Recherchez les corrélations
Vous l’aurez compris, étudier les relations entre les variables, c’est important.
Pour être plus formel, la notion de relation entre variables est appelée corrélation. Dire que deux variables sont corrélées signifie que si on connaît la valeur d’une variable, alors il est possible d’avoir une indication (plus ou moins précise) sur la valeur d’une autre variable.
Dans le chapitre précédent, on étudiait déjà des corrélations, en se posant la question : connaissant l'âge d'un individu, peut-on avoir une indication plus précise de la valeur de la variable "intérêt pour un album donné" ?
Appréhendez la causalité
S’il y a corrélation entre une variable et une variable , est-ce qui est la cause de , ou qui est la cause de ? Il est souvent impossible de le savoir sans effectuer une expérimentation. Le plus souvent, c’est un troisième (ou plusieurs) facteur (qui n’est d’ailleurs pas toujours observé) qui est la cause de et de B .
Il est aussi possible que 2 variables soient corrélées sans qu’il n’y ait aucun lien entre elles. On les appelle les corrélations fallacieuses (spurious correlations, en anglais).

En fait, pour avoir le droit d’établir un lien de cause à effet entre des variables, il faut construire une expérimentation qui respecte certaines conditions. Ces conditions ne sont en général pas vérifiées lorsque votre échantillon ne provient pas de cette expérimentation conçue spécialement.
Si vous aimez les paradoxes mathématiques, il y en a un qui traite du lien de cause à effet, c’est le paradoxe de Simpson. Tout bon Data Analyst devrait être conscient de ce paradoxe. Une vidéo très bien expliquée et très compréhensible a été réalisée par la superbe chaîne YouTube Science Étonnante.
Vous verrez, ce paradoxe vous bluffera !
Réfléchissons...
Comme souvent dans ce cours, je vais une fois de plus faire appel à votre imagination. Il est toujours bon d’avoir de l’imagination.
Aujourd’hui, il vous prend la soudaine envie de faire des statistiques sur les habitants de votre ville. Vous souhaitez connaître leur boisson préférée parmi celles-ci : café, thé, eau, ou autre.
Vous réalisez donc votre enquête en vous rendant dans les cafés pour observer discrètement les clients et noter la boisson qu’ils ont commandée. Vous souhaitez rassembler un échantillon de 100 personnes. Pour chacune d’elle, vous avez noté la boisson commandée et le nom du café dans lequel vous l’avez observée. On appellera ces deux variables nom café et boisson préférée. Voici la distribution que vous obtenez pour la variable boisson préférée :
café : 50 personnes sur 100, soit = 50 % ;
thé : 30 personnes sur 100, soit = 30 % ;
autres boissons : 20 personnes sur 100, soit = 20 %.
Vous continuez votre enquête en vous rendant dans un café où il y a 10 clients. Combien de personnes vous attendez-vous à voir face à un thé ?
Intuitivement, vous vous attendez à trouver 3 personnes qui ont commandé un thé car vous savez qu’en général, 30 % des personnes commandent un thé. Vous avez donc réalisé le calcul suivant : 30%*10 = 3. De même, vous vous attentez à voir 5 personnes avec un café, et 2 personnes avec d’autres boissons.
À votre grande surprise, il y a en fait 9 personnes avec du thé, et seulement 1 avec un café ! Cela diffère beaucoup de ce à quoi vous vous attentiez : il y a 90 % de personnes qui boivent du thé. C'est peut-être un hasard, alors vous décidez de revenir régulièrement pour savoir si ce 90 % se confirme de jour en jour ou pas. Effectivement, ce pourcentage reste à peu près constant même après de nombreuses observations !
Mais vous comprenez vite pourquoi en regardant le nom du café : "Salon de thé Chez Luc". Vous êtes dans un café un peu spécial : c’est un salon de thé ! Les clients qui fréquentent cet endroit sont donc principalement des amateurs de thé.
On dit alors que le fait d’aimer le thé et le fait de fréquenter le salon de thé Chez Luc ne sont pas indépendants. Si deux événements ne sont pas indépendants, alors on s’attend à trouver une corrélation entre ceux-ci. Vous souvenez-vous de la question que l'on se pose pour les corrélations : Sachant que l'on connaît la valeur d'une variable, peut-on avoir une indication un peu plus précise sur la valeur d'une autre variable ?
Sachant qu’une personne fréquente le café Salon de thé Chez Luc, peut-on avoir une indication un peu plus précise sur sa boisson préférée ?
La réponse est oui ! Sans connaître la valeur de la variable nom café, alors on suppose que la variable boisson préférée suivra cette distribution : 50 % pour le café, 30 % pour le thé et 20 % pour les autres boissons. MAIS, si on connaît la valeur de la variable nom café (ici : Salon de thé Chez Luc), alors on peut avoir une meilleure indication sur la variable boisson préférée ; ici on s'attendra à trouver bien plus que 30%*10=3 personnes devant une tasse de thé.
Appelons l'événement "préférer le thé" et l'événement "être au salon de thé Chez Luc". Voici ce qu'il faut retenir :
Quand vous avez vu que était en fait égal à 9, vous vous êtes dit que le fait d'être au salon de thé Chez Luc n'était pas indépendant du fait d'aimer le thé !
Le tableau de contingence
On peut résumer tout cela dans un tableau appelé tableau de contingence (où X = nom café et Y = boisson préférée) :
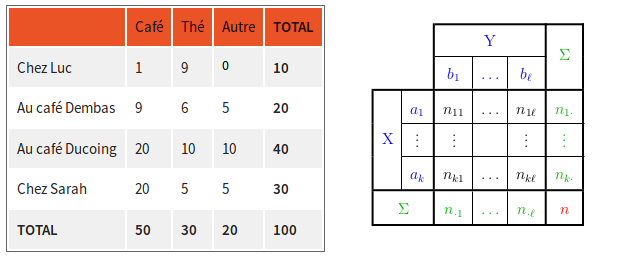
Allez, un peu de vocabulaire pour finir ce chapitre :
Chacune des valeurs du tableau de contingence (hors colonnes TOTAL) est appelée effectif conjoint .
L'ensemble effectifs conjoints est appelé distribution conjointe empirique de (nom café, boisson préférée).
La dernière ligne (TOTAL) est appelée distribution marginale empirique de boisson préférée, et la dernière colonne (TOTAL) est appelée distribution marginale empirique de nom café.
L'ensemble des effectifs conjoints de la première ligne (Chez Luc) est appelé distribution conditionnelle empirique de boisson préférée étant donné que nom café = Chez Luc.
En résumé
La corrélation entre deux variables correspond à la relation qu'il existe entre elles : si on connaît la valeur de l'une, alors on peut plus ou moins précisément déduire la valeur de l'autre.
Au niveau mathématique, étudier une corrélation entre deux variables revient à étudier la dépendance qu'il existerait entre les deux évènements ayant généré ces variables.
On peut avoir une corrélation sans avoir de lien de cause à effet.
À présent, nous allons plonger un peu plus techniquement dans l'analyse des corrélations, en distinguant trois grands cas :
entre deux variables quantitatives ;
entre deux variables qualitatives ;
entre une variable quantitative et une variable qualitative.
C'est parti !
