Dans le chapitre précédent, peut-être avez-vous rencontré des problèmes particuliers lors du lancement du cluster ou du lancement de votre application ? Si ce n'est pas le cas, ça ne saurait tarder ! Pas parce que les exemples dont nous avons parlé comportent des erreurs, mais parce que les bogues et les soucis opérationnels font partie du quotidien des informaticiens en général, et des data architects en particulier. Que faire lorsque votre application distribuée plante ou met trop de temps à s'exécuter ? Nous verrons dans ce chapitre trois outils pour vous permettre de résoudre ces problèmes : l'analyse des logs, la supervision des applications et le passage à l'échelle automatique de votre cluster.
Logging et débogage
Votre cluster de calcul émet des logs, beaucoup de logs même ! Avez-vous remarqué l'option--log-uride la commandecreate-cluster? Il s'agit du bucket et du préfixe des objets S3 qui vont contenir les logs du cluster. Un certain nombre de fichiers de logs sont créés ; nous n'allons pas tous les décrire, mais voici les plus importants :
elasticmapreduce
<CLUSTERID>
containers
application_APPLICATIONID
container_CONTAINERID
stderr.gz # Logs de fonctionnement de Spark
stdout.gz # Sortie standard de l'application
node
NODEID
applications # Logs des différents services
hadoop-hdfs
hadoop-mapreduce
hadoop-yarn
hadoop
spark
...
bootstrap-actions # Logs des actions d'amorçageIl est possible de visualiser ces logs à partir de la console AWS, mais il est beaucoup plus pratique de les récupérer et de les analyser en local :
$ mkdir logs
$ aws s3 sync s3://aws-logs-LOGBUCKET logs/
$ find logs/ -name "*.gz" -exec gunzip -k {} \;Notez que les logs sont stockés de manière compressée et que la dernière commande a pour but de décompresser ces logs.
Comme vous vous en souvenez peut-être, Spark est configuré pour émettre ses logs dansstderr, et non dans la sortie standard, ce qui explique que les logs de fonctionnement de votre application se retrouvent dans un fichierstderr. Par contre, si vous ajoutez des commandesprint(...)à vos applications, vous retrouverez la sortie de ces commandes dansstdout.gz, ce qui est bien pratique pour déboguer une application. Enfin, les actions d'amorçage aussi doivent bien souvent être déboguées ; vous disposez de leurs logs dans un répertoire dédié.
Cependant, il est bien peu pratique de chercher l'identifiant du cluster, de l'application et du container pour déboguer une application. AWS EMR met à notre disposition plusieurs outils de diagnostic d'Hadoop et de Spark auxquels on peut accéder via des interfaces web, dont deux qui sont particulièrement intéressants. Ces interfaces proviennent d'applications exécutées sur le nœud master du cluster et sont accessibles sur les ports suivants :
Gestionnaire de ressources Hadoop (port 8088) : il s'agit du point d'entrée par lequel on peut visualiser les différentes applications lancées sur le cluster ainsi que leurs logs.
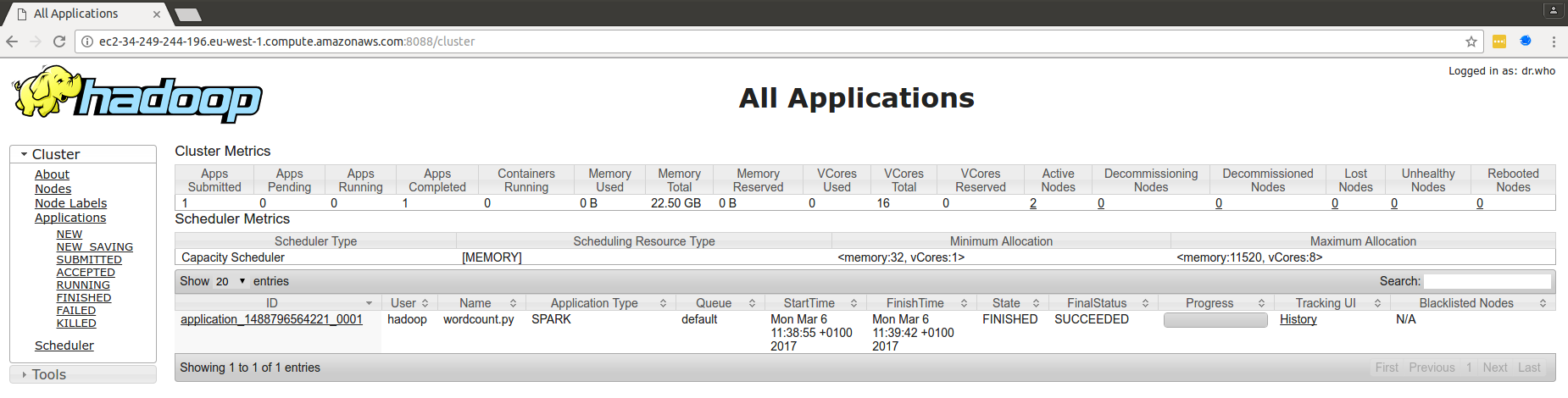
Spark History Server (port 18080) : il s'agit de Spark Web UI, que nous avons vu dans un chapitre précédent. Cependant, comme nous disposons dans nos clusters de calcul d'un gestionnaire de cluster YARN, l'historique d'exécution de nos applications est conservé. Il est donc possible de réaliser le profilage de nos applications même après la fin de leur exécution.
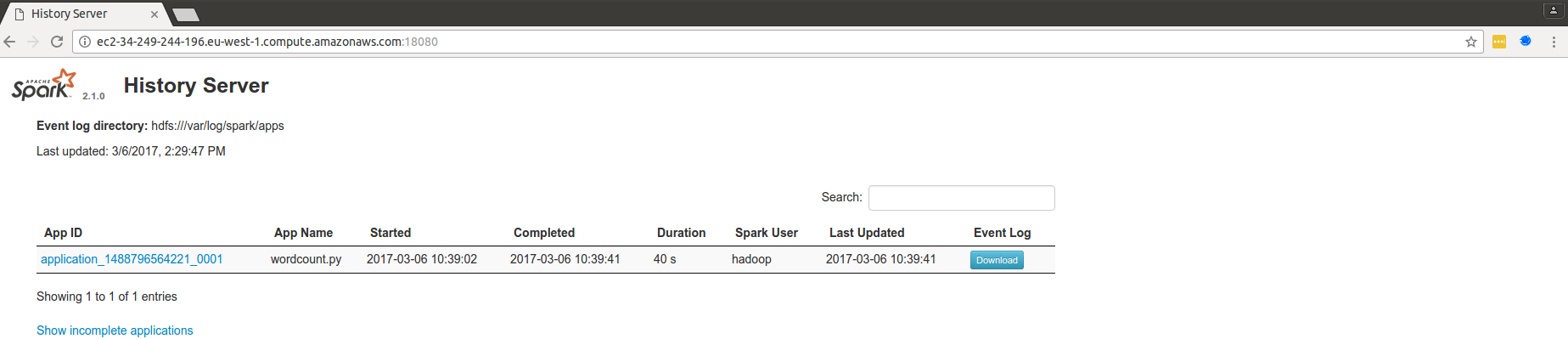
Ces applications sont accessibles à l'urlhttp://MASTERNODEURL:PORT. Par exemple, si le DNS public du nœud master de mon cluster estec2-34-249-244-196.eu-west-1.compute.amazonaws.comalors l'interface du gestionnaire de ressources Hadoop est visible à l'urlhttp://ec2-34-249-244-196.eu-west-1.compute.amazonaws.com:8088. Le problème est que cette url n'est disponible qu'à partir du réseau local du cluster, et nous ne sommes pas dans le réseau local du cluster, sauf si vous êtes ingénieur chez Amazon (et encore). Pour y accéder, il va falloir ruser !
Nous allons réaliser un tunnel SSH vers le nœud maître de notre cluster. Commencez par vous y connecter en SSH, comme nous l'avons vu dans la partie précédente, mais en ajoutant l'option-D 5555à votre commande. Par exemple :
ssh -D 5555 hadoop@ec2-34-249-244-196.eu-west-1.compute.amazonaws.comUne fois la connexion établie, le tunnel SSH a été créé. Il reste à demander à votre navigateur de l'emprunter. Je vous suggère d'installer l'extension FoxyProxy dans votre navigateur (disponible sous Firefox et Chrome) et d'ajouter un proxy à l'adresselocalhost:5555(voir ci-dessous la capture d'écran de la configuration du proxy). N'oubliez pas de cocher l'optionSOCKS proxy.
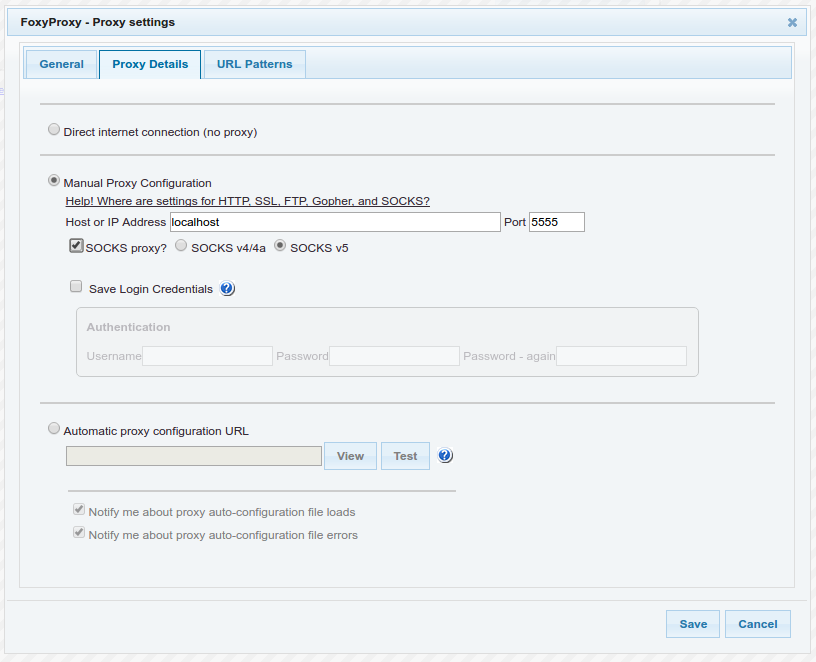
Activez ensuite le proxy que vous venez de créer ("Use proxy localhost:5555 for all URLs"). Et voilà le travail ! Du point de vue du monde extérieur, vous naviguez maintenant sur le web à partir d'une adresse IP qui est celle du serveur auquel vous vous êtes connectés en SSH. Vous devriez donc pouvoir accéder aux interfaces de gestion de votre cluster via votre navigateur. Notez que dans la console AWS de votre cluster, vous disposez alors d'un lien direct vers ces interfaces :

Sans tunnel SSH...

... avec tunnel SSH
Vous pouvez ouvrir les ports 8088 et 18080 du nœud master à partir des groupes de sécurité EC2, mais alors le monde entier aura accès aux interfaces de gestion de votre cluster, ce qui pose des problèmes de sécurité majeurs. Donc ne le faites pas !
Supervision
Les logs de votre application permettent de détecter les erreurs de programmation qui provoquent des comportements inattendus, mais ne permettent pas de mesurer les performances de votre cluster. AWS met à votre disposition plusieurs outils pour contrôler l'usage en terme de CPU, de RAM, Input/Output. Nous n'allons pas rentrer dans le détail des fonctionnalités de ces outils de supervision, qui dépassent le cadre de ce cours, mais simplement mentionner quelques sources d'information dont vous pouvez partir pour analyser le comportement de vos clusters.
Cloudwatch : il s'agit de l'outil de supervision fourni par AWS et permet d'accéder à un nombre de métriques tout à fait considérable. Les métriques Cloudwatch ne sont rafraîchies que toutes les cinq minutes, il s'agit donc d'un outil de supervision sur le long terme. À titre d'exemple, voici un tableau de bord des applications executées sur le cluster.
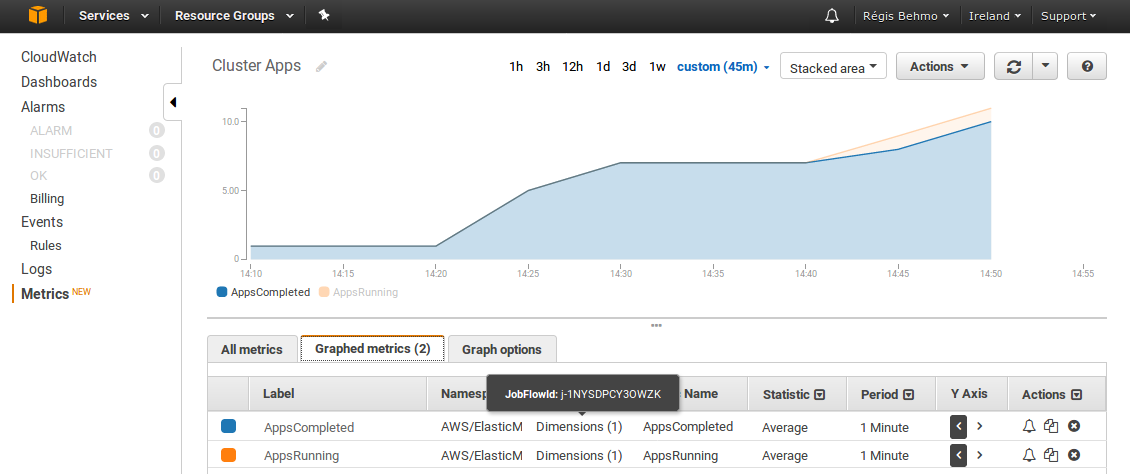
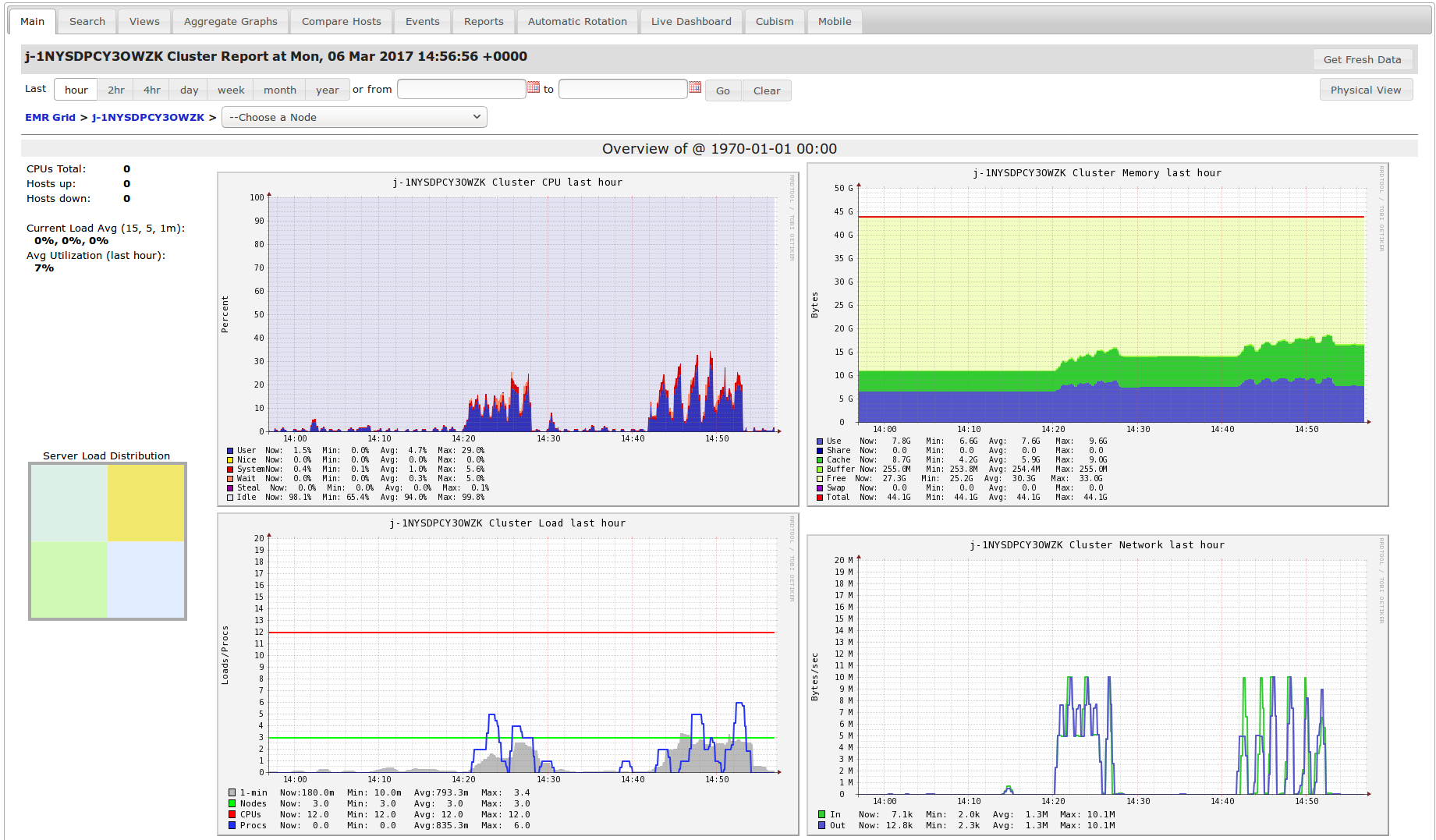
Ganglia : accessible à l'url
/gangliade votre nœud master, il s'agit également d'un outil de mesure de la charge du cluster. Cependant, le pas d'échantillonnage est plus fin que celui de Cloudwatch, ce qui permet de réaliser des analyses en temps réel.
Passage à l'échelle automatique
Un des premiers bénéfices du cloud, comme nous l'avons déjà mentionné, et de permettre de s'adapter à une variation de charge soudaine : que faire si le besoin en CPU augmente brusquement, puis qu'il diminue tout aussi brutalement au bout de quelques heures ? N'oublions pas que ces changements ont en général lieu au milieu de la nuit ou le week-end, d'après un corollaire de la loi de Murphy.
Pour cette raison, il est possible de redimensionner vos clusters de calcul. Ce redimensionnement peut se faire de manière manuelle ou automatique.
Le redimensionnement manuel est simple à réaliser : il suffit d'aller dans l'interface de configuration de votre cluster, dans l'onglet "Matériel" et de modifier le nombre d'instances du "Core Instance Group".
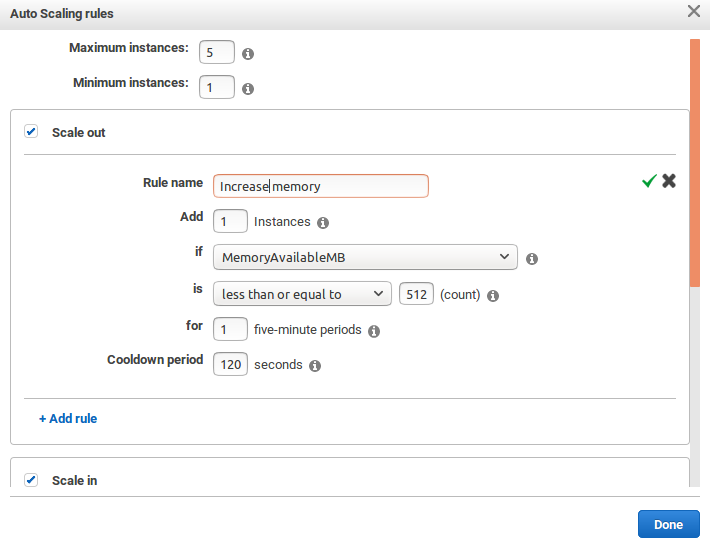
Le redimensionnement automatique d'un cluster se fait lors de sa configuration, à l'aide des options avancées. Dans l'étape 2 de la configuration ("Matériel"), vous pouvez activer le passage à l'échelle automatique ("autoscaling") en ajoutant une règle de "scale out". Les règles de "scale out" permettent d'augmenter la charge, tandis que les règles de "scale in" permettent de la diminuer. Si vous vous attendez à une augmentation constante de la charge, il n'est pas nécessaire de prévoir des règles de scale in. Si, au contraire, vous vous attendez à faire face à des pics ponctuels de charge, n'oubliez pas d'ajouter des règles permettant de supprimer des instances. A titre d'exemple, voici une capture d'écran d'une règle de scale out qui ajoute une instance à la fois lorsque la mémoire totale disponible dans le cluster passe en dessous de 512 Mo pendant au moins cinq minutes. Quand une instance a été ajoutée, on attend pendant une durée dite de "refroidissement" ("cooldown") de deux minutes avant de pouvoir ajouter à nouveau ou retirer une instance.