Nous avons construit l’IHM de notre application !
Il nous reste maintenant à :
modéliser la base de données chargée d’enregistrer tous nos flux ;
définir les règles d’accès à ces données ;
et enfin, identifier les flux entrants (qui vont alimenter notre base) et les flux sortants (qui alimenteront d’autres applications).
Le Modèle Physique de Données (MPD)
Il existe plusieurs démarches pour créer un modèle de données. Pour notre projet, nous nous inspirerons de la méthode enseignée par Loïc Guibert dans le cours “Modélisez et implémentez une base de données relationnelle avec UML”. Je vous invite à suivre ce cours pour aller plus loin.
Revenons à notre cahier des charges et identifions nos premiers objets, ou entités. Modélisons notre domaine : je ne vais pas entrer dans le détail des étapes de modélisation des classes UML et j’en viendrai directement au Modèle Physique de Données (MPD).
Quelle est la différence entre MCD et MPD ?
Le MCD (Modèle Conceptuel de Données) est une représentation graphique de haut niveau qui permet de comprendre facilement comment les différents éléments sont liés entre eux à l’aide de diagrammes codifiés dont les éléments suivants font partie :
les entités (1 rectangle = 1 objet) ;
les propriétés (la liste des données de l’entité) ;
les relations qui expliquent et précisent comment les entités sont reliées entre elles ;
les cardinalités.
Le MPD (Modèle Physique de Données) fait suite au MCD. Concrètement, cette étape permet de construire la structure finale de la base de données avec les différents liens entre les éléments qui la composent. Pour la peine, on change aussi de vocabulaire :
Les entités se transforment en tables.
Les propriétés se transforment en champs (ou attributs).
Les propriétés se trouvant au milieu d’une relation génèrent une nouvelle table ou glissent vers la table adéquate en fonction des cardinalités de la relation.
Les identifiants se transforment en clés et se retrouvent soulignés. Chaque table dispose d’au minimum 1 clé dite primaire.
Les relations et les cardinalités se transforment en champs parfois soulignés : il s’agit de créer des « clés étrangères » reliées à une « clé primaire » dans une autre table.
Le monitoring des flux :
Nous savons, d’après notre cahier des charges, qu’il existe 4 types de flux :
L’extraction des devis
La télécollecte
La transformation des fichiers CSV
L’intégration dans l’ERP
Voici donc nos deux premières entités : Flux et Type_Flux
Nous savons également qu’un flux ne peut être que d’un et un seul type, et qu’un type de flux peut concerner 0 ou N flux. Nous en déduisons donc également les cardinalités de la liaison entre ces deux entités.
Nous pouvons, à ce stade, également commencer à décrire ce qui caractérise un flux : une date, une agence, un fichier CSV, un statut. Nous avons donc une nouvelle entité, l’agence, et nous pouvons déduire les cardinalités avec l’entité flux.

Vous avez saisi le principe ? Essayez de finaliser votre modèle physique de données avant de lire la suite.
Vous avez fini ? Voici ma proposition… Comparons notre travail !
Les utilisateurs et les groupes
Nous savons que :
Seuls les utilisateurs déclarés et ayant un rôle peuvent accéder à l’application.
Nous savons également qu’un utilisateur membre d’une agence ne pourra voir QUE les données relatives à son agence.
Un utilisateur peut appartenir à plusieurs agences ou à aucune.
Si un utilisateur est ADMIN, il pourra accéder à l’ensemble de l’application et à l’ensemble des données.
Cliquez ici pour voir l'ajout des utilisateurs sur le MPD.
Les devis et factures
Chaque devis étant à l’origine d’une et une seule facture et chaque facture étant issue d’un et un seul devis, nous faisons face à une relation (1.1). Je choisis donc de ne créer qu’une entité que je vais appeler pièce.
Voici donc le résultat de mon analyse : cliquez ici pour voir le MPD de l'application de suivi des flux qui en résulte.
Vous n’avez pas le même résultat ? Rassurez-vous, c’est tout à fait normal.
Il y a autant de solutions qu’il existe d’informaticiens. Assurez-vous simplement, lors de votre comparaison, que tous les éléments du cahier des charges fonctionnel ont bien été repris et mis en musique dans votre propre MPD.
Les flux entrants et sortants (interfaces/mapping)
En entreprise, il est très rare qu’une application se suffise à elle-même.
Au-delà de son utilisation par des humains, elle est généralement également en “contact” avec d’autres applications du SI.
Il vous faudra donc, dans vos projets SI, identifier avec précision les applications qui alimenteront les données (les flux entrants) et celles qui consommeront les données (les flux sortants). C’est ce que j’ai représenté sur ce schéma :
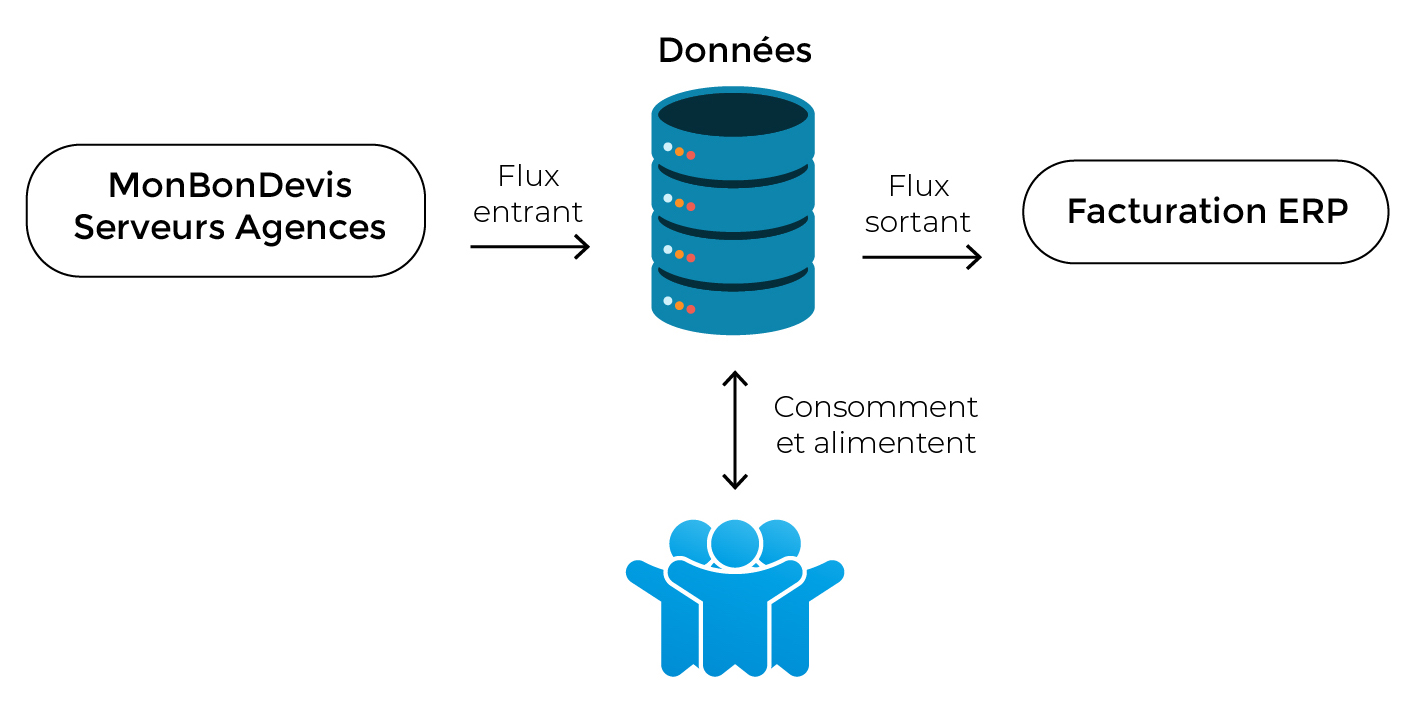
Une fois ces données identifiées, vous devrez décrire :
les fichiers en entrée et en sortie ;
les éventuelles tables de correspondance ;
la fréquence et le mode de mise à jour : synchrone, asynchrone, transactionnel (saisie manuelle), par batch (par un programme lancé automatiquement chaque nuit), etc. ;
les mécanismes d’accès aux données (la couche de persistance).
L’accès aux données
Le plus souvent, les applications de gestion orientées objet s’appuient sur des bases de données relationnelles. L’enjeu, pour les développeurs, consiste à passer systématiquement par une phase de conversion aussi appelée mapping objet/relationnel afin de faire matcher la structure des données en base avec la structure des objets de l’application.
Dans un schéma relationnel, nous l’avons vu au début de ce chapitre, les liens sont représentés par des mécanismes de clés étrangères.
Un modèle objet, quant à lui, s’appuie plutôt sur des dépendances typées (les collections, les classes, etc.), ainsi que sur un développement caractérisé par l’héritage ou le polymorphisme.
De par sa conception, le modèle objet s’adapte difficilement au modèle relationnel.
Dans le cas le plus simple, celui d’une application totalement autonome, il est fort probable que l’analyse orientée objet ait été menée intégralement. Ainsi, la structure de la base de données (MPD) correspondra plutôt bien au modèle objet de l’application.
Malheureusement, en entreprise (et même dans le monde internet), avec un projet comme le nôtre mettant en jeu plusieurs applications (MonBonDevis et l’ERP ODOO), ce sera rarement le cas.
Pour contourner cette difficulté et faciliter l’accès aux données, les développeurs mettront en place ce que l’on appelle une couche de persistance dont l’objectif est double :
rendre indépendantes l’application et les données ;
masquer la complexité de l’accès aux données.
Et alors ? Concrètement, pour notre application de suivi des flux ?
Souvenez-vous : le programme d’extraction des devis que nous devons développer tournera sur les serveurs agence. Il devra accéder à notre base de données pour :
récupérer un numéro de transaction ;
enregistrer dans la base de données les informations relatives à chaque transaction ;
enregistrer le statut de la transaction en fin de programme.
Ce programme aura donc besoin d’accéder à notre base de données pour faire tout cela. Vous devrez donc, à l’aide des développeurs de notre application de suivi des flux, définir la couche de persistance et ainsi donner aux développeurs de notre programme d’extraction les règles d’accès à cette base, via une API par exemple.
En résumé
Dans ce chapitre, vous avez :
modélisé votre base de données ;
défini les flux entrants et les flux sortants ;
et enfin, défini les règles d’accès aux données.
Nous avons maintenant tous les éléments nécessaires à la formalisation de notre cahier des charges technique. C’est ce que nous allons faire dans le chapitre suivant !

{kind=link}
{kind=link}