Les 3V du Big Data
Après tout, qu'est-ce qui distingue une application big data d'une application small data ?
On pourrait être tentés de penser qu'il suffit de faire grossir une infrastructure en ajoutant des processeurs, de la RAM et de l'espace disque pour qu'elle soit en mesure de résoudre des problèmes utilisant 10, 100 ou 1000 fois plus de données. Et dans une certaine mesure, c'est vrai : dans certains cas bien précis, les outils small data sont scalables, c'est à dire qu'il passent bien à l'échelle.
Cependant, le scaling, ou plutôt le passage à l'échelle, s'accompagne quasiment toujours d'une transformation des usages que l'on résume par les 3V du big data : Volume, Vélocité, Variété :
Le Volume des données générées nécessite de repenser la manière dont elles sont stockées.
La Vélocité à laquelle nous parviennent ces données implique de mettre en place des solutions de traitement en temps réel qui ne paralysent pas le reste de l'application.
Les données se présentent sous une grande Variété de formats : ces données peuvent être structurées (documents JSON), semi-structurées (fichiers de log) ou non structurées (textes, images). L'ingestion, l'analyse et la rétention de ces données prendront des formes différentes selon leur nature, ce qui implique de mettre en place des outils appropriés.
Vous l'aurez compris, les 3V nécessitent d'utiliser des outils assez spécifiques. Est-ce que cela signifie que des outils ont été créé exprès pour le Big Data ? Oui, il y en a quelques uns…
La Grande Galerie du Big Data
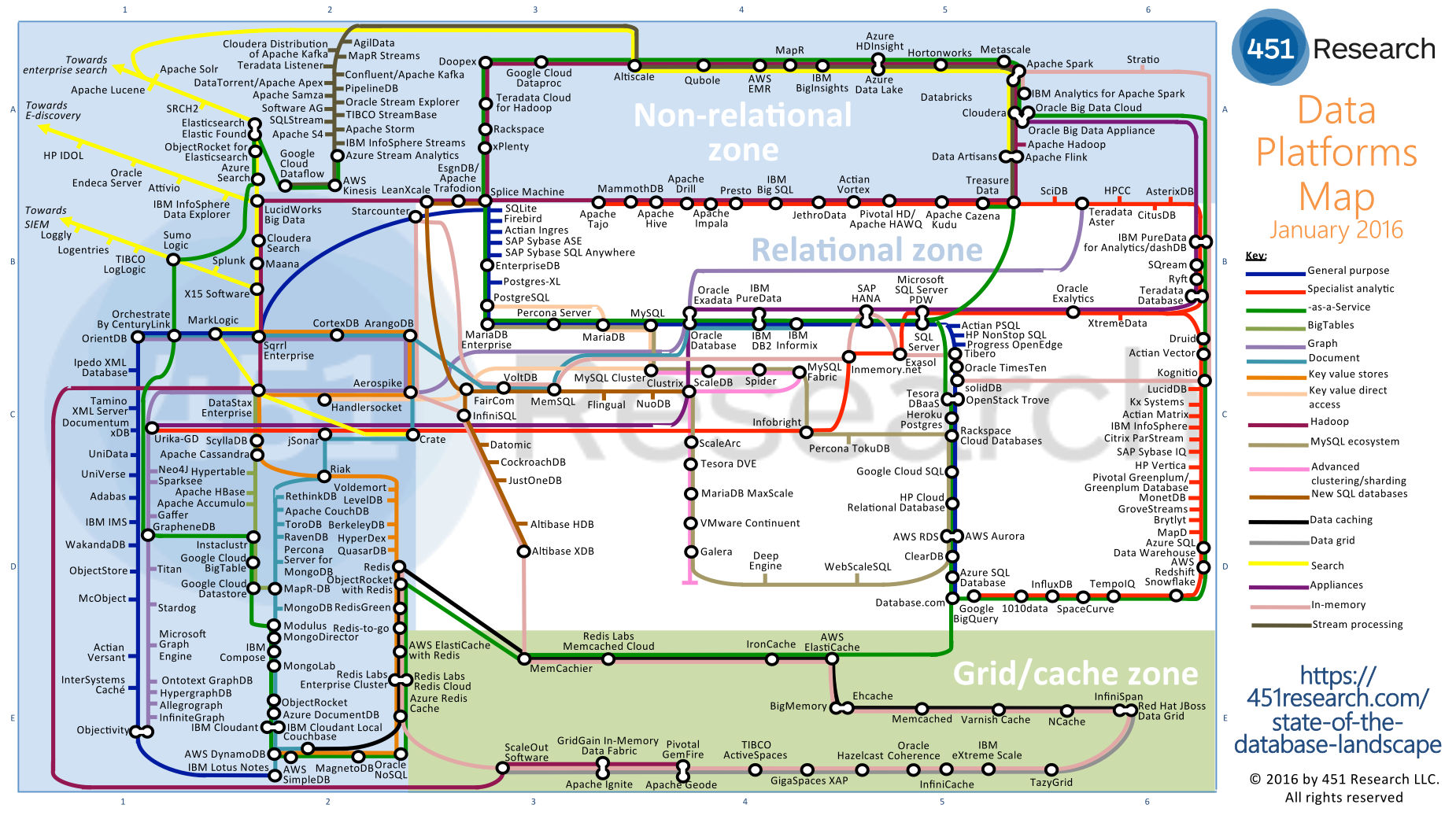
L'illustration ci-dessus (cliquez ici pour zoomer) est un plan élaboré à partir des différents outils qui ont été développés pour traiter du big data ; comme vous pouvez le voir, il y en a un nombre plutôt conséquent !
Les outils présentés sont organisés sous la forme d'un plan de métro dont les lignes se croisent ; un grand nombre d'outils appartiennent à plusieurs catégories à la fois et se trouvent donc sur plusieurs lignes différentes. Par exemple, un grand nombre d'outils de l'écosystème Hadoop (ligne violette) sont disponibles as-a-service (ligne verte), c'est-à-dire dans le cloud.
A voir cette carte, on peut se sentir débordé : il paraît complètement impossible d'apprendre à maîtriser ne serait-ce que le dixième de cette gigantesque boîte à outils ! Et rassurez-vous, ce n'est pas ce que nous espérons faire dans ce cours. ;)
Notons toutefois qu'il existe trois grandes zones :
La zone relationnelle qui fait référence aux technologies SQL
La zone non relationnelle qui fait référence aux technologies NoSQL
La zone Cache qui fait référence aux technologies de stockage des informations en mémoire vive
En seconde analyse, on se rend compte qu'un grand nombre de points sur ce plan sont extrêmement proches et appartiennent aux mêmes lignes : c'est donc qu'ils doivent avoir des fonctionnalités bien similaires…
On a vraiment besoin d'une telle pléthore d'outils, dont un grand nombre sont probablement redondants ?
Là non plus, ce n'est pas une question que nous allons trancher ici, mais elle nous permet de noter un point important : s'il est quasi-impossible de connaître tous les outils big data qui existent, il appartient aux Data Architects ou aux Data Engineer d'être capable d'identifier les différentes catégories d'outils qui existent, ainsi que les similitudes entre les solutions existantes.
La plupart des outils n'ont rien d'unique : tout ou partie de leurs fonctionnalités sont couvertes par d'autres.
C'est ce que nous allons voir dans le reste de ce cours, en l'occurence des outils qui permettent de réaliser des calculs distribués.
En résumé
La problématique du Big Data se pose souvent quand on parle de "scaler" une activité, c'est à dire multiplier la quantité de données par 100, 1000 ou 1000.
On référence souvent le Big Data sous les 3 V : Volume, Vitesse et Variété. On ajoute parfois Valeur ou Véracité
Les technologies utilisées pour faire du Big Data sont très nombreuses et très diverses. Il n'est pas possible de toutes les maitriser.
