Découvrez des exemples de problèmes traités par apprentissage
Nous avons vu, dans le cours précédent, qu'un problème d'apprentissage était caractérisé par des données, un coût, un modèle, une phase d'optimisation et une capacité à généraliser. Nous allons maintenant détailler chacun de ces aspects en commençant par les données, à travers des exemples de problèmes traités par apprentissage.
Nous allons voir ce que l'on peut faire et ce que l'on ne sait pas faire à l'aide des méthodes d'apprentissage statistiques. Comme la base de cet apprentissage est l'assimilation de données, nous allons aussi présenter différents types de données utilisés pour entraîner les systèmes.
Différentes bases de données pour apprendre à classer
Commençons par illustrer ce problème sur un exemple jouet. Supposons que nous disposions d'un ensemble d’observations étiquetées en deux dimensions et donc . Chacun des points est soit rouge soit bleu. Le but de l’apprentissage est ici de construire une fonction de sur permettant de prédire au mieux si un point doit être étiqueté rouge ou bleu.
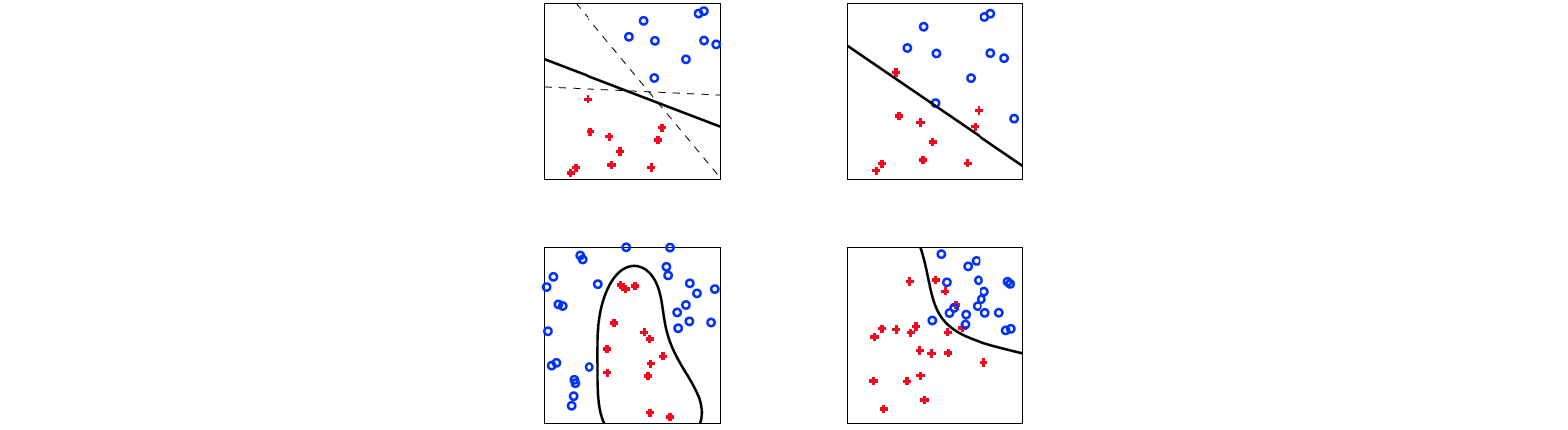
Dans le problème jouet ci-dessus, les données sont constituées de observations avec variables, des étiquettes binaires et classes. Un coût typique associé à ce problème est la fonction de perte 0/1 qui s'écrit pour une prédiction quand la vraie classe est
Le Wisconsin Diagnostic Breast Cancer (WDBC) est un autre jeu de données, réelles cette fois, typique pour la classification et produit dans les années 70. Le problème est de prédire à partir d'une image si la tumeur repérée sur l'image est bénigne ou maline. Les données disponibles sont composées de couples caractéristiques-étiquettes binaires ( ). À partir de chaque image, des experts ont extrait à la main caractéristiques pertinentes pour réaliser cette tâche.
Dans les années 90, la base MNIST a été mise à disposition des chercheurs. Il s'agit d'une base d’apprentissage et d'une base de test. La base d’apprentissage est constituée de couples d'imagettes étiquetées. Les imagettes sont des carrés de 28 pixels codés sur 256 niveaux de gris, de sorte que et . Chaque imagette représente un chiffre. Il s'agit donc d'un problème de classification à classes. Cette base à été construite pour voir s'il était possible d'apprendre à classer des images sans utiliser de phase d'extraction manuelle de caractéristiques comme celle utilisée pour les données WDBC.

La décennie suivante a vue l'apparition du jeu de données Newsgroup, constitué de textes qu'il faut classer. La base d'apprentissage associée est constituée de textes, chacun décrit par un vecteur de million de fréquences d'apparition de mots dans le texte. Le nombre de classes est initialement de mais est parfois réduit à 2. Ces données sont caractérisées par un très grand nombre de variables et des données faisant apparaître un grand nombre de zéros. On parle de données creuses (ou sparse).
En 2012 est apparu le ImageNet Large Scale Visual Recognition Challenge. Le but de ce jeu de données est de permettre la comparaison des méthodes de reconnaissance d'objets dans des images. Les données sont composées de million images de 224 pixels codées en RGB, soit variables. Le nombre d'objets à reconnaître est . Chacune des images représente un seul objet qui a été étiqueté par les humains.

Le tableau suivant récapitule les principaux paramètres des problèmes que nous venons de voir.
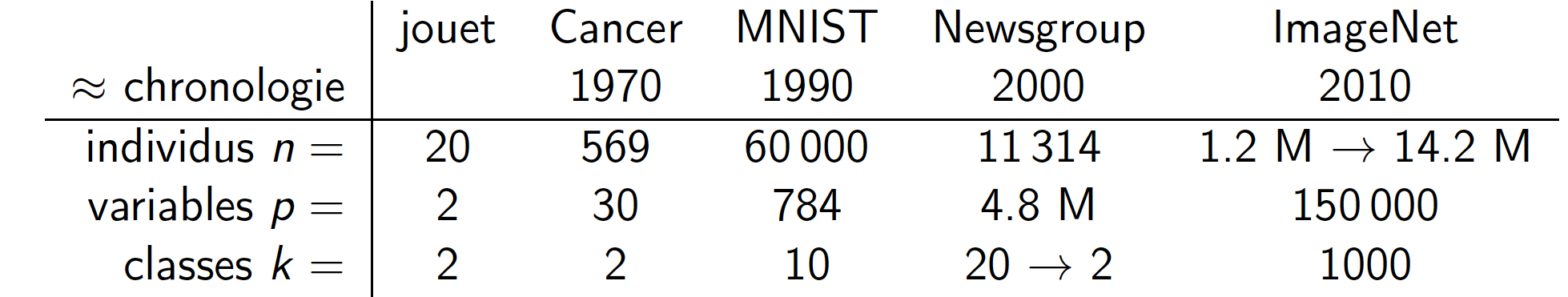
Il est clair, à partir ce tableau, que derrière la notion de classification par apprentissage se cachent plusieurs difficultés et notamment la question de la taille des problèmes, qui est cruciale. Ainsi, les problèmes d'aujourd'hui peuvent avoir des tailles avec de l'ordre du million. C'est le cas par exemple des données du projet Visual Genome, qui propose \(n = 108 077\) images haute définition annotées sémantiquement à l'aide de \(k=33 877\) objets, conçues pour relier au langage les concepts présents dans une image structurée. On peut parler dans ce cas d'un problème de classification extrême.
Exemples de problèmes liés à l'apprentissage
Nous allons voir, dans cette partie, des exemples de problèmes résolus par apprentissage et d'autres qui ne le sont pas.
Exemples de problèmes résolus par apprentissage
On trouve des systèmes programmés par apprentissage statistique dans différents domaines.
Les systèmes de filtrage automatique des messages électroniques (spam flitering) sont programmés par apprentissage tout comme les systèmes de détection de faux billets. Des méthodes d’apprentissage sont aussi utilisées pour réaliser des tâches d'estimation de prix (comme le prix de vente d'une maison) ou de prédiction de ventes.
Lorsque nous parlons à notre smartphone, la conversion de notre voix en texte est réalisée par un système qui a spécifiquement appris à réaliser cette tâche. Pour dépasser les performances humaines, les systèmes efficaces de reconnaissance de la parole ont été entraînés sur des milliers d'heures de parole dûment annotées.
Dès qu'une image est déposée sur Facebook, elle est analysée par des systèmes ayant appris à reconnaître les visages, à identifier les personnes et à générer une description textuelle de la photo. Ces systèmes ont été entraînés sur plus de 50 millions d’images, voire sur un milliard d’images pour certaines tâches.
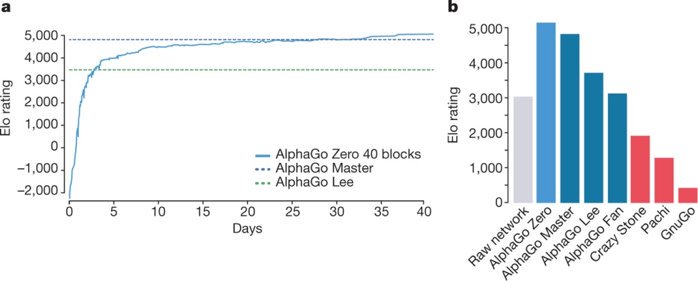
En 2017, un système ayant appris à jouer au go a battu le champion du monde Ke Jie. Puis un autre système analogue, ayant appris à jouer contre lui-même, est parvenu, après 40 jours d'entrainement sur 64 processeurs graphiques (GPU) et 19 processeurs (CPU), à obtenir de meilleures performances que tous les autres systèmes connus.

Les recommandations fournies, par exemple, par Amazon ou Netflix sur leurs sites web sont elles aussi produites en utilisant des techniques issues de l'apprentissage statistique. L'idée est d'utiliser les comportements des clients dans le passé pour inférer statistiquement leurs préférences futures.
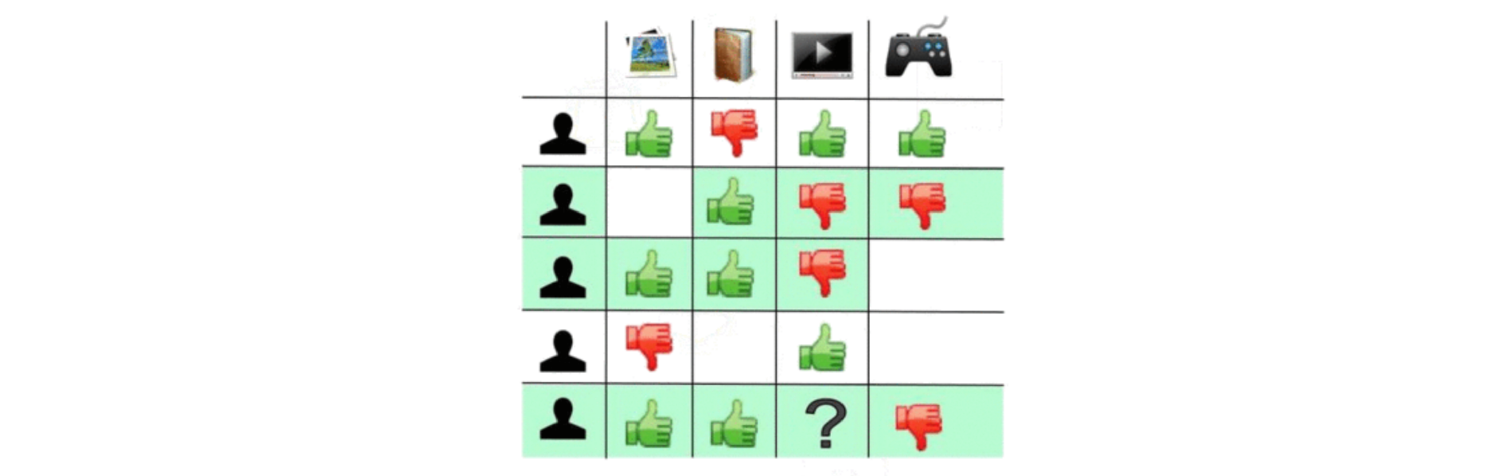
Au-delà de la recommandation, ces sites s'adaptent en temps réel à leurs utilisateurs et utilisent des algorithmes d'apprentissage pour gérer leurs expériences de personnalisation.
Les outils de traduction automatique ont aussi réalisé récemment de réels progrès grâce à l'utilisation de l'apprentissage statistique. Pour arriver à ces résultats, les algorithmes d'apprentissage ont dû assimiler 36 millions de couples de phrases en français associées à leur traduction en anglais. Cependant, les résultats ne sont pas encore au niveau de ceux d'un traducteur humain.
Il est un autre domaine ou l'utilisation d'algorithmes d'apprentissage a permis de réels progrès sans arriver à égaler l'humain : c'est celui de la conduite automatique. Par exemple, la fonction Autopilot de Tesla utilise massivement l'apprentissage. Elle est conçue dans un processus d'amélioration continue à partir d'exemples.
Dès qu'une situation d'échec est rencontrée, par exemple quand un chauffeur reprend brusquement le contrôle de son véhicule, cette situation est transmise à l'entreprise qui l'analyse et, si besoin, demande à la flotte de lui renvoyer des images des situations analogues qui serviront à améliorer l'Autopilot en le ré-entrainant.
Problèmes ouverts
Comme nous venons de le voir, que ce soit pour la traduction ou pour la conduite autonome, les algorithmes d’apprentissage n'arrivent pas encore à nous égaler. C'est que, pour résoudre ces problème, l'entrainement seul ne suffit pas, il faut être capable de comprendre le monde qui nous entoure et de raisonner dessus, ce que les algorithmes d'apprentissage d'aujourd'hui ne savent pas faire.
Parmi ces problèmes non résolus par apprentissage statistique, on peut aussi ajouter celui de la compréhension du langage naturel. Grâce à l’apprentissage, les assistants personnels qui nous entourent, les Siri, Alexa, Google assistant et autres Cortana peuvent rendre des services spécifiques, mais ils ne nous comprennent pas encore vraiment.
Nous avons aussi vu que les progrès de l'apprentissage ont été permis grâce à l'assimilation de masses de données sur les problèmes trop spécialisés, à l'issue d'un processus d’ingénierie complexe. Il n'existe pas non plus ni de théorie explicative satisfaisante ni de garantie sur la qualité des décisions proposées par les systèmes programmés par apprentissage.
Pendant son entrainement, l'apprenti ne fait qu'extraire des corrélations contenues dans les données utilisées pour apprendre. Donc si les données sont biaisées, l'apprenti le sera aussi. Ce type de biais a été observé dans certains systèmes programmés par apprentissage, avec des résultats choquants.
Par exemple, un système de recrutement automatisé s'est avéré privilégier des embauches de certains groupes raciaux, de sexe ou d’âge et un moteur de recherche a amplifié des stéréotypes négatifs, en diffusant des annonces faisant état d'une arrestation en réponse à des requêtes portant sur des noms de bébés afro-américains.
En résumé
L'apprentissage c'est, en quelque sorte, une manière de créer des programmes à partir d'exemples. Les données traitées par apprentissage sont de nature très diverse, mais quand des progrès ont été obtenus ils l'ont été sur des problèmes spécifiques pour lesquels un grand nombre d'exemples est disponible.
Nous allons maintenant voir quels sont les principaux types d'apprentissages statistiques.
