Passez de la régression linéaire à la régression logistique
L'objectif de ce chapitre est de :
découvrir la régression logistique pour des problématiques de classification binaire,
comprendre son extension à la classification multi-classe,
réaliser la sélection de variables pour la classification.
Pour nous accompagner
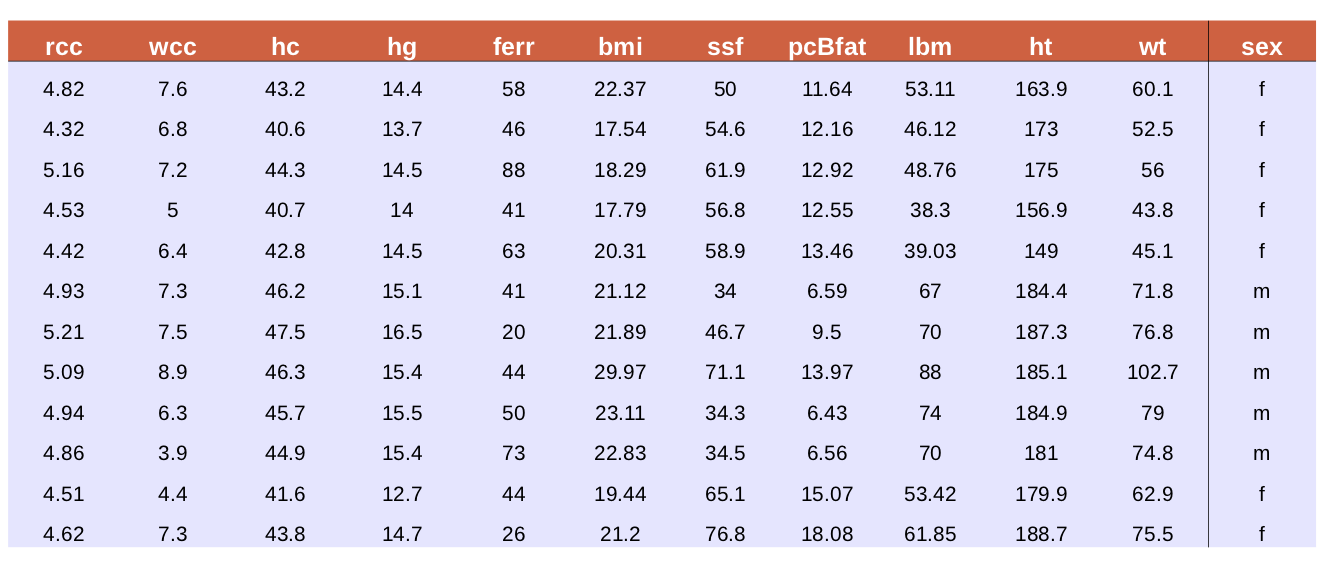
Nous nous servirons des données biologiques d'athlètes (voir le cours sur l'ACP) comme fil rouge pour ce chapitre du cours. Un extrait de ces données est présenté dans le tableau 1.
Tableau 1 : Classification d'athlètes en fonction de leurs données biologiques
Étant donné un athlète (une ligne du tableau), notons le vecteur contenant ses paramètres biologiques (rcc, wcc, .., wt) et son genre.
Construisez le modèle de prédiction
Fonction de score
Afin de classifier un point donné, nous allons construire dans un premier temps un modèle de score linéaire La règle de classification qui en découle s'exprime
où est l'étiquette qu'on attribue au point .
La frontière de séparation entre les deux classes est alors définie par l'hyper-plan d'équation
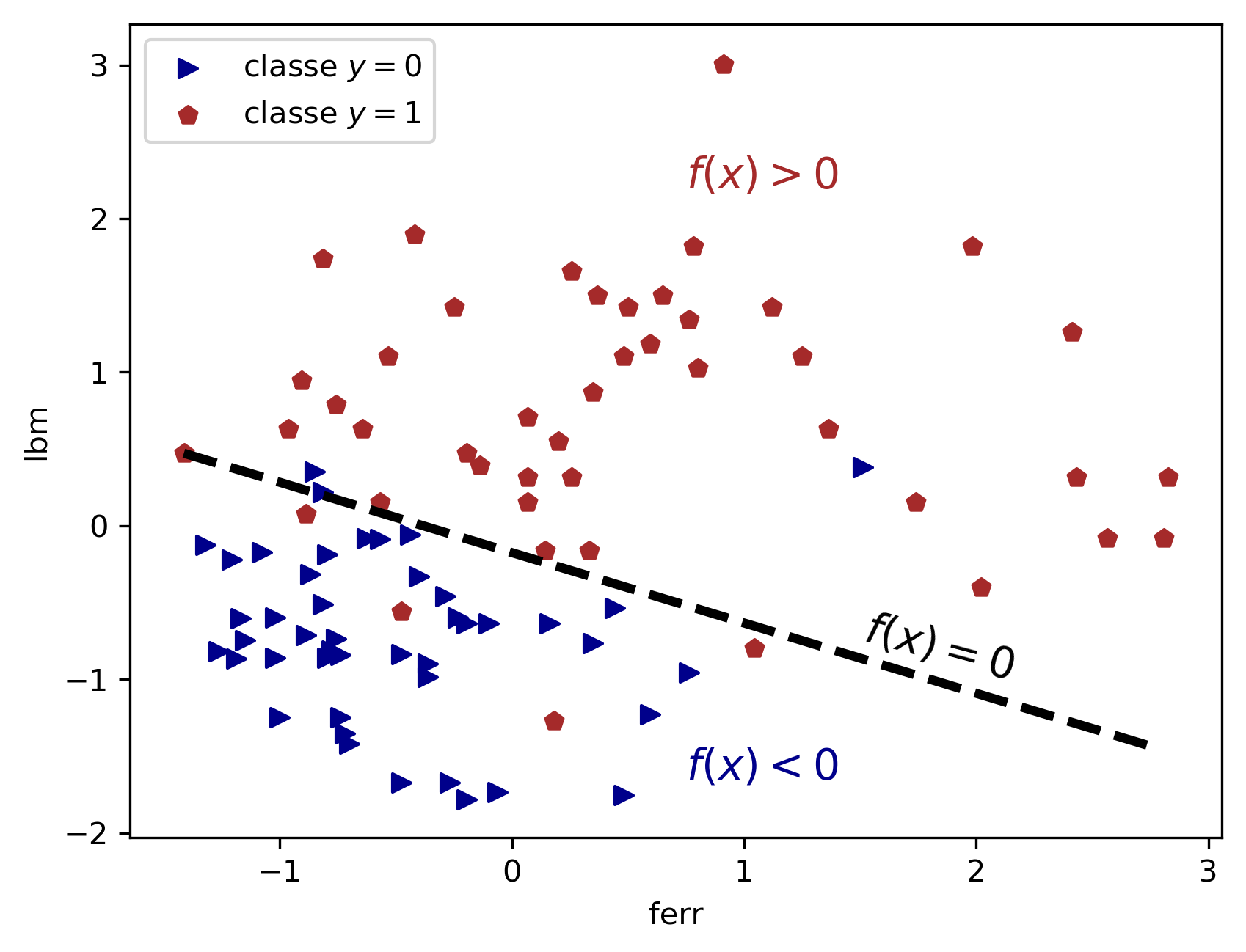
Pour illustrer cette fonction de classification, nous avons établi le modèle de score sur les données des athlètes en utilisant seulement deux variables (fer, lbm). La figure 1 montre la représentation des points (les athlètes) de chaque classe et la frontière de séparation.
Figure 1 : Hyper-plan de séparation entre les deux classes matérialisée par la droite en pointillés
Cette frontière délimite deux demi-plans distincts, où le modèle prédit respectivement les classes et . La prédiction est simplement basée sur le signe de la fonction de score.
Quelle confiance avons-nous dans la classification faite ?
Point
Score
Classe prédite
Niveau de confiance
Élevée
Faible
Tableau 2 : scores, prédictions et niveaux de confiance associés
Le tableau 2 montre des exemples de scores obtenus pour deux points de la figure 1 . L'étiquette du premier point peut être attribuée avec confiance, car son score est élevé. A contrario, le score du deuxième point vaut 0.26 ce qui n'incite pas à accorder un niveau de confiance important à la décision de classification lui correspondant. Ceci conduit à la question suivante : peut-on quantifier le niveau de confiance ?
Du score à la probabilité conditionnelle
Pour quantifier notre niveau de confiance, nous pouvons faire appel à la notion de probabilité. Spécifiquement, nous considérons la probabilité de prédire la classe sachant le point . Nous pouvons relier cette probabilité conditionnelle à la valeur du score de la façon suivante :
Si , avec certitude nous prédisons , donc .
Si , avec confiance on a et par conséquent .
Si , nous n'avons pas de certitude sur la décision ( ou ) ; dans ce cas .
Une fonction monotone croissante permettant de transformer le score en probabilité est la fonction sigmoide. Elle est définie par
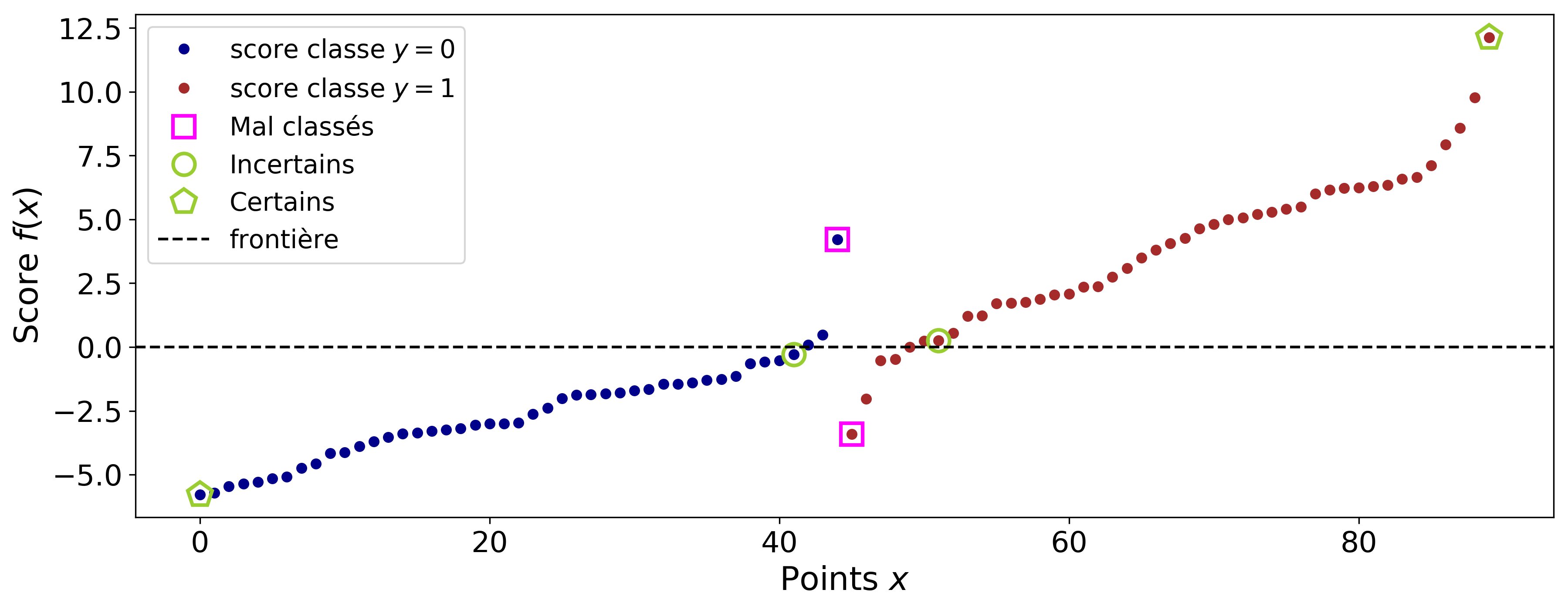
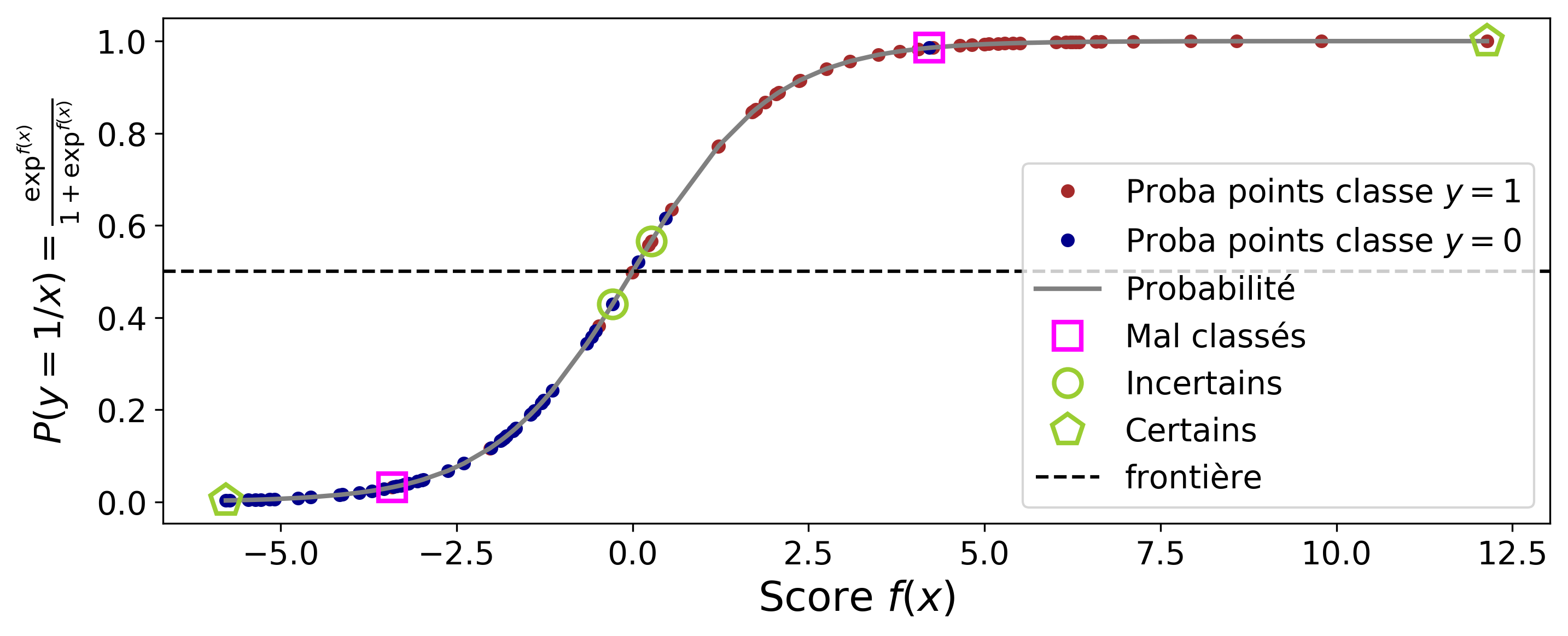
Les figures suivantes montrent respectivement les scores de l'exemple de la figure 1 et les probabilités qui en découlent.
Figure 2 : Représentation des scores (triés par ordre croissant) des pointsFigure 3 : Probabilité conditionnelle de la classe P(y=1/x) en fonction du score
Nous constatons que les points dont le score est élevé ont une probabilité forte. Les points dont le score est proche de 0 ont bien une probabilité proche de 0.5 et se situent sur la frontière de séparation. Nous pouvons alors formuler notre règle de classification à partir de la probabilité conditionnelle.
Estimez les paramètres du modèle
Le problème à résoudre
Maintenons que le concept du modèle de régression logistique est défini, nous allons voir comment estimer les paramètres du modèle que sont les coefficients . Tout d'abord, écrivons le modèle de score en notation vectorielle :
Nous pouvons aussi expliciter la probabilité conditionnelle par la relation
qui met en évidence le fait que cette probabilité dépend de .
Étant donné les points d'apprentissage , nous cherchons à estimer le vecteur des paramètres tel que pour tout point on ait :
si ,
si .
Pour cela, on va maximiser la log-vraisemblance conditionnelle des données
ou de façon équivalente minimiser par rapport à .
Comme et nous pouvons écrire notre problème d'optimisation comme ci-dessous.
Une approche d'estimation des paramètres
En remplaçant par son expression (1) dans J , il est possible de montrer que le problème d'optimisation devient
Contrairement à la régression linéaire, ce problème n'admet pas de solution analytique. Elle se calcule via des algorithmes d'optimisation de type méthode du gradient ou méthode de Newton. Nous allons expliciter le premier algorithme, qui est facile à comprendre et à implémenter.
Pour la régression logistique, le gradient de J a pour expression
Les points bien prédits avec une forte probabilité sont caractérisés par ; ils n'influencent donc pas la valeur du gradient contrairement aux points mal classés. À chaque itération, le vecteur de paramètre est mis à jour afin de corriger ces erreurs de classification.
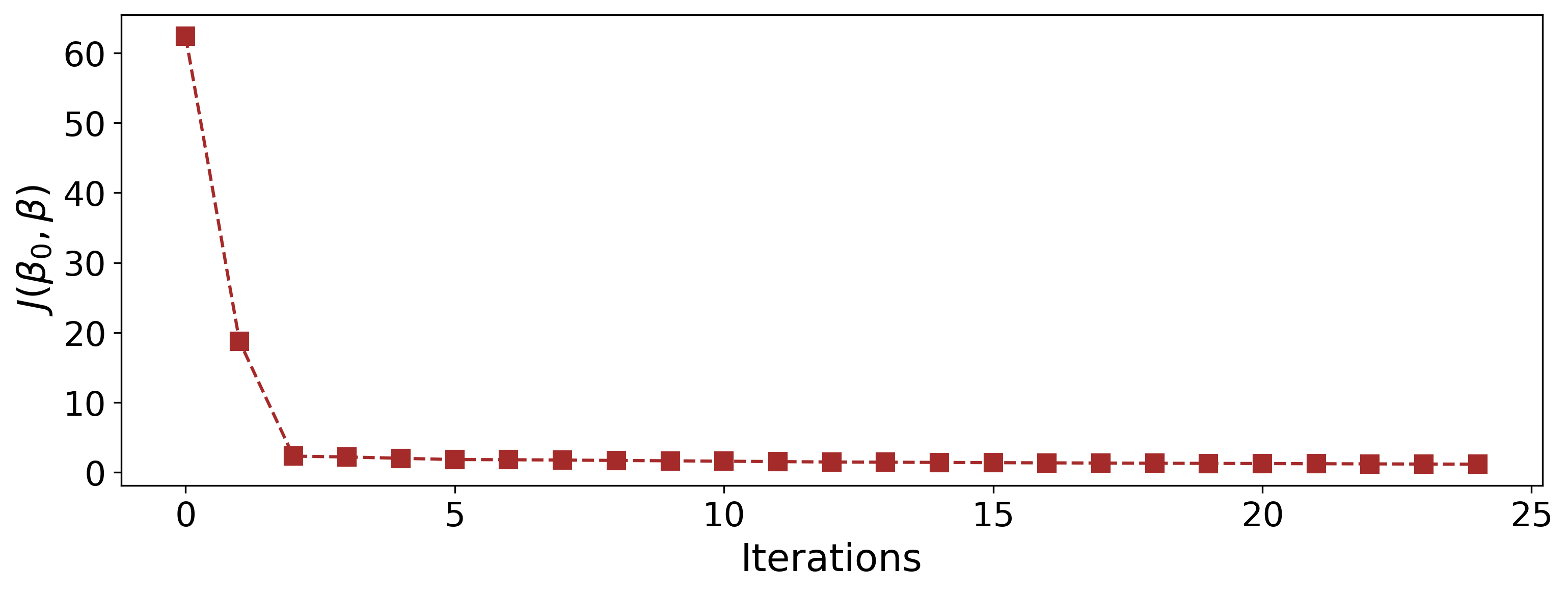
La figure 6 montre la décroissance et la convergence du critère J sur le problème de classification des athlètes en fonction de leurs paramètres biologiques.
Figure 6 : Évolution du critère J au fil des itérations (exemple des données biologiques)
Classifiez avec le modèle appris
On fait quoi après ?
Connaissant l'estimation des paramètres, pour tout point , on pourra proposer comme estimation des probabilités conditionnelles des classes
avec . La prédiction de sa classe s'obtient par
Cette prédiction pourra ensuite être comparée à la vraie étiquette pour mesurer les performances de classification du modèle de régression logistique.
Sélectionnez les variables utiles
A-t-on besoin de toutes les variables pour bien prédire la classe ?
Comme pour la régression linéaire, nous souhaitons sélectionner les variables utiles pour réaliser la classification. L'histoire va se répéter : on peut faire une régression logistique régularisée en résolvant le problème
avec le terme de régularisation et le paramètre de régularisation à régler par l'utilisateur.
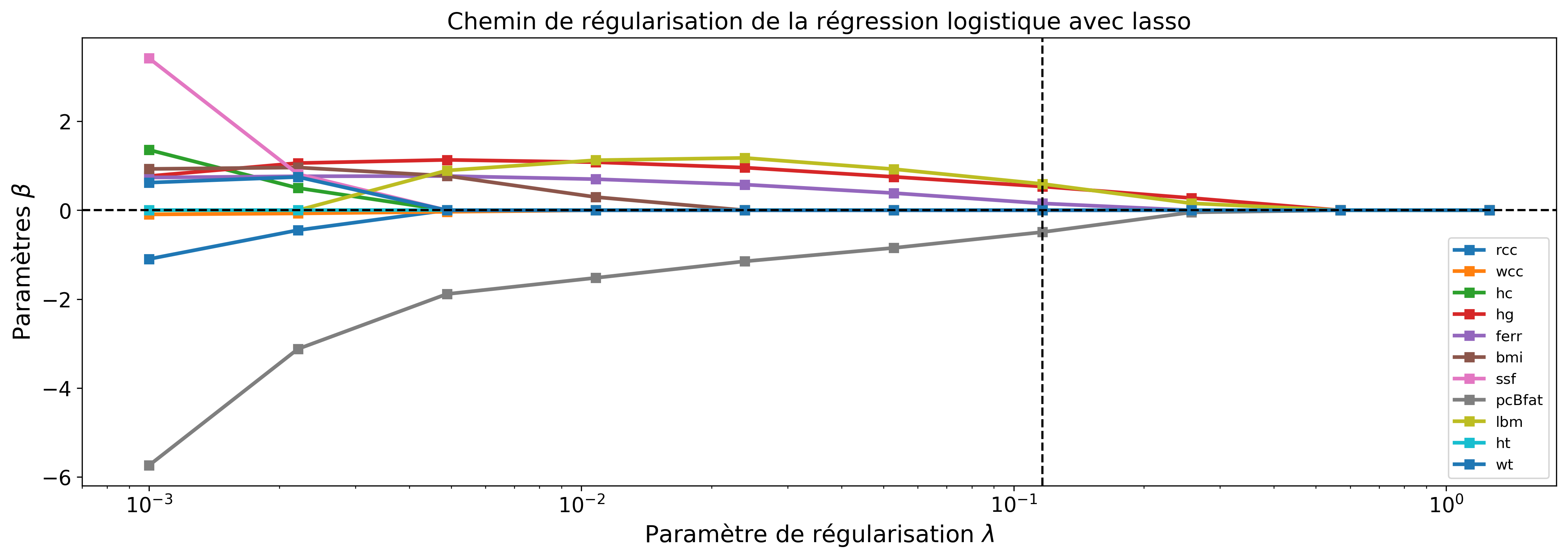
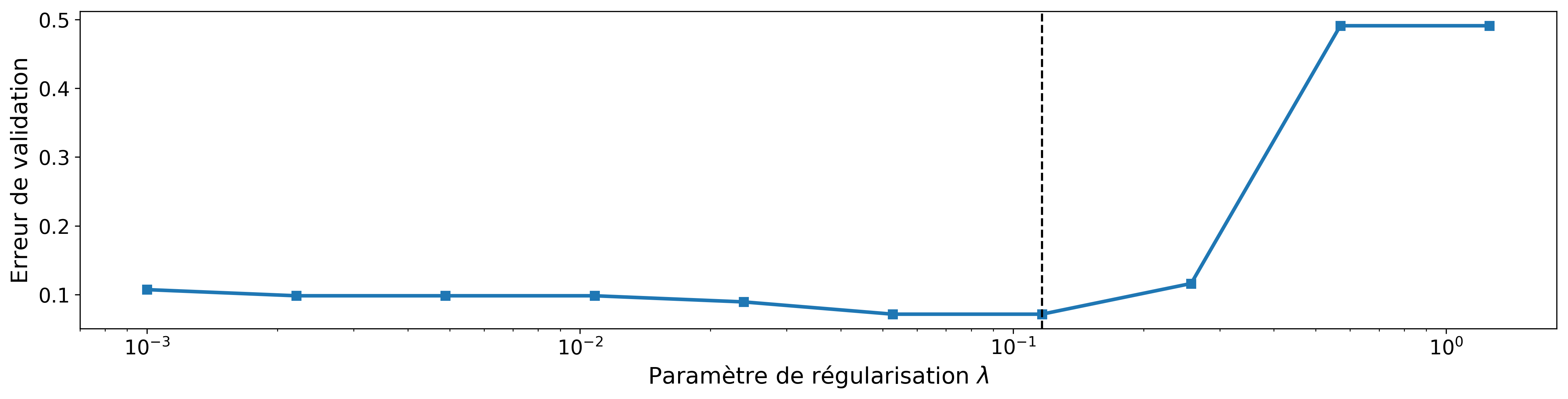
Par exemple, en prenant on a l'équivalent du lasso (voir chapitre précédent) pour la régression logistique. Les graphiques suivants montrent l'influence de cette régularisation sur les variables sélectionnées et le réglage adéquat du paramètre . Nous pouvons constater sur les figures 7-a et 7-b que nous pouvons obtenir de bonnes performances de classification en utilisant seulement quatre variables.
Figure 7-(a) Évolution de la valeur des paramètres \(\beta_j\) en fonction de \(\lambda\) sur l'exemple de classification des athlètesFigure 7-(b) Critère de validation (taux d'erreur de classification) en fonction de \(\lambda\). La ligne en pointillés indique la valeur de \(\lambda\) retenue correspondant au minimum de l'erreur de validation.
Généralisez la régression logistique à la classification multi-classe
Et si on a plus de deux classes ?
Supposons qu'au lieu de classer les athlètes par genre, on veut les classer en fonction de leur discipline sportive, Sprint, 400m, Tennis… Dans ce cas l'étiquette avec K le nombre de classes. Nous pouvons généraliser le principe de la régression logistique pour la classification binaire au problème multi-classe. Pour cela, nous définissons les probabilités conditionnelles des K classes par
On pourra vérifier que la somme des probabilités vaut 1.
Comment calculer les paramètres ?
Les probabilités conditionnelles font intervenir vecteurs de paramètres , qui sont déterminés par minimisation de l'opposée de la log vraisemblance.
où
Le critère à minimiser est, comme précédemment, la somme de n termes de fonction de coût égale à .
Les méthodes de descente, comme l'algorithme du gradient, peuvent être utilisées pour estimer les paramètres même si le problème à résoudre est plus compliqué.
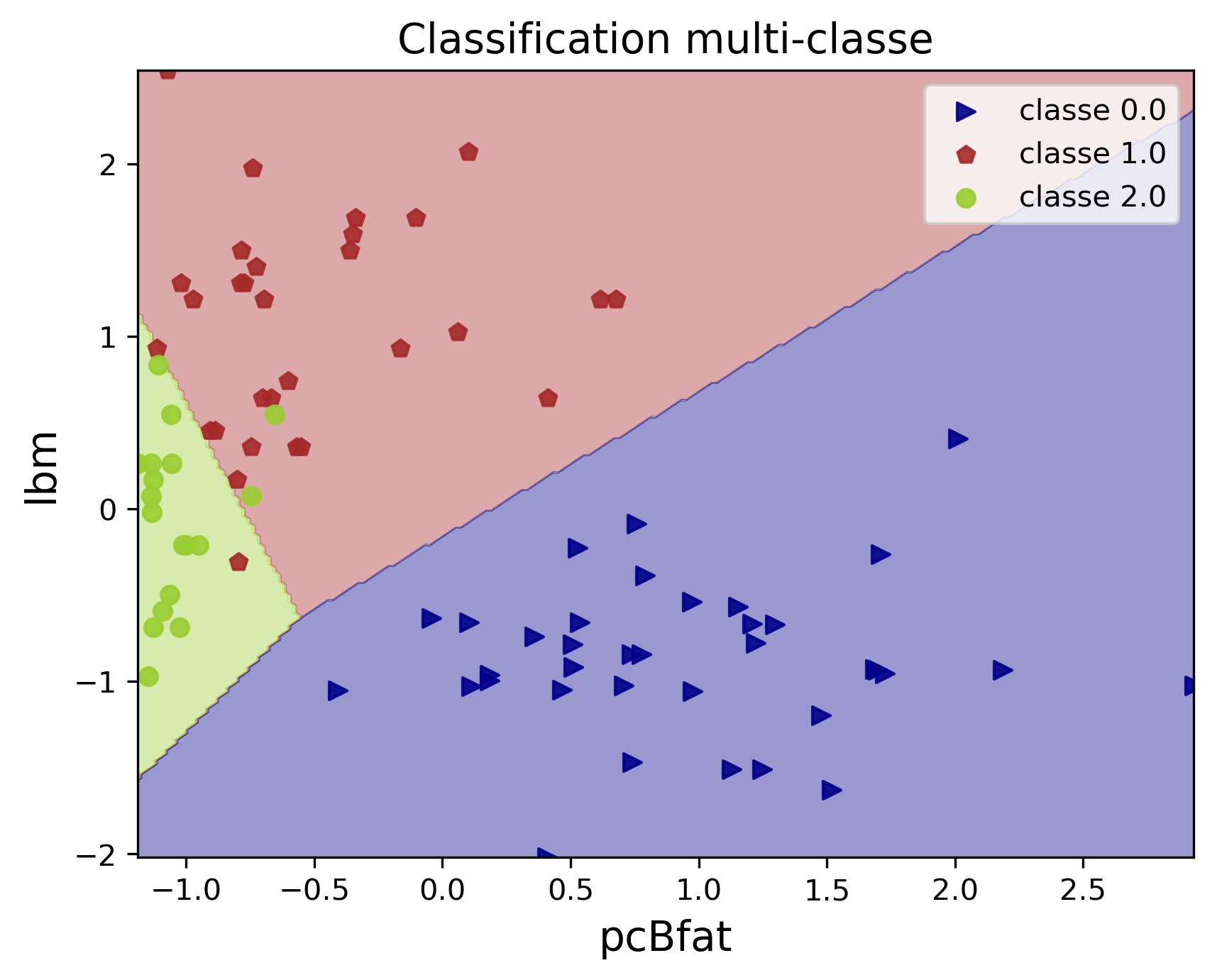
La figure suivante montre un exemple de classification multi-classe à K=3 classes sur les données biologiques des athlètes. Nous pouvons constater qu'on a K frontières linéaires de séparation entre les classes. Ces frontières définissent des séparations entre paires de classes.
Figure 8 : Exemple de classification multi-classe
En résumé
La régression logistique linéaire :
permet de réaliser la classification binaire et multi-classe,
fournit les probabilités conditionnelles des classes — ce qui permet de prendre des décisions avec un niveau de confiance,
donne des frontières de séparation entre classes linéaires,
permet d'intégrer dans le problème d'optimisation des termes de régularisation afin de sélectionner les variables utiles.
Dans le chapitre suivant, nous allons étudier une autre méthode de classification, le SVM, et son extension au cas non-linéaire.