Comprenez les mesures de dispersion
Au chapitre précédent, votre ami vous a donné une estimation de la durée du trajet. Mais il vous a donné des mesures de tendance centrale, comme par exemple la moyenne, qui est de 60 minutes par trajet.
Ce qui vous manque maintenant, c'est de savoir si les durées des trajets que votre ami a effectués sont très "resserrées" autour de 60 min (exemple : [58, 60, 62, 59, 57...] ), ou bien si elles s'en écartent beaucoup (exemple : [40, 70, 78, 43...] ).
Quel intérêt ?
Si les valeurs sont très resserrées autour de 60 minutes, alors prévoyez de partir 75 minutes à l'avance. Ainsi, il est probable que vous arriverez 5 ou 10 minutes avant votre entretien. Mais si les valeurs sont très écartées, alors prévoyez plutôt de partir 100 minutes à l'avance, car il est tout à fait possible que le trajet dure 80 minutes !
J'ai compris ! Mesurer l'espacement des valeurs... j'imagine qu'il y a une mesure statistique pour cela, non ?
Tout à fait ! :D Il y en a même plusieurs. On les appelle les mesures de dispersion.
Réfléchissons
Essayons de construire notre propre indicateur de dispersion, pas à pas. Pour illustrer, prenons les valeurs suivantes (70, 60, 50, 55, 55, 65, 65), et donnons-leur à chacune un nom : , avec allant de 1 à 7. Ainsi, nos valeurs portent les noms de à .
Formellement, on écrit avec .
Remarquons que la moyenne de ces valeurs vaut 60, on la note , et on prononce "x barre".
Facile de faire une mesure de dispersion ! Prenons toutes nos valeurs, et calculons pour chacune d'entre elles l'écart qu'elles ont avec la moyenne. Puis additionnons tous ces écarts !
C'est un bon début. Comme notre moyenne est de 60, les écarts des à la moyenne sont : . Sauf que... si nous faisons la somme de ceux-ci, on obtient 0 ! On peut même le démontrer mathématiquement : quelle que soit la dispersion de vos valeurs, la somme des écarts à la moyenne vaudra toujours 0. Pas très efficace donc...
Si ça vaut 0, c'est parce qu’il y a des nombres positifs et des nombres négatifs. Évitons cela, et mettons-les tous au carré. Un nombre mis au carré, c'est toujours positif, n'est-ce pas ?
Exact ! Voici ce que ça donne : . Maintenant, si on fait la somme de toutes ces valeurs, on obtient 300.
Bon. Il y a encore un problème. Ici, on a 7 valeurs, tout simplement parce que nous sommes un peu paresseux, et nous n'en avons relevé que 7. Mais en statistiques, plus on fait de relevés, plus on a une idée précise de ce que l'on décrit. Ainsi, on aurait dû retenir 10, 100 ou même 1 000 valeurs !
Mais avec 1 000 valeurs, notre mesure exploserait ! Il passerait de 300 avec 7 valeurs à peut-être 40 000 000 000 avec 1 000 valeurs. C'est problématique.
Alors, plutôt que de calculer la somme, et avoir un indicateur qui explose, prenons plutôt la moyenne. Ainsi, qu'il y ait 7 valeurs ou 1 000 valeurs, la moyenne n'explosera pas.
Bonne idée. La moyenne de (100,0,100,25,25,25,25) est 42,86.
Appréhendez les mesures de dispersion
La variance empirique
Devinez quoi ! L'indicateur que nous venons de construire est l'un des plus utilisés en statistiques ! :soleil: Il s'appelle la variance empirique. Comme nous venons de le voir, elle est égale à :
Pour calculer la variance en Python, cela se fait très facilement ! Il suffit d'utiliser la méthode .var() sur la variable considérée. Par exemple avec la variable montant de notre jeu de données de transactions bancaires :
data['montant'].var()Aussi, vous trouverez souvent une version "corrigée" de la variance empirique, que l'on qualifie de non biaisée. En effet, quand on se plonge dans les calculs, on s'aperçoit que la variance empirique donne des valeurs qui (en moyenne) sont inférieures à la variance de la variable aléatoire. Il s'agit de la notion de biais d'un estimateur. Un estimateur sans biais est meilleur qu'un estimateur biaisé.
Pour corriger ce biais, on a créé la variance empirique corrigée, ou variance empirique sans biais. Elle est souvent notée , et est égale à , où est la variance empirique, et la taille de l'échantillon. Quand la taille de l'échantillon est grande, la variance empirique et la variance empirique corrigée sont presque égales.
Voici comment calculer la variance empirique corrigée en Python :
data['montant'].var(ddof=1)L'écart-type empirique
L'écart-type empirique, c'est juste la racine carrée de la variance empirique. On l'appelle en anglais standard deviation, souvent abrégé std. En fait, quand on calcule la variance empirique des temps de trajet, le résultat a pour unité la minute , ce qui n'est pas très intelligible. En prenant la racine carrée, l'unité redevient la minute. Ici, notre écart-type vaut 6,55 minutes. On le note .
Voilà comment calculer l'écart-type de la variable montant :
data['montant'].std()Mais lorsque vous faites un trajet, un écart-type de 6,55 minutes sur un trajet de 1 h (1h en moyenne), ce n'est pas la même chose qu'un écart-type de 6,55 minutes sur un trajet de 24 h (24h en moyenne) ! Pour remédier à cela, on a donc créé le coefficient de variation qui est l'écart-type empirique divisé par la moyenne :
Le calcul de ce dernier en Python est tout aussi simple :
data['montant'].std()/data['montant'].mean()L'écart interquartile
Vous vous souvenez de la médiane ? C'est la valeur au-dessous de laquelle se trouvent la moitié des valeurs.
Un quartile, c'est la même chose, mais avec la proportion d'un quart. Il existe 3 quartiles, notés (premier quartile), (deuxième quartile) et (troisième quartile). Ainsi :
1/4 des valeurs se trouvent en dessous de et 3/4 au-dessus ;
2/4 se trouvent en dessous de , et 2/4 au-dessus ( est la médiane !) ;
3/4 se trouvent en dessous de , et 1/4 au-dessus.
L'écart interquartile est la différence entre le 3e quartile et le 1er quartile :
La boîte à moustaches (boxplot)
Boîte à moustaches, quel nom rigolo ! :lol: Les anglophones l'appellent boxplot.
Elle permet de représenter schématiquement une distribution, en incluant sa dispersion. La boîte est délimitée par et , et on représente souvent la médiane à l’intérieur de la boîte. On dessine ensuite des moustaches à cette boîte, qui vont de la valeur minimale à la valeur maximale... à condition que la moustache (d'un côté ou de l'autre) ne mesure pas plus de 1,5 fois l'écart inter-quartiles. Si certaines valeurs sont au-dessous de ou au-dessus de , alors on les considère comme des outliers, et on ne les inclut pas dans la moustache :
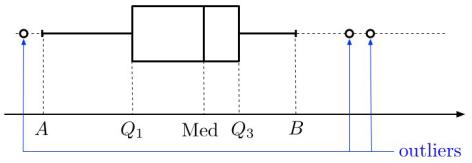
Nous pouvons facilement construire une boîte à moustaches avec Python :
data.boxplot(column="montant", vert=False)
plt.show()Le mot clé vert=False signifie que nous souhaitons que la boîte à moustaches ne soit pas à la verticale (donc à l'horizontale !)
Découvrez les autres mesures de dispersion
Quand au début du chapitre, nous avons dit :
Mettons-les tous au carré. Un nombre mis au carré, c'est toujours positif, n'est-ce pas ?
... peut-être vous êtes-vous dit :
On peut prendre la valeur absolue aussi plutôt que le carré, non ?
Tout à fait. Quand on fait cela, on calcule l'écart moyen absolu.
Il y a deux versions : l'une où on mesure les écarts à la moyenne, l'autre où on mesure les écarts à la médiane.
Voici la version avec la médiane :
Si on souhaite une mesure plus robuste, on définit également le MAD qui est la médiane des écarts absolus par rapport à la médiane.
À vous de jouer

À votre tour ! Reprenez le code développé lors du chapitre précédent, en y ajoutant pour chaque catégorie :
l'écart-type ;
la variance ;
un histogramme ;
une boîte à moustache des montants.
En résumé
Les mesures de dispersion permettent de compléter les mesures de tendance centrales, en précisant la façon dont les valeurs se répartissent autour de ces dernières.
La variance est la somme des différences à la moyenne au carré, divisée par l'effectif total.
L'écart-type correspond à la racine carrée de la variance.
L'écart moyen absolu est similaire à la variance, à la différence que le calcul fait intervenir la valeur absolue plutôt que le passage au carré.
Une représentation graphique intéressante pour représenter la dispersion d'une variable quantitative est la boîte à moustaches, ou boxplot. Cette dernière se construit à partir des différents quartiles.
Vous avez maintenant une analyse plus compète ! Et si je vous dit que nous pouvons ajouter une autre mesure dans notre analyse ? Rendez-vous au prochain chapitre !
