, le plus souvent avec les masques de Sobel.
On calcule ensuite l'amplitude et la direction du gradient en tout point de l'image :
Les bords sont repérés par les points de forte amplitude.
Etape 3. Suppression des non-maxima
Les bords trouvés à l'étape précédente sont trop épais. Pour les rendre plus précis, on ne sélectionne que les points pour lesquels l'amplitude du gradient est localement maximale dans sa direction.
Pour cela, on quantifie et on trouve les deux voisins de chaque pixel en suivant la direction de son gradient.
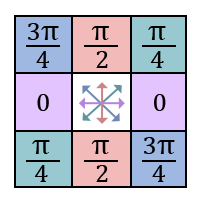
Par exemple, un pixel pour lequel aura pour voisins les pixels et
Le pixel courant est retenu que si son amplitude est plus grande que celles de ses deux voisins.
Etape 4. Seuillage
Parmi les points sélectionnés dans l'étape précédente, on ne retient finalement que ceux dont l'amplitude du gradient est supérieure à un certain seuil.
Il est difficile de choisir la valeur d'un "bon" seuil. C'est pourquoi on privilégie le seuillage par hystérésis, qui utilise deux seuils, notés et .
Si , alors le pixel est situé sur un bord
Si , alors le pixel est situé sur un bord si et seulement si l'un de ses huit voisins aussi
Sinon, le pixel n'est pas sur un bord
Et c'est tout !
Ce détecteur est facile à mettre en oeuvre, mais présente deux limitations majeures :
Le choix des paramètres (variance du filtre gaussien et les deux seuils). Ils ont un impact très important sur le temps de calcul et la qualité des résultats, mais il n'existe pas de méthode automatique pour déterminer les meilleures valeurs pour chaque image...
Les bords détectés sont des points et pas des courbes, et il est difficile de "chaîner" les points.
La localisation des coins avec le détecteur de Harris-Stephens
Les coins (corners en anglais) sont d'autres features riches en informations. Ils se situent dans les régions où l'intensité varie fortement dans au moins deux directions :

Le détecteur de Harris-Stephens, développé en 1988, est une technique très populaire permettant de repérer les coins dans une image. Il est basé sur le détecteur de Moravec, qui exploite le gradient.
Le détecteur de Moravec
Le détecteur de Moravec permet de déterminer les changements d'intensité autour d'un pixel donné.
L'idée est de considérer un voisinage centré en ce pixel de le décaler légèrement dans plusieurs directions, puis de calculer pour chaque déplacement la variation d'intensité. Cela se traduit mathématiquement par la fonction suivante :
représente la différence d'intensité entre le voisinage centré en le pixel et le voisinage décalé de .
On applique cette fonction dans les trois situations principales ci-dessous :
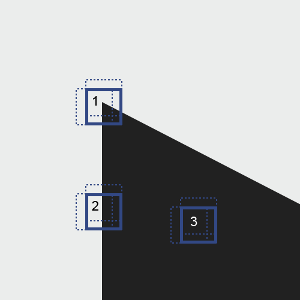
Situation 1 : la zone contient un coin, l'intensité change brusquement dans plusieurs directions, donc la fonction prend de fortes valeurs dans ces directions
Situation 2 : la zone contient un contour, l'intensité change brusquement si on se déplace horizontalement et très peu verticalement. Ainsi, prend de fortes valeurs si on déplace perpendiculairement au contour, et des faibles pour des déplacements le long du contour.
Situation 3 : pas de changement d'intensité : la région est uniforme. prend alors de faibles valeurs dans toutes les directions
Le pixel correspond à un coin si la plus petite variation d'intensité autour de lui est maximale par rapport à celle des autres pixels. Autrement dit, on cherche les maxima locaux de .
Le détecteur de Harris-Stephens
Le détecteur de Harris-Stephens est une amélioration du détecteur de Moravec. Il apporte trois modifications majeures :
1. La fenêtre carrée centrée en est remplacée par une fenêtre gaussienne :
2. est approximé par un développement de Taylor au voisinage de :
On obtient donc finalement
Avec . Comme d'habitude, les dérivées partielles sont approximées avec les masques de Sobel. La matrice décrit le comportement local de .
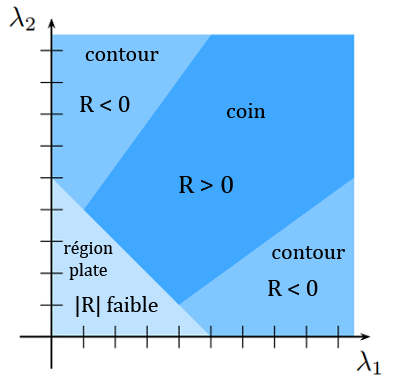
3. Les coins sont détectés selon un nouveau critère : les valeurs propres et de .
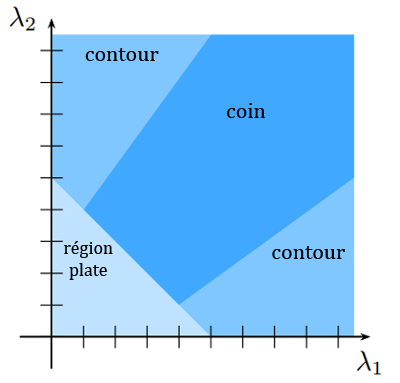
Trouver les valeurs propres de peut être fastidieux. Une alternative consiste alors à analyser les valeurs de l'opérateur : avec une constante choisie entre 0,04 et 0,06.
Étapes de l'algorithme du détecteur de Harris-Stephens
La détection des coins avec le détecteur de Harris-Stephens se fait donc en quatre étapes :
Etape 1. Calcul de la matrice pour chaque pixel. Les dérivées partielles sont approximées en filtrant l'image par convolution avec les masques de Sobel
Etape 2. Calcul de pour chaque pixel
Etape 3. Seuillage de . On sélectionne les pixels pour lesquels , où est un seuil à choisir
Etape 4. Suppression des non-maxima de . Les coins correspondent aux maxima locaux de : pour les trouver, on applique aux pixels sélectionnés la méthode décrite dans l'étape 3 du filtre de Canny
