Découvrez l'utilité d'un RAG pour un LLM

Découvrez le concept de LLM
Imaginez une petite mairie, comme celle de Trifouillis-sur-Loire, où Josiane, l’agent d’accueil, est submergée de questions quotidiennes :
Quels documents fournir pour un mariage ?
Comment obtenir une subvention pour une rénovation énergétique ?
Quand les travaux sur la route seront-ils terminés ?
Avec des classeurs encombrants et des fichiers Excel capricieux, Josiane perd un temps précieux à chercher des réponses. Le défi ici est universel : comment accéder rapidement à des informations précises ?
C’est là que vous intervenez en tant que consultant en data ingénierie. Missionné pour révolutionner cette petite mairie, vous avez un plan clair : alléger le travail de Josiane, vous proposez de mettre en place une solution innovante qui repose sur deux piliers :
Une base de données vectorielle : Une bibliothèque numérique qui stocke les informations locales sous forme de vecteurs mathématiques. Ces vecteurs facilitent une recherche rapide et précise.
Un Large Language Model (LLM) : Un modèle intelligent qui interprète les questions en langage naturel et fournit des réponses adaptées, comme un assistant humain compétent.
Qu’est-ce qu’un LLM ?
Un LLM est un programme conçu pour comprendre et générer du texte humain. Imaginez un étudiant ayant lu des millions de livres et articles. Grâce à son apprentissage, il peut répondre à des questions ou rédiger des textes avec une précision impressionnante.
Mais je préfère vous montrer un exemple d’utilisation rapide :
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
# Déterminer l'appareil à utiliser (GPU si disponible)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# Chargement du modèle
model_name = "Qwen/Qwen2.5-1.5B"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name).to(device)
# Preprocessing de l’input utilisateur
question = "Quel est la capitale de la France ?"
inputs = tokenizer(question, return_tensors="pt", padding=True, truncation=True)
inputs = {key: value.to(device) for key, value in inputs.items()}
# Prédiction du modèle
with torch.no_grad():
output = model.generate(inputs["input_ids"],
attention_mask=inputs["attention_mask"],
max_new_tokens=50,
num_return_sequences=1)
response = tokenizer.decode(output[0], skip_special_tokens=True)
print("Question :", question)
print("Réponse :", response)Quel est ce programme que nous venons d’utiliser ? Schématiquement, nous pouvons simplement traduire l’opération effectuée comme cela :
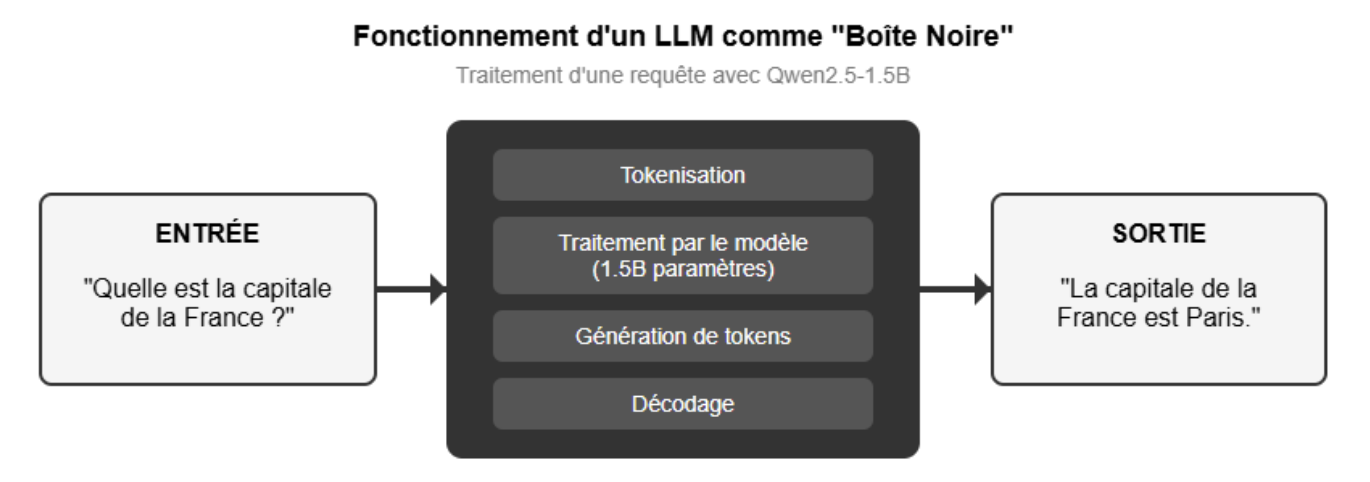
Regardons comment fonctionne ce que nous pouvons qualifier pour le moment de “boite noire”.
Imaginez un assistant invisible capable de répondre instantanément à toutes les questions, sans devoir chercher dans des classeurs ni passer des appels. Cet assistant "sait" déjà tout ce qu’il faut savoir. C’est précisément ce que font les LLM ,dèles de langage à grande échelle. Conçus pour comprendre et générer du texte avec une précision impressionnante, ces modèles utilisent des milliards de paramètres pour traiter des informations complexes. Un LLM fonctionne comme un expert du langage. Lorsqu’il lit une phrase, il anticipe chaque mot suivant et assemble des réponses cohérentes et pertinentes.
Le cœur d’un LLM : les paramètres et les données
Les LLM peuvent répondre à une grande variété de questions grâce à deux éléments fondamentaux : les paramètres et les données.
Les paramètres agissent comme des boutons ajustables qui modulent les capacités du modèle. Plus un LLM dispose de paramètres, plus il peut interpréter des nuances et des relations complexes entre les mots. Un modèle avec peu de paramètres pourrait simplement indiquer que "Paris est une ville en France", tandis qu’un modèle plus sophistiqué pourrait aussi intégrer des informations sur l’histoire, la culture ou la géographie de Paris.
Les données jouent un rôle tout aussi crucial. Les LLM sont entraînés sur d’immenses quantités de texte provenant de sources variées : articles scientifiques, livres, discussions en ligne, etc. Grâce à cet entraînement, le modèle apprend à reconnaître les relations et significations derrière les mots, comme s’il avait lu toutes les encyclopédies et même des lettres personnelles ou des recettes de cuisine.
Qu’est-ce qui se passe exactement lorsque je pose une question à un LLM ?
Voici ce qui se passe :
Déchiffrer la question
Le modèle commence par « lire » le texte de la question de manière séquentielle, un peu comme un humain qui suit une recette. Il décompose la phrase en unités élémentaires (appelées tokens) et repère les liens entre eux. Par exemple, associer « documents » et « mariage » permet de situer le contexte dans le domaine administratif. Cette étape permet au modèle de déterminer le type de réponse attendu (liste, explication, etc.).Activation de la mémoire statistique
Plutôt que de consulter une base de données, le LLM fait appel à une mémoire statistique acquise lors de son entraînement sur d’innombrables textes. Pour une question telle que « Quels documents pour un mariage ? », il active des schémas habituels : la pièce d’identité est souvent demandée, l’acte de naissance est associé à l’état civil, etc.…Génération incrémentale de la réponse
La réponse se construit mot par mot, de façon progressive, en anticipant à chaque étape la suite la plus probable.
Première étape : Le modèle commence par générer une amorce, par exemple « Vous avez besoin d’une… ». À ce stade, il évalue plusieurs suites possibles (comme « pièce d’identité », « photo » ou « autorisation »).
Étape suivante : À partir de l’amorce complétée (« Vous avez besoin d’une pièce d’identité, d’un… »), il prédit le mot le plus cohérent dans le contexte (par exemple « justificatif de domicile », « certificat », etc.).
Ce processus se répète jusqu’à ce que la réponse soit complète ou qu’une limite technique soit atteinte.
Filtrage et ajustement en temps réel
En parallèle, des mécanismes de filtrage interviennent pour éviter la production de réponses incohérentes ou inappropriées. Par exemple, si la probabilité de générer une suite hors contexte (comme « un bouquet de fleurs ») est très faible, cette option sera exclue.
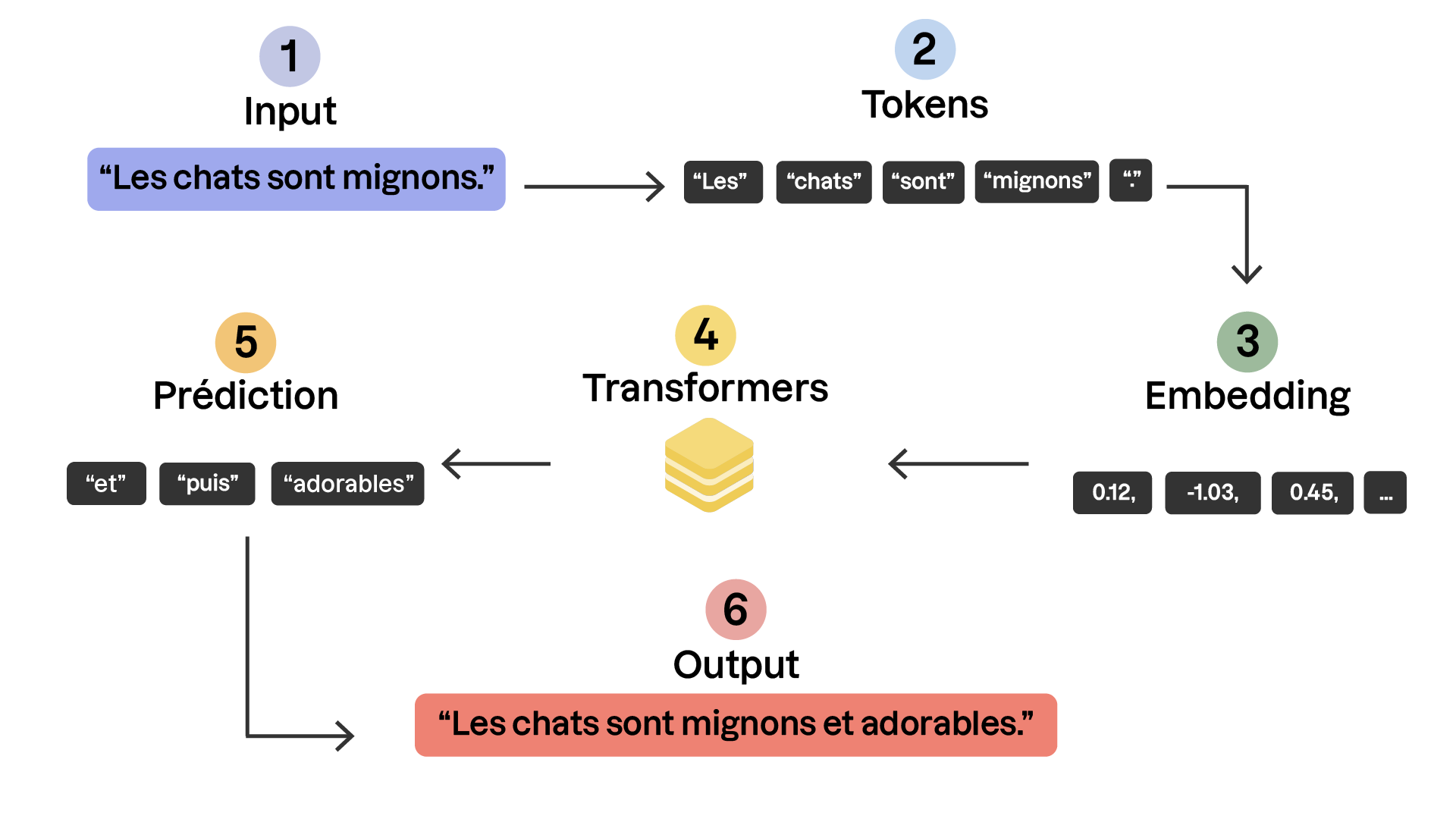
Pourquoi un LLM utilise des tokens ?
Les modèles de langage utilisent des tokens parce qu'ils ne traitent pas directement le texte comme les humains. Contrairement à nous, qui comprenons les phrases globalement, un LLM doit convertir le langage en une représentation numérique qu'il peut manipuler. La tokenisation permet cette conversion en divisant le texte en unités plus petites (tokens), qui sont ensuite transformées en nombres et traitées par le modèle.
Cette approche présente plusieurs avantages :
Plutôt que de stocker chaque mot de la langue, les LLM utilisent un ensemble limité de tokens, permettant de gérer des langues variées et des mots inconnus.
Travailler avec des tokens permet d’améliorer l’efficacité du modèle en limitant la quantité d’informations à traiter.
En divisant les mots en sous-unités (comme "biblio" et "thèque"), un LLM peut reconnaître et comprendre des mots qu’il n’a jamais vus auparavant.
Comment un LLM utilise des tokens ?
Plusieurs étapes se succèdent lorsque nous exécutons un LLM :
Lorsqu’un texte est soumis au modèle, il est d'abord découpé en tokens. Un token peut être un mot entier, une partie de mot ou même un caractère selon la méthode de tokenisation utilisée.
Chaque token est transformé en un identifiant unique dans un vocabulaire préétabli. Par exemple, le mot "chat" pourrait correspondre au numéro 3456.
Ces séquences de nombres sont ensuite analysées par le LLM, qui détecte les relations entre les tokens grâce à des mécanismes comme les réseaux de neurones et l’attention (Transformer).
Lorsque le modèle génère une réponse, il prédit le prochain token dans la séquence et continue ainsi jusqu’à atteindre une longueur définie.
Enfin, la séquence de tokens est reconvertie en texte lisible par un processus inverse de tokenisation.
Un autre défi concerne leur capacité à gérer un contexte limité : si une question dépasse la taille maximale de la fenêtre de contexte, des informations importantes risquent d’être ignorées. Pour pallier ces limites, il est essentiel de tester, ajuster et surveiller continuellement ces modèles.
En résumé, les LLM fonctionnent comme des assistants ultra-rapides et infatigables. Ils analysent les mots, prédisent les réponses mot à mot et s’appuient sur une immense base de connaissances. Cependant, ils restent perfectibles et nécessitent une supervision attentive.
C’est un peu comme une Josiane numérique, capable de fournir des réponses précises en un instant, mais qui peut aussi parfois se tromper ou avoir besoin d’une révision.
Comprenez le fonctionnement d'un LLM
Les LLM sont construits sur des réseaux neuronaux artificiels, qui s'inspirent du fonctionnement du cerveau humain. Ces réseaux sont composés de couches de neurones interconnectés. Chaque connexion entre les neurones a un poids associé. Ces poids sont ajustés lors de l'entraînement pour permettre au réseau d'apprendre à reconnaître des motifs dans les données. Les réseaux utilisés pour les LLM sont particulièrement grands et complexes, avec des milliards de paramètres (les poids des connexions).
Prenons la phrase : « Le trou sur la D42, signalé par le fermier Dupont, sera réparé vendredi. »
Le mécanisme d’attention détecte que :
« trou » est lié à « D42 » (lieu) et « réparé » (action).
« vendredi » dépend de « signalé » (délai après la notification).
Cette analyse contextuelle permet des réponses précises, comme : « Les travaux débuteront le [date] selon le service technique. »
Avant de pouvoir réaliser ces opérations, le réseau doit apprendre sur de larges ensembles de données.
Deux phases clés : Entraînement et inférence
L’entraînement : Phase intensive où le modèle ingurgite des téraoctets de textes. Pendant des semaines, il ajuste ses paramètres pour deviner le mot manquant dans des phrases.
L’inférence : Phase d’utilisation quotidienne. Quand Josiane tape une question, le LLM active ses paramètres figés pour générer une réponse. C’est comme un pianiste jouant une partition apprise – rapide, mais sans capacité d’improvisation nouvelle.
Cependant, l'entraînement de ces modèles est extrêmement coûteux en termes de ressources de calcul et de données. De plus, leurs connaissances sont figées à la date de leur entraînement, ce qui signifie qu’ils ne peuvent pas accéder à des informations récentes sans un enrichissement supplémentaire. Malgré ces limitations, les LLM possèdent des propriétés émergentes remarquables, telles que la réponse à des questions, la synthèse de textes ou encore la traduction automatique.
L’architecture transformers
Les Transformers reposent sur un mécanisme central : l’attention. Contrairement aux approches séquentielles qui traitent les mots un par un, l'attention permet au modèle d'examiner simultanément l'ensemble d'une séquence de texte. Chaque mot peut ainsi "regarder" tous les autres mots de la phrase pour identifier ceux qui sont les plus pertinents. Cette capacité à évaluer toutes les relations possibles entre les mots améliore considérablement la compréhension du contexte.
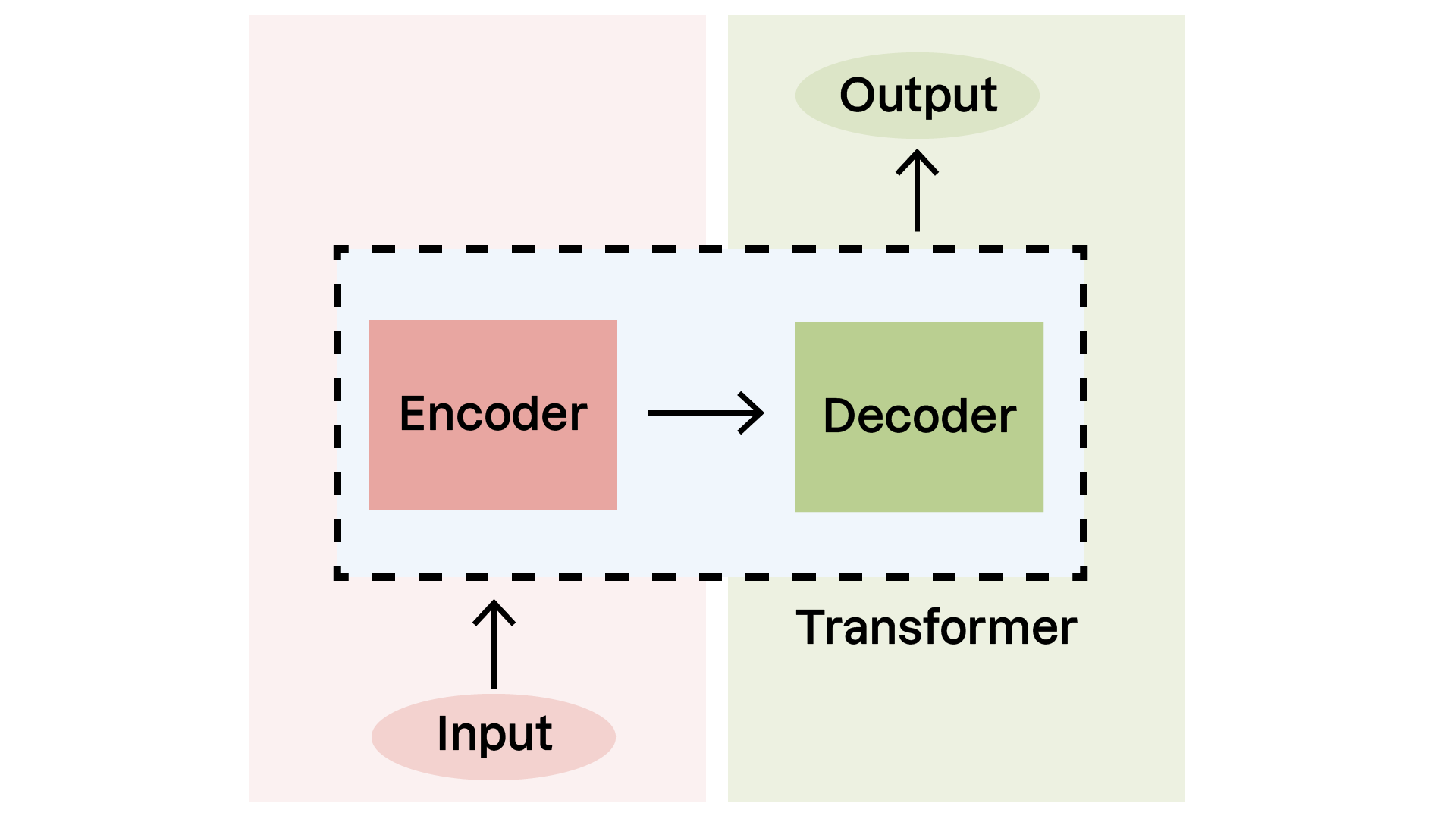
Les Transformers se composent de deux parties principales :
L'encodeur : qui traite le texte d'entrée.
Le décodeur : qui génère le texte de sortie.
Les modèles comme ceux de la famille GPT utilisent uniquement la partie décodeur pour produire des textes.
Le mécanisme d'attention fonctionne en trois étapes principales :
Calcul des requêtes, clés et valeurs : Pour chaque mot dans une séquence, le modèle crée trois représentations vectorielles :
Q (Query/Requête) : Ce que le mot "cherche" dans la séquence
K (Key/Clé) : Ce qui permet d'identifier le mot
V (Value/Valeur) : L'information réelle que le mot contient
Calcul des scores d'attention : Pour chaque position dans la séquence, le modèle calcule des scores indiquant à quel point chaque mot devrait "prêter attention" aux autres mots :
Il calcule le produit scalaire entre la requête (Q) du mot actuel et les clés (K) de tous les mots
Ces scores sont normalisés par une opération softmax pour obtenir des poids d'attention
Cette approche permet au modèle de donner plus d'importance à certains mots selon le contexte. Par exemple, dans la phrase "L'homme qui a acheté une voiture rouge l'a garée", le mécanisme d'attention permet au modèle de comprendre que "l'" fait référence à "voiture" plutôt qu'à "homme" en captant les relations entre ces mots.
Dans l'architecture complète, ce mécanisme d'attention est appliqué plusieurs fois en parallèle (attention multi-têtes) et à différentes couches, permettant au modèle de capturer des relations de plus en plus complexes entre les mots.
Les Transformers ont transformé le NLP pour plusieurs raisons majeures :
Parallélisation et efficacité
Contrairement aux modèles séquentiels tels que les réseaux de neurones récurrents (RNN) ou les LSTM, les Transformers traitent l'ensemble de la séquence simultanément. Cela permet une parallélisation efficace pendant l'entraînement, réduisant drastiquement le temps de calcul et rendant possible l'utilisation de jeux de données de très grande taille.Gestion des dépendances à longue distance
Le mécanisme d'attention permet de capturer les relations complexes entre des mots éloignés dans une phrase. Alors que les modèles séquentiels peinent à conserver des informations sur de longues distances, les Transformers évaluent directement l'importance de chaque mot par rapport à tous les autres, améliorant ainsi la compréhension contextuelle.Scalabilité et performances accrues
Cette architecture modulable a permis de développer des modèles de plus en plus volumineux (comme GPT, BERT, etc.), capables de traiter des tâches variées avec une précision remarquable, allant de la traduction automatique au résumé de textes. La capacité à intégrer des contextes étendus et à s'adapter à des problématiques diverses a ouvert la voie à une nouvelle génération d'applications en NLP.
Adaptez votre LLM à votre cas d’usage
Pour adapter un Large Language Model (LLM) aux besoins spécifiques de la mairie de Trifouillis-sur-Loire, il est essentiel d’explorer plusieurs approches afin d’optimiser à la fois la pertinence et l’efficacité des réponses. Le prompt engineering et le fine-tuning sont deux techniques classiques pour personnaliser les modèles de langage. Toutefois, leurs limites respectives — une efficacité parfois insuffisante pour le prompting et des coûts (ainsi qu’une rigidité) élevés pour le fine-tuning — nous poussent à considérer une alternative complémentaire : le RAG (Retrieval-Augmented Generation).
Concevez des instructions adaptées avec le Prompt Engineering
Le prompt engineering consiste à formuler et optimiser les instructions textuelles fournies au LLM. Bien conçues, ces instructions permettent d’obtenir des réponses pertinentes sans modifier le modèle lui-même. Cette méthode s’avère particulièrement utile dans un contexte municipal, où les questions des citoyens varient énormément.
Qu'est-ce qu'un prompt ?
Un prompt est une instruction ou une question donnée au LLM. La qualité du prompt influence directement la pertinence et la précision de la réponse. Par exemple :
Prompt général : "Quels documents sont nécessaires pour un mariage ?"
Prompt contextuel et précis : "Quels documents sont nécessaires pour un mariage civil à Trifouillis-sur-Loire ?"
Voici quelques Principes clés pour un prompt efficace :
1. Précision :
Utilisez des termes spécifiques.
Exemple : "Donnez la liste des documents obligatoires pour un mariage civil en France."
2. Contexte :
Ajoutez des détails pour ancrer la réponse dans une situation locale.
Exemple : "Pour un mariage civil dans une petite mairie française comme Trifouillis-sur-Loire, quels documents sont requis ?"
3. Actionnabilité :
Structurez le prompt de manière à inciter le modèle à une réponse claire.
Exemple : "Énumérez les étapes à suivre pour une déclaration de naissance à la mairie."
4. Itération :
Testez différentes formulations pour trouver la plus performante.
Bien que cette méthode soit rapide et n'exige pas de modification du modèle, elle présente des limitations notables, notamment en ce qui concerne l'accès aux informations métiers et privées de la mairie. En effet, le modèle ne peut pas puiser dans ces données internes, ce qui limite sa capacité à fournir des réponses véritablement contextualisées.
Adaptez le LLM aux spécificités locales avec le Fine-Tuning
Le fine-tuning consiste à réentraîner un LLM pré-entraîné sur des données spécifiques pour qu’il puisse répondre de manière plus pertinente à des besoins particuliers. Cela peut inclure des procédures administratives, des informations locales ou des réglementations propres à une mairie.
Pourquoi le fine-tuning pourrait-il être pertinent pour une mairie ?
Naïvement, nous pourrions penser que cela serait utile pour 2 raisons :
Spécialisation locale : Les LLM généralistes manquent souvent de données sur des réglementations locales.
Amélioration du style et du ton : Le fine-tuning peut aider à personnaliser le modèle pour qu’il adopte un style administratif formel et courtois, comme attendu dans le contexte d’une mairie.
Pour exemple :
Avant fine-tuning : "Quels documents pour un mariage ?" (Réponse générique, parfois incorrecte).
Après fine-tuning : "À Trifouillis-sur-Loire, vous devez fournir une pièce d’identité, un justificatif de domicile de moins de 3 mois et une copie intégrale de l’acte de naissance."
Comprenez l’utilité d’un RAG
Face aux limitations du prompt engineering et du fine-tuning, nous avons opté pour une approche hybride basée sur le RAG (Retrieval-Augmented Generation). Cette méthode combine la capacité générative d’un LLM avec l’accès en temps réel à une base de connaissances externe pour fournir des réponses enrichies et pertinentes.
Récupération : recherche de données pertinentes
Augmentée : ajout des données comme contexte à l'invite
Génération : utilisation de l'invite augmentée avec un LLM pour générer du contenu
Voici les étapes clés de son fonctionnement :
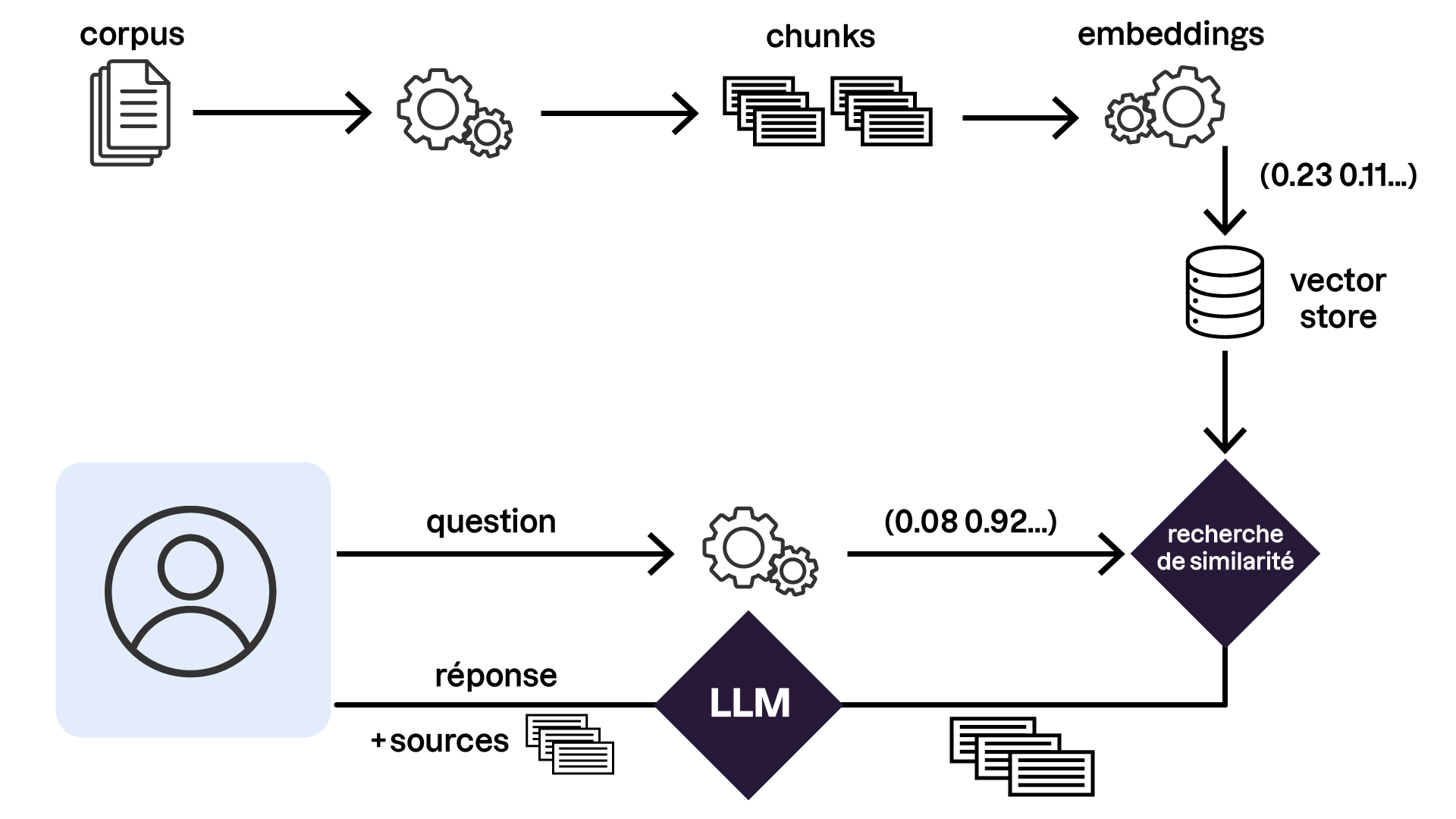
Ce workflow peut être lu selon ces 5 étapes principales :
Corpus : Collecte des documents textuels ou sources d'information à analyser.
Découpage (chunks) : Fragmentation des documents en unités plus petites (chunks) pour une gestion et une analyse plus efficaces.
Vectorisation : Conversion des chunks en vecteurs numériques, qui sont des représentations mathématiques du contenu dans un espace multidimensionnel.
Indexation : Organisation des vecteurs dans une base vectorielle pour faciliter la recherche et l'accès rapide aux informations pertinentes.
Requête de la base vectorielle : Interrogation de la base vectorielle pour identifier les documents les plus pertinents par rapport à une question ou un besoin.
En résumé
Les LLM, grâce à leur entraînement sur d'immenses corpus textuels, peuvent générer des réponses cohérentes et simuler des interactions humaines.
Leurs connaissances restent figées à la date de leur pré-entraînement, les rendant incapables d’intégrer des informations postérieures.
Ces modèles peuvent manquer de pertinence face à des demandes spécifiques ou locales, limitant leur utilité dans des contextes précis.
Sans ajustements, ils risquent de produire des réponses générales ou incomplètes, inadéquates pour des tâches nécessitant une précision accrue.
Ces limitations structurent les besoins en solutions comme le RAG, détaillé dans ce cours.
Maintenant que vous en savez plus sur l’utilité d’un RAG, passons dans le chapitre suivant à la préparation des données.
