Soyons réalistes : en pratique, quand vous développez une application, vous passez plus de temps à la déboguer qu'à la développer. Par définition, ce qui est facile se fait rapidement ! En tant que data architect, vous allez régulièrement recevoir des appels à l'aide de la part de vos développeurs : Pourquoi mon application plante-t-elle ? Pourquoi utilise-t-elle autant de mémoire ? Comment la rendre plus rapide ?
Votre rôle consistera à répondre à ces questions, à déterminer la cause du problème et, si possible, à proposer des solutions. Pour cela vous allez avoir besoin d'outils de diagnostic. Avec des applications distribuées, vous ne pouvez pas définir de point d'arrêt ni déboguer pas-à-pas, mais Spark vous fournit deux outils de débogage : tout d'abord, comme pour n'importe quelle application, vous disposez de fichiers de logs contenant divers messages d'erreurs, d'avertissements, ainsi qu'une stacktrace en cas d'échec. Ensuite, vous avez à disposition une interface graphique vous permettant de contrôler la progression d'une application.
Logging avec log4j
Le système de logs utilisé par Spark est celui de log4j et sa configuration se trouve dansconf/log4j.properties. Si vous n'avez pas déjà créé ce fichier, vous pouvez utiliser le template de configuration par défaut :
$ cd spark-2.3.1-bin-hadoop2.7/
$ cp conf/log4j.properties.template conf/log4j.propertiesComme mentionné plus tôt, par défaut Spark émet énormément de logs. Vous pouvez rendre Spark moins verbeux en augmentant le niveau de log affiché dans la console àWARN,ERROR, voireFATAL:
log4j.rootCategory=ERROR, consoleCe qui est également surprenant au premier abord, c'est que les logs de Spark sont émis dansstderr, même les logs qui ne sont pas des erreurs. Pour changer ce comportement, remplacezerrparoutdans la ligne de configuration suivante :
log4j.appender.console.target=System.errNotez cependant qu'il peut être utile de renvoyer les messages de votre application versstderr, puisque ça vous permettra de discerner facilement les appels àprintque vous aurez ajoutés à votre code.
Sachez aussi que vous pouvez ajuster les niveaux de log de chacune des classes. Il vous faudra alors préciser le nom complet de la classe Java. Par exemple, imaginons que vous vouliez être prévenu de la progression des tâches de votre application. Il s'agit des logs émis parExecutor, qui sont de la forme :
17/03/01 18:54:42 INFO Executor: Starting executor ID driver on host localhost
17/03/01 18:54:44 INFO Executor: Running task 0.0 in stage 0.0 (TID 0)
17/03/01 18:54:44 INFO Executor: Running task 1.0 in stage 0.0 (TID 1)
17/03/01 18:54:45 INFO Executor: Finished task 0.0 in stage 0.0 (TID 0). 2091 bytes result sent to driverPour cela, vous allez devoir trouver le chemin complet de la classeExecutor. La documentation de Spark est très pauvre à ce sujet, donc vous êtes livrés à vous-mêmes ! La solution consiste à lister le contenu de l'archivespark-core_2.11-2.3.1.jaret à y trouver la classeExecutor. Ça se fait en un coup de cuillère à pot grâce à notre amigrep:
$ jar -tf jars/spark-core_2.11-2.3.1.jar | grep "/Executor\\$"| tail -1
org/apache/spark/executor/Executor$$anonfun$org$apache$spark$executor$Executor$$updateDependencies$3.classLe nom que nous cherchons estorg.apache.spark.executor.Executor. Il suffit alors de modifier log4j.properties et d'augmenter le niveau de log de toutes les classes, sauf de la classeExecutor:
log4j.rootCategory=ERROR, console
log4j.logger.org.apache.spark.executor.Executor=INFOProfiling avec Spark Web UI
Lorsqu'une application Spark est en cours d'exécution, on dispose d'une interface graphique à partir de laquelle on peut suivre la progression de l'application : il s'agit de Spark Web UI. Lors de l'exécution d'une application en local, cette UI se trouve à l'adresse suivante : http://localhost:4040.
Notez que cette UI n'est disponible que lorsqu'une application est en cours d'exécution ! On voudrait pouvoir accéder aux informations fournies même après la fin de l'exécution de l'application. Pour cela, une petite astuce consiste à mettre l'application en pause après que toutes les actions ont été réalisées. Pour cela, je rajoute à la fin de mon application la ligne de code suivante :
input("press ctrl+c to exit")Spark Web UI va nous permettre de réaliser un profilage de nos application, et donc de détecter les goulots d'étranglements. Les règles cardinales habituelles du profilage s'appliquent comme pour les applications non distribuées :
Cherchez en priorité à accélérer les sections du code qui ont le plus gros potentiel : en d'autres termes, il ne sert pas à grand-chose de chercher à diminuer le temps passé dans une fonction qui n'occupe que 10% du temps de l'application.
Mesurez tout ! Il ne faut jamais réaliser plusieurs optimisations à la fois, au risque de voir les bénéfices de l'une annulés par les pertes de l'autre.
Dans ce chapitre nous allons nous intéresser à la progression de l'intrigue entre l'Iliade et l'Odyssée, les deux bestsellers d'Homère. Pour cela, nous allons examiner l'évolution de la fréquence des termes entre les deux épisodes. Logiquement, les termes qui voient leur fréquence augmenter dans la sequel indiquent les nouveaux éléments narratifs tandis que ceux qui ont disparu voient leur fréquence diminuer.
Nous allons présenter une première version de notre application dont nous allons réaliser le profilage à l'aide de Spark Web UI. Ce profilage nous permettra d'accélérer notre application, et la version améliorée sera fournie à la fin de ce chapitre.
Commençons par télécharger les textes de l'Iliade et l'Odyssée :
$ cd code/
$ wget http://classics.mit.edu/Homer/iliad.mb.txt
$ wget http://classics.mit.edu/Homer/odyssey.mb.txtVoici le code de notre application (avant optimisation) que vous pouvez stocker danscode/iliad_odyssey.py:
from pyspark import SparkContext
sc = SparkContext()
def filter_stop_words(word):
from nltk.corpus import stopwords
english_stop_words = stopwords.words("english")
return word not in english_stop_words
def load_text(text_path):
# Split text in words
# Remove empty word artefacts
# Remove stop words ('I', 'you', 'a', 'the', ...)
vocabulary = sc.textFile(text_path)\
.flatMap(lambda lines: lines.lower().split())\
.flatMap(lambda word: word.split("."))\
.flatMap(lambda word: word.split(","))\
.flatMap(lambda word: word.split("!"))\
.flatMap(lambda word: word.split("?"))\
.flatMap(lambda word: word.split("'"))\
.flatMap(lambda word: word.split("\""))\
.filter(lambda word: word is not None and len(word) > 0)\
.filter(filter_stop_words)
# Count the total number of words in the text
word_count = vocabulary.count()
# Compute the frequency of each word: frequency = #appearances/#word_count
word_freq = vocabulary.map(lambda word: (word, 1))\
.reduceByKey(lambda count1, count2: count1 + count2)\
.map(lambda (word, count): (word, count/float(word_count)))\
return word_freq
def main():
iliad = load_text('./iliad.mb.txt')
odyssey = load_text('./odyssey.mb.txt')
# Join the two datasets and compute the difference in frequency
# Note that we need to write (freq or 0) because some words do not appear
# in one of the two books. Thus, some frequencies are equal to None after
# the full outer join.
join_words = iliad.fullOuterJoin(odyssey)\
.map(lambda (word, (freq1, freq2)): (word, (freq2 or 0) - (freq1 or 0)))
# 10 words that get a boost in frequency in the sequel
emerging_words = join_words.takeOrdered(10, lambda (word, freq_diff): -freq_diff)
# 10 words that get a decrease in frequency in the sequel
disappearing_words = join_words.takeOrdered(10, lambda (word, freq_diff): freq_diff)
# Print results
for word, freq_diff in emerging_words:
print("%.2f" % (freq_diff*10000), word)
for word, freq_diff in disappearing_words[::-1]:
print("%.2f" % (freq_diff*10000), word)
input("press ctrl+c to exit")
if __name__ == "__main__":
main()Notez que vous aurez besoin d'installer le packagenltkpour exécuter cette application, et vous devrez également télécharger les listes de "stopwords". Pour cela, exécutez :
$ pip install nltk
$ python -c "import nltk; nltk.download('stopwords')Ce programme nous permet de visualiser les termes qui deviennent importants dans l'Odyssée, ainsi que ceux qui perdent en importance :
$ ./spark-2.3.1-bin-hadoop2.7/bin/spark-submit ./iliad_odyssey.py
92.52 ulysses
53.63 house
48.33 telemachus
43.06 suitors
36.68 tell
33.47 ship
33.35 one
31.94 home
26.73 said
25.97 got
-28.72 jove
-31.46 horses
-40.66 fight
-44.56 spear
-47.24 ships
-54.71 achilles
-61.74 achaeans
-65.52 hector
-72.71 trojans
-89.71 son
press ctrl+c to exitJe vous invite à lancer cette application et à réaliser son profilage en même temps que moi.
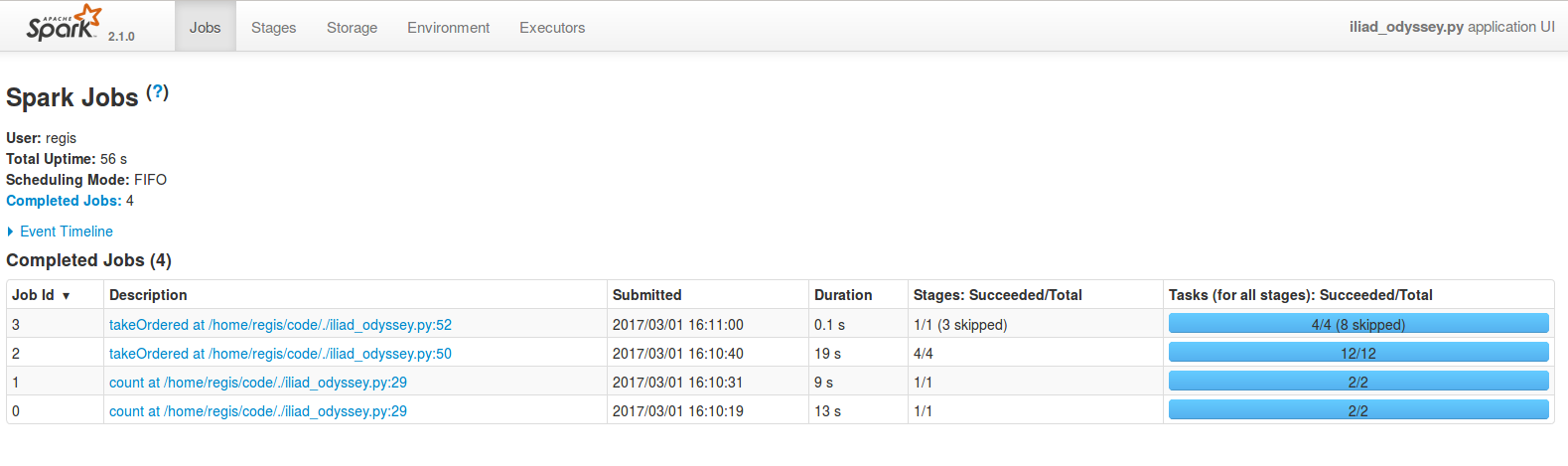
Au total, notre application met 41.1s à s'exécuter. Elle est constituée de quatre jobs, dont le temps d'exécution varie de 0.1 s à 19 s. Comme nous réalisons les mêmes opérations sur deux livres différents, les jobs 0 et 1, d'une part, et les jobs 2 et 3, d'autre part, suivent la même logique. Commençons par examiner le job le plus coûteux en temps, qui est le job 2 (19 s) :
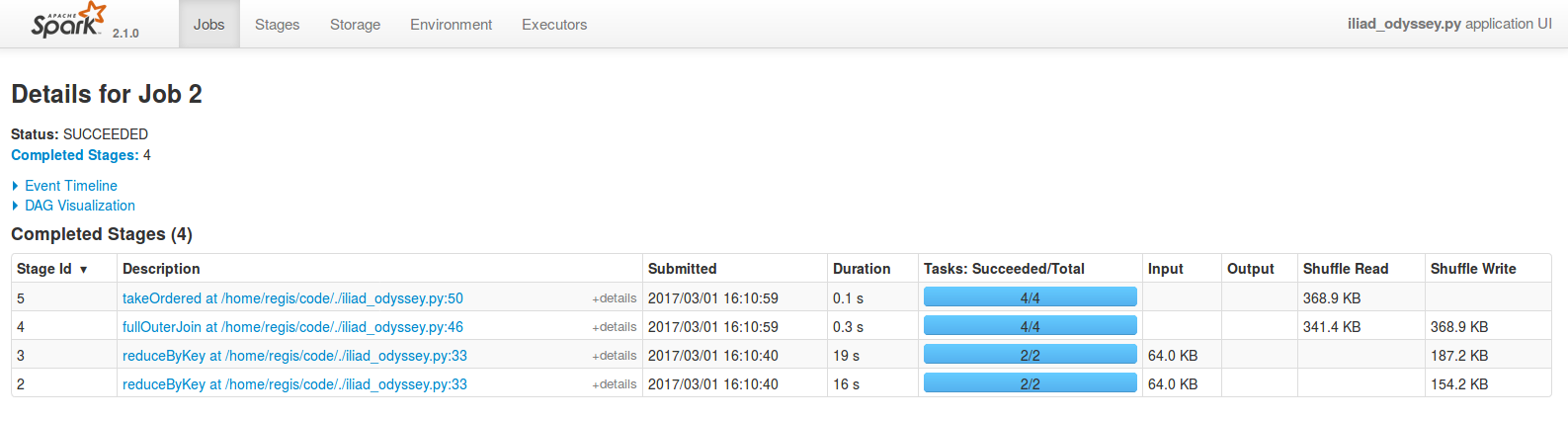
On peut voir que ce sont les étapes 2 et 3 qui prennent la quasi-totalité du temps ; or le DAG de l'étape 2 indique qu'elle comprend le chargement des fichiers textes, et donc également toutes les étapesmap,flatMapetfilterqui suivent l'appel àtextFile:
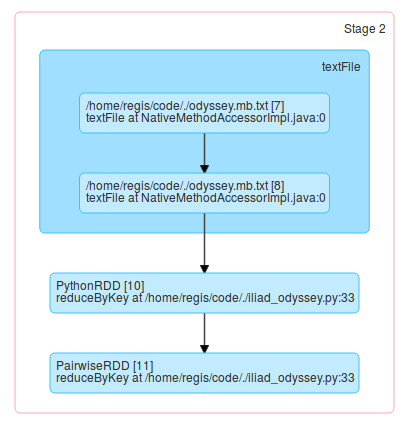
Or, on réalise déjà le chargement de ces données au cours des étapes 0 et 1 (des jobs 0 et 1). Devinez-vous ce qui se produit ? Les transformations suivantes sont réalisées deux fois :
vocabulary = sc.textFile(os.path.join(current_directory, text_name))\
.flatMap(lambda lines: lines.lower().split())\
.flatMap(lambda word: word.split("."))\
.flatMap(lambda word: word.split(","))\
.flatMap(lambda word: word.split("!"))\
.flatMap(lambda word: word.split("?"))\
.flatMap(lambda word: word.split("'"))\
.flatMap(lambda word: word.split("\""))\
.filter(lambda word: word is not None and len(word) > 0)\
.filter(filter_stop_words)Cela est dû au fait que nous réalisons deux actions à partir des mêmes données : on fait d'abord uncountpuis, plus loin, untakeOrdered. Comme on l'a dit dans le chapitre précédent, pour éviter de réaliser ces actions deux fois il faut faire un appel àpersist():
vocabulary = sc.textFile(os.path.join(current_directory, text_name))\
...
.filter(filter_stop_words)\
.persist()
# Count the total number of words in the text
word_count = vocabulary.count()Bingo ! Cette ligne de code fait passer le job 2 de 19 s à 0.8 s sans impacter significativement les autres jobs. Le point vert très discret dans le DAG du job indique la persistence des données :
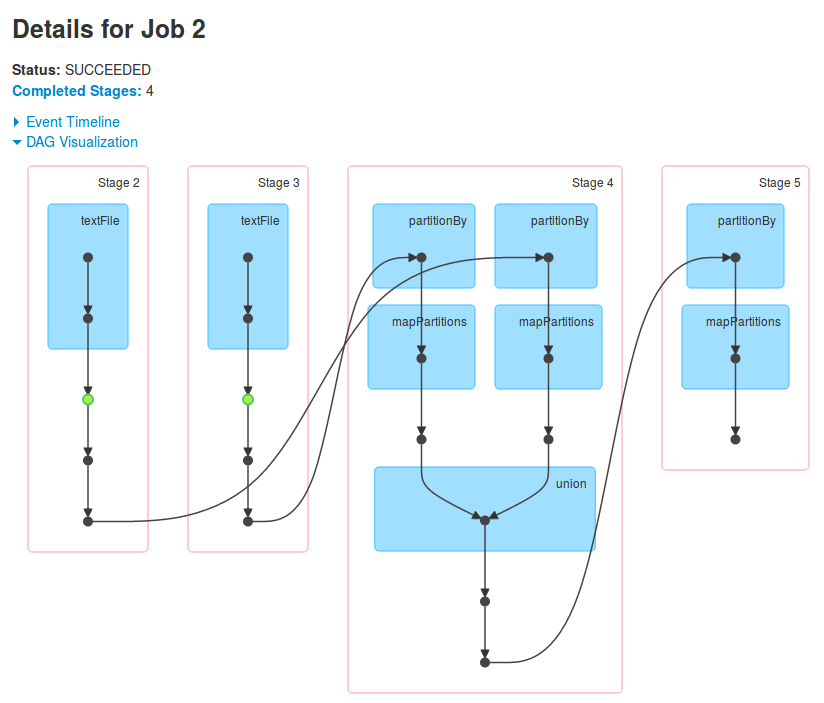
On pourrait être tentés de continuer sur notre lancée en stockant en cache le RDDword_freq:
word_freq.persist()En effet, nous faisons deux appels àtakeOrdered, ce qui constitue deux actions. On s'attend donc à ce queword_freqsoit évalué deux fois. Mais ce n'est pas le cas, et d'ailleurs le job 3, qui correspond au second appel àtakeOrderedest celui qui s'exécute le plus rapidement. Ce résultat est a priori surprenant. On peut le comprendre en consultant les étapes du job 3 :

On s'aperçoit que trois des quatre étapes du job 3 sont "skipped". Cela est dû au fait que certaines données générées par job 2 sont automatiquement stockées en cache. En réalité, ce stockage en cache s'effectue à chaqueshuffle. On peut tenter de stockerword_freqen cache, mais on s'apercevra alors que le temps nécessaire à la mise en cache nous fait perdre des performances, sans accélérer le job 3. (il faut tout mesurer je vous dis !)
Examinons maintenant le job 0 qui est désormais celui qui prend le plus de temps (12 s). La timeline de l'étape 0 (l'unique étape du job 0) nous indique que l'intégralité de ce temps est passée à réaliser des calculs :

Pour être franc, je sais que mon ordinateur date de 2013, mais j'ai un peu de mal à croire qu'il met douze secondes à compter les mots de l'Iliade... Examinons donc les opérations réalisées durant cette étape :
def filter_stop_words(word):
from nltk.corpus import stopwords
english_stop_words = stopwords.words("english")
return word not in english_stop_words
def load_text(text_path):
# Split text in words
# Remove empty word artefacts
# Remove stop words ('I', 'you', 'a', 'the', ...)
vocabulary = sc.textFile(text_path)\
.flatMap(lambda lines: lines.lower().split())\
.flatMap(lambda word: word.split("."))\
.flatMap(lambda word: word.split(","))\
.flatMap(lambda word: word.split("!"))\
.flatMap(lambda word: word.split("?"))\
.flatMap(lambda word: word.split("'"))\
.flatMap(lambda word: word.split("\""))\
.filter(lambda word: word is not None and len(word) > 0)Parvenez-vous à détecter l'opération qui est la plus coûteuse ? Si vous n'y arrivez pas, je vous suggère de les éliminer une par une jusqu'à ce que vous la trouviez. Mais je vais vendre la mèche, la ligne coupable est la suivante :
return word not in english_stop_wordsCette opération consiste à retirer des mots traités les stopwords ; les stopwords sont les mots qui sont systématiquement présents dans un texte et qui ne sont pas porteurs de sens, comme les pronoms personnels, les déterminants, etc. Dans cette ligne,english_stop_wordsest une liste de relativement grande taille — disons N. La complexité de cette recherche d'éléments est doncO(N). Pour accélérer cette étape, il faut convertir cette liste en une table de hâchage :
english_stop_words = set(stopwords.words("english"))L'opérationword not in english_stop_wordsdeviendra alors de complexitéO(1). Mais attention ! Il ne faut surtout pas réaliser cette opération lors de chacun des appels àfilter_stop_words, sinon on devra recréer la table de hâchage pour chacun des mots. Dans cet exemple on peut facilement sortir la conversion ensetde la fonction et traiterenglish_stop_wordscomme une variable globale. En pratique, vous n'aurez peut-être pas cette possibilité. La solution consiste alors à remplacer l'appel àfilter(ou àmap) par un appel àmapPartitions. Cela vous permettra de réaliser l'étape d'initialisation une seule fois par partition, plutôt qu'une fois par donnée :
def filter_stop_words(partition):
from nltk.corpus import stopwords
english_stop_words = set(stopwords.words("english"))
for word in partition:
if word not in english_stop_words:
yield word
...
vocabulary = sc.textFile(os.path.join(current_directory, text_name))\
...
.mapPartitions(filter_stop_words)\
.persist()Le job 0 passe ainsi de 12 s à 1 s \o/. Plutôt pas mal, non ?
Il reste une dernière optimisation que l'on peut réaliser, et elle touche à quelque chose que je vous ai un peu caché jusqu'à présent... Il est possible de contrôler le nombre de partitions d'une opération. Oui, je sais, c'est mal, j'aurais pu vous en parler avant, mais j'attendais le bon moment, vous comprenez ? Changer le nombre de partitions d'une opération est une optimisation assez délicate. Pour ceux du fond qui n'auraient pas révisé leur cours, une partition c'est un morceau des données sur lequel un (un seul !) executor va réaliser des opérations. Et un executor ne fonctionne pas en parallèle, mais en séquentiel. Donc, en gros, il faut ajuster le nombre de partitions au nombre de threads que vous pouvez exécuter de manière optimale sur votre processeur.
Or, le processeur de mon ordinateur supporte l'hyper-threading : il a deux cœurs physiques, mais se comporte comme s'il en avait quatre. Spark ajuste le nombre de partitions au nombre de cœurs alors qu'on pourrait doubler le nombre de partitions. Il faut donc que l'on définisse manuellement le nombre de partitions de nos données. Cela peut se faire à l'aide d'un argument optionnel que l'on peut passer à toutes les opérations de lecture de données et à toutes les transformations qui nécessitent un shuffle :
vocabulary = sc.textFile(os.path.join(current_directory, text_name), minPartitions=4)Ce faisant, le temps nécessaire à l'initialisation des partitions a légèrement augmenté, ce qui est visible dans la durée d'exécution du job 0, mais les autres jobs ont été sensiblement accélérés :
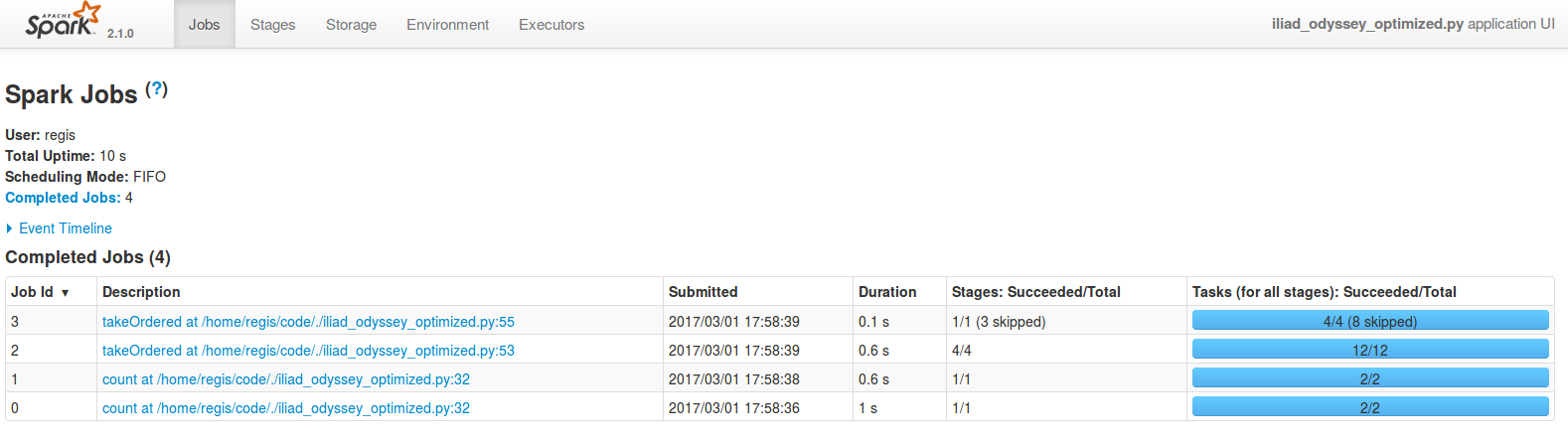
De la même manière, si votre application utilise trop de RAM, c'est probablement que le nombre de partitions est trop faible : comme une partition à la fois est traitée par un exécuteur, il faut baisser la taille de la partition pour utiliser moins de RAM. Et baisser la taille des partitions, cela signifie augmenter leur nombre.
Récapitulons les points à vérifier pour optimiser une application :
Stockez en cache les données quand c'est nécessaire
Utilisez les bonnes structures de données
Ajustez le nombre de partitions
