Interprétez votre partition
Visualisez vos données
Nous avons vu comment partitionner nos données. Mais pour présenter les données, il serait bien d’avoir une représentation graphique adaptée, n’est-ce pas ?
« Oui, bien sûr », me répondrez-vous. Ici, nous sommes face au même problème qu’au début de la partie 2 de ce cours : nous voulons représenter des données à dimensions de manière intelligible.
Après le clustering, nos données sont toujours à dimensions. La seule chose qui a changé, c’est que nous avons attribué à chaque point une classe (un cluster).
Ainsi, nous affichons les points dans le premier plan factoriel. Ensuite, pour représenter les classes que nous avons déterminées, il suffit de colorer les points en fonction de leur groupe (ou alors d’afficher les points d’une même classe avec un même symbole : carré, rond, etc., ce qui est plus pratique pour les personnes souffrant de daltonisme) :
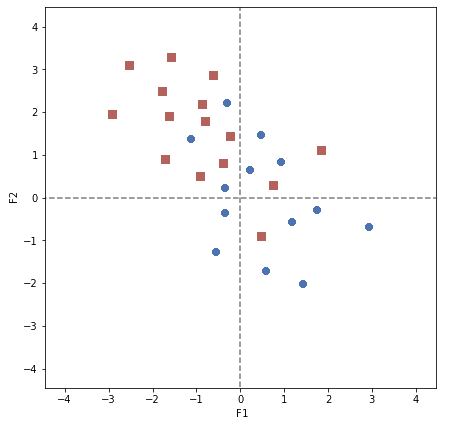
Et nos centroïdes ?
Les centroïdes de chaque classe sont eux aussi des points à dimensions. Nous pouvons donc aussi les représenter sur le premier plan factoriel :
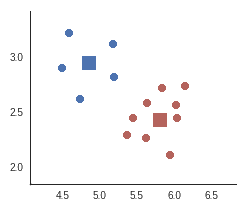
Attention, cependant, à ne pas prendre en compte les centroïdes lors du calcul des axes principaux d’inertie.
En effet, seuls les individus doivent entrer en compte dans ce calcul, pas les centroïdes. Il faut donc juste se contenter de calculer la projection de chaque centroïde sur le premier plan factoriel pour l’afficher.
En pratique
Commençons par les imports :
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.decomposition import PCA
from sklearn.cluster import KMeans
from sklearn.preprocessing import StandardScalerChargeons notre matrice X. On va prendre, ou reprendre le dataset des fleurs d'iris :
# On charge le dataset iris :
iris = datasets.load_iris()
# On extrait X :
X = iris.data
# On le transforme en DataFrame pour pouvoir mieux visualiser nos données :
X = pd.DataFrame(X)
X.head()On peut maintenant faire notre clustering :
# On instancie notre Kmeans avec 3 clusters :
kmeans = KMeans(n_clusters=3)
# On l'entraine :
kmeans.fit(X)
# On peut stocker nos clusters dans une variable labels :
labels = kmeans.labels_
labelsNous aurons également besoin des centroïdes :
# On peut stocker nos centroids dans une variable :
centroids = kmeans.cluster_centers_
centroidsNous pouvons passer à la partie visualisation. Pour ce faire, nous allons réaliser une ACP.
On commence donc par scaler nos données :
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)Ensuite on fait notre ACP, ici avec 3 composantes :
pca = PCA(n_components=3)
pca.fit(X_scaled)Enfin, on projette nos points dans le "nouvel espace" :
X_proj = pca.transform(X_scaled)
X_proj = pd.DataFrame(X_proj, columns = ["PC1", "PC2", "PC3"])
X_proj[:10]On peut désormais afficher nos points :
fig, ax = plt.subplots(1,1, figsize=(8,7))
ax.scatter(X_proj.iloc[:, 0], X_proj.iloc[:, 1], c= labels, cmap="Set1")
ax.set_xlabel("F1")
ax.set_ylabel("F2")
plt.show()On obtient :
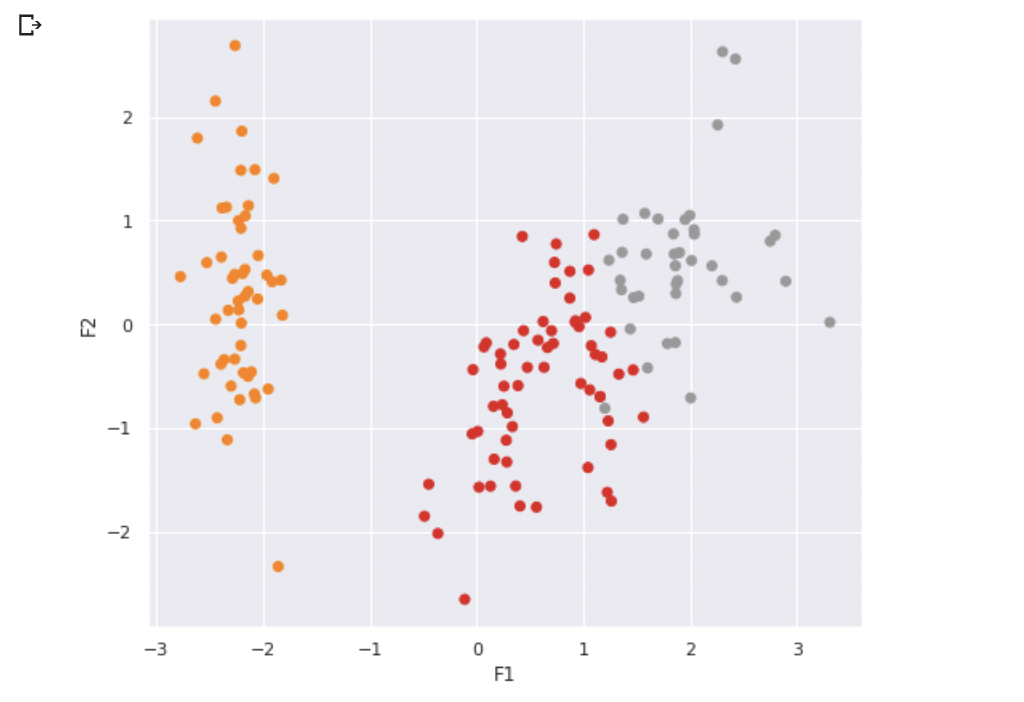
C'est assez clair... Il y a bien 2 groupes très distincts, mais un de ces groupes est subdivisé en 2. Avant d'aller plus loin, intéressons-nous aux centroïdes.
On scale et on projette dans le "nouvel espace":
# On utilise bien le scaler déjà entrainé :
centroids_scaled = scaler.fit_transform(centroids)
# et on utilise l'ACP déjà entrainée :
centroids_proj = pca.transform(centroids_scaled)
# Création d'un dataframe pour plus de clarté:
centroids_proj = pd.DataFrame(centroids_proj,
columns = ["F1", "F2", "F3", "F4"],
index=["cluster_0", "cluster_1", "cluster_2"])Et on affiche le graphique pour F1 et F2 :
# On définit notre figure et son axe :
fig, ax = plt.subplots(1,1, figsize=(8,7))
# On affiche nos individus, avec une transparence de 50% (alpha=0.5) :
ax.scatter(X_proj.iloc[:, 0], X_proj.iloc[:, 1], c= labels, cmap="Set1", alpha =0.5)
# On affiche nos centroides, avec une couleur noire (c="black") et une frome de carré (marker="c") :
ax.scatter(centroids_proj.iloc[:, 0], centroids_proj.iloc[:, 1], marker="s", c="black" )
# On spécifie les axes x et y :
ax.set_xlabel("F1")
ax.set_ylabel("F2")
plt.show()On obtient :
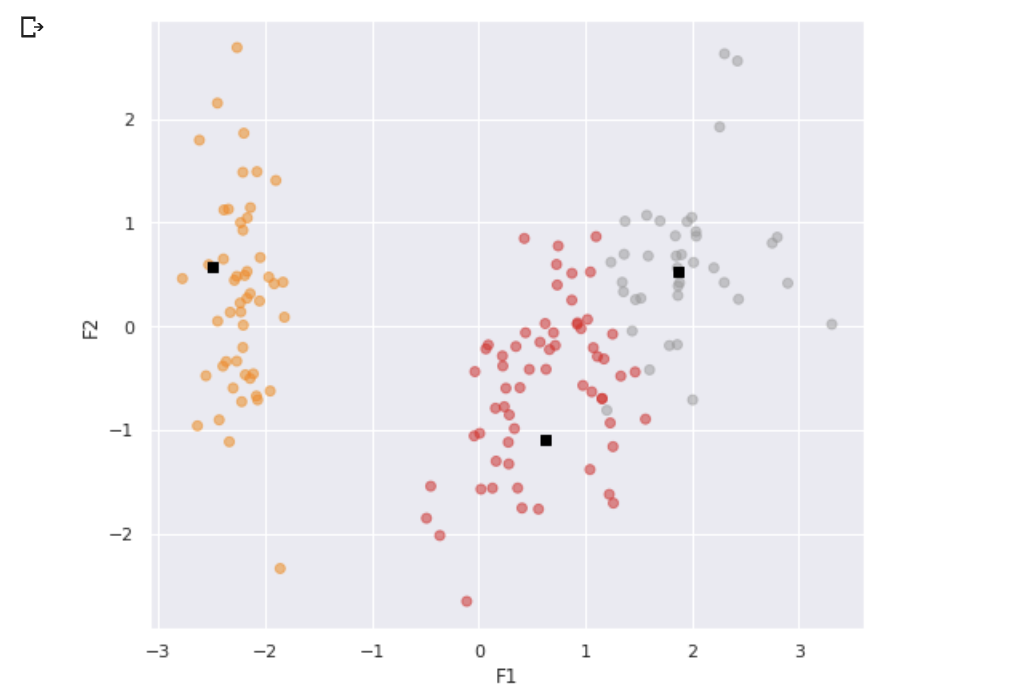
2 dimensions, pas mal ! Mais on peut faire mieux, non ?
Oui, bien sûr! On peut faire des graphiques à 3 dimensions :
# On définit notre figure et notre axe différemment :
fig= plt.figure(1, figsize=(8, 6))
ax = fig.add_subplot(111, projection="3d", elev=-150, azim=110)
# On affiche nos points :
ax.scatter(
X_proj.iloc[:, 0],
X_proj.iloc[:, 1],
X_proj.iloc[:, 2],
c=labels, cmap="Set1", edgecolor="k", s=40)
# On spécifie le nom des axes :
ax.set_xlabel("F1")
ax.set_ylabel("F2")
ax.set_zlabel("F3")
On obtient :
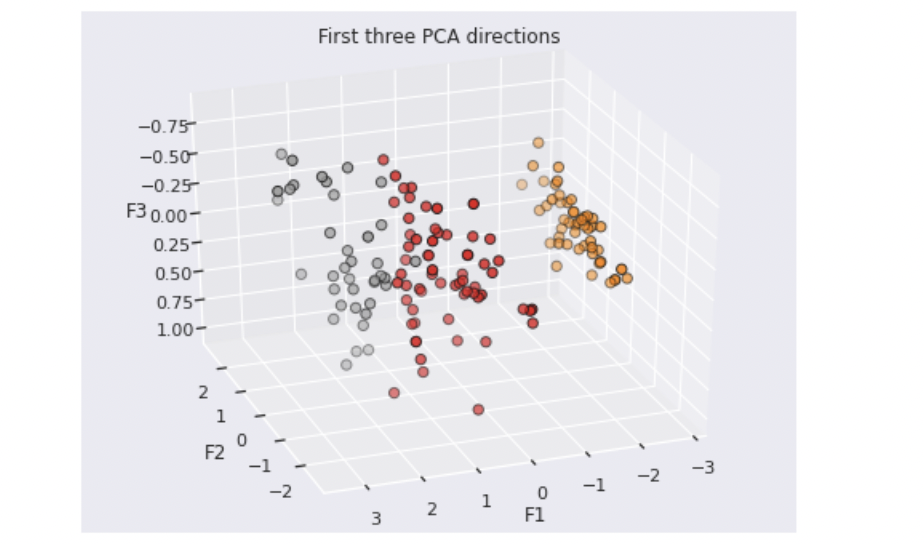
Je vous laisse regarder cela en détail, mais en spécifiant le 3e axe, on comprend bien pourquoi nous avons choisi 3 clusters et non 2.
Les pièges de la visualisation
Pour ce qui est de la visualisation, il est possible d'aller plus loin et de faire de choses bien plus précises : l'utilisation de seaborn ou de plotly peut aider dans ce sens.
Attention toutefois à ne pas vous perdre en chemin. Faire une visualisation simple, cela peut prendre 1, 5, 10 ou même 15 minutes. Mais parfois, on veut rajouter quelques "petits détails" à nos graphiques pour qu'ils soient plus beaux, plus grands, plus clairs.
Sur le papier c'est une bonne idée, mais il peut arriver que ces "petits" détails se transforment en 15, 30, 45 minutes, une heure, parfois plus. Faites donc attention à ne pas vous perdre en chemin !
Comme disait ma grand-mère, le mieux est l'ennemi du bien.
D'autres méthodes de projection
Bon, jusque-là, tout va bien ! Un peu trop bien, même ! En effet, dans notre cas, F1 et F2 représentent près de 95 % de la variance observée. C'est beaucoup ! Il arrivera souvent que cela ne soit pas aussi simple.
Imaginons un cas extrême dans lequel le graphique de la variance expliquée soit une droite :
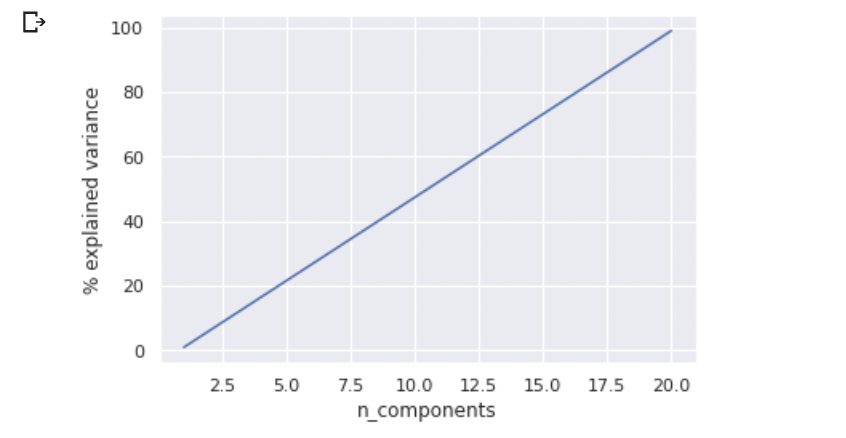
Le problème ici, c'est que d'une part il n'y pas de "coude" pour sélectionner le nombre de composantes, mais surtout, si on ne prend que les 3 premières dimensions pour notre représentation graphique, nous n'aurons que 15 % de la variance expliquée.
15 %, mais c'est très peu ?
Oui, c'est très peu. Encore une fois, c'est un exemple théorique, mais cela nous pose un problème. Notre projection des points n'aura que peu de sens, et ne nous permettra pas de visualiser nos clusters au mieux.
Mais alors comment faire ?
Très bonne question ! Mais tout d'abord, pas de panique :). Cela n'est pas très courant...
Vous n'aurez pas souvent ce type de configuration, mais, si cela devait arriver, sachez que l'astuce consiste à utiliser une autre méthode de réduction de dimensionnalité.
Nous avons abordé l'ACP, et dans 90 % des cas, une ACP suffit. Mais sachez, ou retenez, qu'il existe d'autres méthodes de réduction de dimensionnalité.
Nous ne les couvrirons pas dans ce cours. Encore une fois, cela s'utilise dans des contextes très précis, et assez "rares", mais pour les plus curieux d'entre vous, jetez un coup d'œil à la méthode du T-SNE, à la LDA ou à la TSVD.
Allez plus loin
Vous trouverez plus d'exemples dans ce notebook.
En résumé
Le travail de représentation graphique est très important dans le cadre d'un clustering.
Pour ce faire, on peut utiliser l'ACP pour réduire nos dimensions et projeter nos points.
On affiche ensuite nos points dans le nouvel espace projectif en 2 ou 3 dimensions.
Faire une ACP puis un clustering n'est pas équivalent à faire l'inverse. Par défaut, on applique plus souvent la 2e méthode.
Les possibilités de visualisations sont très nombreuses. Il faut éviter de se perdre dans les détails.
Il pourra arriver que vous utilisiez d'autres méthodes de réduction de dimensionnalité comme le TSNE, la LDA ou la TSVD.
Et voilà, vous êtes arrivé au dernier chapitre du cours. Il ne vous reste qu'un exercice pratique et un quiz avant de tout boucler. Vous êtes prêt ? Allons-y !
