Introduction à l'algorithme SIFT
Le détecteur de Harris-Stephens étudié au chapitre précédent présente un défaut majeur : les coins qu'il localise sont invariant par rotation, mais pas par changement d'échelle ! Cela signifie qu'on parvient à détecter les mêmes coins (avec des orientations différentes) lorsqu'on applique une rotation à l'image, mais pas lorsqu'on change le zoom :
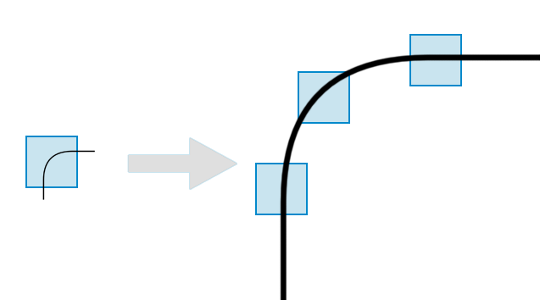
Pour pouvoir repérer les coins à différentes échelles, on doit alors adapter la taille de la fenêtre utilisée par le détecteur de Harris-Stephens : c'est une tâche fastidieuse et difficile !
Lorsque des éléments visuels se retrouvent dans plusieurs images mais avec des orientations et des échelles différentes, il vaut mieux utiliser l'algorithme SIFT (Scale-invariant feature transform). Cette méthode, développée en 1999 et très populaire dans le domaine de la vision par ordinateur, permet d'extraire des features (ou points d'intérêt) de l'image et de calculer leurs descripteurs.
C'est quoi déjà, un descripteur ?
Un descripteur est un vecteur qui décrit le voisinage de la feature à laquelle il est associé. Il est utilisé pour repérer les paires de features qui se ressemblent le plus dans deux images. Pour faciliter cette étape de matching, le descripteur doit présenter de nombreuses propriétés d'invariance (rotation, échelle, illumination). Ainsi, les descripteurs de deux features identiques à un changement géométrique ou photométrique près doivent donc être aussi proches que possible. L'étape de matching revient alors à comparer les descripteurs.
L'algorithme SIFT se divise en plusieurs étapes, que nous allons expliquer tout au long de ce chapitre :
Détection : création de l'espace des échelles, calcul des "DoG", localisation des points d'intérêt
Description : assignation d'orientation, création des descripteurs
Le détecteur SIFT
La première étape consiste à détecter les features de l'image. Chaque feature est une zone circulaire intéressante, repérée par son centre (point d'intérêt), et dont le rayon est proportionnel à son échelle caractéristique. La force du détecteur SIFT est sa capacité à trouver des rayons différents, et donc des features de différentes tailles.
Création de l'espace des échelles (scale-space)
Pour détecter des features de différentes tailles, on construit l'espace des échelles. Cela consiste à flouter notre image et à réduire sa taille plusieurs fois. Le flou est créé en appliquant un filtre gaussien de variance , noté , qui va estomper les détails de l'image de rayon inférieur à . Ainsi, plus est élevé, plus l'image est floue, et donc plus les features trouvées seront de grande échelle. De même, la taille de l'image contrôle la taille des features détectées. Chaque fois qu'on réduit l'image, on définit une nouvelle octave.
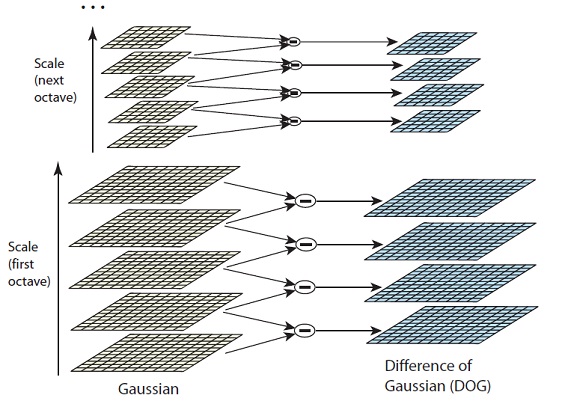
Calcul des DoG
Ce n'est pas un chien, mais l'abréviation de "Difference of Gaussians" (différence des Gaussiennes) ! DoG désigne une image obtenue en faisant la soustraction de deux images successives (deux flous Gaussiens de paramètres et ) dans une octave. Cette nouvelle image contient alors seulement les détails de l'image originale dont l'échelle varie entre et .
On calcule les DoG pour chaque paire d'images consécutives dans chaque octave de l'espace des échelles :
Localisation des points d'intérêt
Les points d'intérêts font partie des extrema locaux de l'ensemble des DoG. Pour les trouver, on compare chaque pixel d'une DoG à ses 8 voisins, mais également à ses 9 voisins dans les DoG au-dessus et en-dessous :
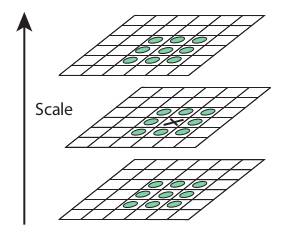
Si la valeur du pixel est inférieure ou supérieure à celles des 26 voisins, alors celui-ci est considéré comme un extremum local, et donc comme un point d'intérêt potentiel.
A ce stade, les points sélectionnés sont nombreux, mais ils ne correspondent pas tous à des points d'intérêt : il faut faire le tri !
On se débarrasse d'abord des points qui n'ont pas assez de contraste : on rejette ceux dont l'intensité est inférieure à un seuil fixé. Comme les localisations ont été obtenues par interpolation, les intensités correspondantes doivent également être interpolées.
Enfin, les points situés sur les bords sont éliminés car ils sont très instables et donc difficiles à retrouver d'une image à l'autre : le moindre changement sur l'image (comme du bruit) peut les faire se déplacer le long du contour, ou même les faire disparaître ! Pour cela, on s'inspire du critère du détecteur de Harris-Stephens du chapitre précédent : on rejette les points tels que avec la matrice hessienne de la DoG et .
Le descripteur SIFT
Maintenant que les points d'intérêt de l'image ont été détectés, il ne reste plus qu'à les décrire. Cela revient à assigner une orientation à chaque point, puis à construire les descripteurs SIFT.
Assignation d'orientation
Cette étape consiste à déterminer l'orientation de chacun des points d'intérêts afin de rendre le descripteur invariant par rotation. L'orientation d'un point d'intérêt est la direction du gradient la plus rencontrée autour de ce point.
On considère un voisinage du point d'intérêt, et on calcule l'amplitude et la direction du gradient en chaque pixel de ce voisinage. Pour cela, le gradient est approximé avec le filtrage par convolution (comme d'habitude ! Par exemple, avec le filtre de Sobel).
On construit ensuite un histogramme qui indique la répartition des orientations du gradient dans le voisinage. Il contient en général 36 classes, chacune représentant donc un intervalle de 10°. La contribution de chaque pixel est proportionnelle à l'amplitude de son gradient, mais aussi à sa proximité avec le point d'intérêt. Cette proximité est quantifiée à l'aide d'une fenêtre gaussienne.
L'orientation du point d'intérêt correspond alors à la classe où l'histogramme lissé présente un "pic".
Il arrive que l'histogramme présente plusieurs pics : cela signifie que le point d'intérêt a plusieurs orientations dominantes. Dans ce cas, on duplique le point d'intérêt autant de fois qu'il a d'orientations dominantes, et on attribue à chaque copie une de ces orientations.
Création des descripteurs
Enfin, nous allons créer les descripteurs des points d'intérêt selon la méthode SIFT.
Pour cela, on considère une fenêtre carrée de taille pixels centrée autour d'un point d'intérêt et proportionnelle à son niveau de flou de détection . On découpe celle-ci en 16 petites fenêtres carrées, chacune de taille pixels.
Pour chacune des 16 fenêtres, un histogramme des orientations du gradient est construit de la même manière que dans l'étape précédente. Mais cette fois, les orientations sont décrites par rapport à l'orientation du point d'intérêt : on soustrait chacune d'elle par l'orientation dominante trouvée précédemment.
Chaque histogramme contient 8 classes (une classe est donc ici un intervalle de 45°). De plus, la contribution de chaque pixel dépend non seulement de l'amplitude de son gradient, mais aussi de sa proximité avec le point d'intérêt : plus un pixel est loin du centre de la fenêtre , moins il aura d'impact dans l'histogramme. Pour cela, on multiplie chaque amplitude par une fonction gaussienne 2D.
Chacun des 16 histogrammes construits contient 8 valeurs (les hauteurs des classes), ce qui nous donne un total de 128 valeurs. On stocke ces valeurs dans un vecteur (de taille 128), qui représente alors notre descripteur SIFT !
On normalise d'abord le vecteur, en le divisant par sa norme euclidienne : cela permet de garantir l'invariance par changement de contraste. Puis, on remplace tous les éléments du vecteur supérieurs à 0.2 par 0.2, et on re-normalise. Ainsi, le descripteur devient également insensible aux changements d'exposition.
