Analysez deux variables quantitatives par régression linéaire
Nous avons étudié au chapitre précédent la corrélation entre 2 variables quantitatives. Allons un peu plus loin à présent avec 2 autres variables également quantitatives : attente et montant.
La variable attente (que nous allons créer très prochainement) d’une opération donne le nombre de jours écoulés entre celle-ci et la précédente opération de catégorie COURSES. Si vous faites vos courses tous les 7 jours en moyenne, alors la moyenne de attente sera de 7.
Que s’attend-on à trouver ?
En théorie, plus vous attendez pour aller faire les courses, plus vous aurez besoin d’acheter de provisions. On s’attend donc à ce que plus la valeur de attente est grande, plus la valeur du montant soit grande.
Calculez une première variable
Tout d'abord, il faut calculer la variable attente ! Voici le code permettant de créer cela :
import datetime as dt
# Selection du sous-échantillon
courses = data[data.categ == "COURSES"]
# On trie les opérations par date
courses = courses.sort_values("date_operation")
# On ramène les montants en positif
courses["montant"] = -courses["montant"]
# calcul de la variable attente
r = []
last_date = dt.datetime.now()
for i,row in courses.iterrows():
days = (row["date_operation"]-last_date).days
if days == 0:
r.append(r[-1])
else:
r.append(days)
last_date = row["date_operation"]
courses["attente"] = r
courses = courses.iloc[1:,]
# on regroupe les opérations qui ont été effectués à la même date
# (courses réalisées le même jour mais dans 2 magasins différents)
a = courses.groupby("date_operation")["montant"].sum()
b = courses.groupby("date_operation")["attente"].first()
courses = pd.DataFrame({"montant":a, "attente":b})Modélisons !
Mais nous allons faire mieux que cela : calculer le prix moyen des produits que vous consommez en 1 jour, ainsi que la vitesse à laquelle vous accumulez du stock dans vos placards ! Pour cela, nous allons utiliser un modèle. Vous allez voir, c’est très puissant.
Pour le modèle que nous allons créer, nous allons faire plusieurs suppositions. Tout d’abord, nous supposons qu’à chaque fois que vous faites les courses, vous achetez 3 types de produits :
Les produits que vous consommerez avant la prochaine fois que vous irez faire les courses (produits alimentaires, d’hygiène, etc.).
Les produits qui ne seront pas consommés durant la durée de l’étude (la durée de l’étude étant la période entre votre 1er ticket de caisse enregistré dans l’échantillon et le dernier) : ce sont vos stocks de long terme (boîtes de conserves, produits surgelés, etc.).
Les produits qui ne sont pas des consommables (ex. : une fourchette, une serpillière, etc.), que vous n’achetez que très rarement.
Ensuite, nous supposons que vous consommez chaque jour des produits, et que le prix des produits que vous consommez en 1 jour est à peu près constant.
Appelons le prix moyen des produits consommés en un jour (ceux de type 1), et le prix moyen des produits de types 2 et 3 rassemblés, que vous achetez à chaque course. Enfin, appelons le nombre de jours que vous avez attendu depuis vos dernières courses, et le montant du ticket de caisse.
Quel sera le prix de votre prochain ticket de caisse ?
Il sera égal au nombre de jours d’attente multiplié par le prix moyen ce que vous consommez en 1 jour. Mais en plus, il faut ajouter le prix moyen des produits de types 2 et 3. Ceci donne cette formule :
C'est un peu simpliste ton truc, mon prochain ticket ne vaudra pas exactement ce montant. Je ne consomme pas tous les jours exactement la même somme d'argent, et je n'achète pas à chaque fois la même quantité de stock ! Et imagine que j'aie envie de me faire plaisir en m'achetant des produits plus chers !
C'est vrai, c'est simpliste ! Cette équation n'est pas exacte. D'ailleurs, vous aurez peut-être remarqué qu'il s'agit d'une équation d'une droite (remémorez-vous les fonctions affines). Équation de droite signifie que si je prends tous les possibles compris entre (par exemple) 0 et 5, puis que je calcule tous leurs associés, avant de les placer sur un graphique avec les sur l'axe horizontal et les sur l'axe vertical, alors tous les points seront parfaitement alignés ! Essayons donc d'afficher le diagramme de dispersion avec X = attente et Y = montant, et regardons si tous les points sont alignés :
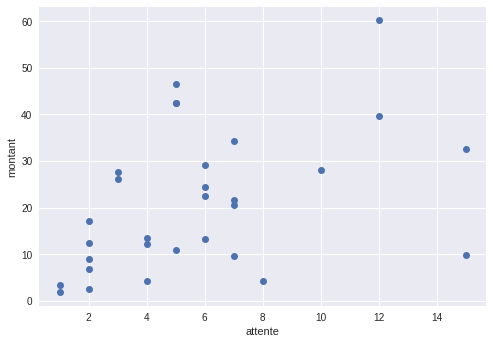
Ils sont loin d'être alignés ! Cela signifie que l'équation n'est pas tout à fait exacte : elle est simpliste. En écrivant cette équation, j’admets que je commettrai une certaine erreur entre la valeur que j'aurai prédite et la vraie valeur du prochain ticket. Mais je peux intégrer cette erreur à l'équation, en l'appelant (epsilon) :
Ce modèle est l'un des plus utilisés en statistiques. C'est la régression linéaire.
Pour calculer et , je pourrais très bien les prendre au hasard. Mais dans ce cas, l'erreur serait souvent très grande. Ce que je souhaite, c'est me tromper le moins possible. On dit que l'on cherche à minimiser l'erreur.
Graphiquement, voici comment on peut se représenter les choses. Si je fais varier et , alors je déplace la droite sur le graphique. Minimiser l'erreur revient en fait à placer la droite dans l'alignement général des points. Voici une illustration très pédagogique, car les points sont presque dans le même alignement :
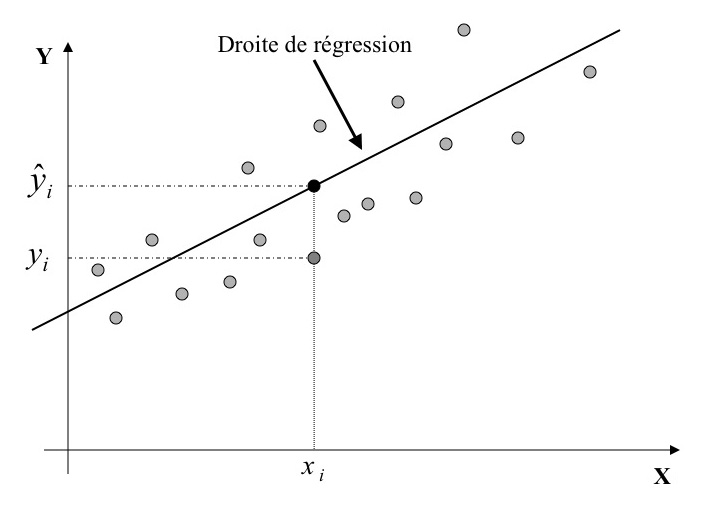
On y voit que pour un point , on cherche à ce que la différence entre le (qui est la vraie valeur) et le (qui est la valeur prédite par mon équation inexacte ) soit minimale.
Pour estimer et , l'ordinateur peut s'en charger. Pour en savoir plus, rendez-vous à la section Aller plus loin. On obtient les estimations suivantes :
Faites une estimation de et
Voici les formules qui permettent d'estimer et :
Pourquoi les chapeaux sur a et b ?
C'est une histoire d'estimation. On considère que l'on ne peut pas avoir accès directement à vos comportements de consommation caractérisés par et , mais que l'on peut tout de même les estimer grâce à vos tickets de caisse. Ces estimations de et de sont notées et .
Si on rajoute à l'échantillon un nouveau ticket de caisse, celui-ci fera varier un peu et , même si votre comportement de consommation ne bouge pas (c'est-à-dire "même si et ne bougent pas").
Comment estimer a et b avec du code ?
Voici comment faire. Le code est un peu complexe, mais retenez que la dernière ligne crée les variables a et b contenant les estimations.
import statsmodels.api as sm
Y = courses['montant']
X = courses[['attente']]
X = X.copy() # On modifiera X, on en crée donc une copie
X['intercept'] = 1.
result = sm.OLS(Y, X).fit() # OLS = Ordinary Least Square (Moindres Carrés Ordinaire)
a,b = result.params['attente'],result.params['intercept']Pourquoi y a-t-il un simple crochet ligne 2 et un double crochet ligne 3 ?
Une régression linéaire prédit une variable en fonction d'une ou plusieurs variables. sm.OLS s'attend donc à trouver une unique colonne (c.-à-d. un pd.Series ) en premier argument (ici Y), mais s'attend à trouver potentiellement plusieurs colonnes en 2nd argument (ici X, qui est un pd.DataFrame ). Pour sélectionner plusieurs colonnes d'un dataframe, on passe une liste de noms de colonnes. Et comme une liste s'écrit entre crochets, ceux-ci viennent s'ajouter aux crochets déjà présents !
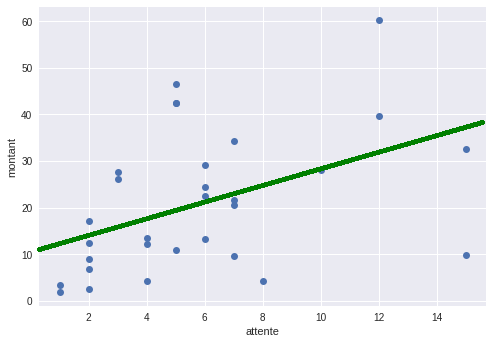
Pour afficher la droite, il faut faire comme ceci :
plt.plot(courses.attente,courses.montant, "o")
plt.plot(np.arange(15),[a*x+b for x in np.arange(15)])
plt.xlabel("attente")
plt.ylabel("montant")
plt.show()La ligne 1 affiche le graphique de dispersion.
En ligne 2, np.arange crée une liste de nombres entiers allant de 0 à 14 : [0,1,2,3,4,5,6,7,8,9,10,11,12,13,14] .
On place cette liste en abscisse. Pour chacune de ces 15 valeurs, on calcule les ordonnées grâce à la formule y=ax+b comme ceci : [a*x+b for x in np.arange(15)] . On vient donc de créer une série de points tous alignés sur la droite d'équation y=ax+b. La ligne 2 affiche tous ces points, en les reliant entre eux, ce qui nous donne une belle ligne !
Analysez la qualité du modèle
En début de chapitre, nous avons fait des suppositions. En gros, on a supposé qu'il existait un lien linéaire entre attente et montant, c'est-à-dire un lien de type . Mais cette supposition est-elle réaliste ? Après avoir appliqué un modèle, il faut toujours analyser sa qualité.
Imaginons que j'aie effacé par erreur le montant d'une opération bancaire de catégorie COURSES.
Je pourrais combler cette valeur manquante par la moyenne des montants des opérations. C'est la solution la plus basique qui soit, et vous vous imaginez qu'elle n'est pas très bonne ! Elle n'est pas très bonne car autour de la moyenne, les valeurs des montants varient, parfois de beaucoup.
Je peux alors faire mieux : je peux regarder la valeur de la variable attente de cette opération. Avec le modèle de régression linéaire que j'ai construit, je peux estimer la valeur du montant (grâce à l'équation y = ax+b). Vous vous en doutez, cette estimation sera meilleure que la précédente. En effet, quand nous avons cherché à minimiser l'erreur de modèle, nous avons en fait cherché à minimiser les variations des valeurs de montant autour de la droite de régression.
Si on avait trouvé un modèle parfait, alors il n'y aurait plus d'erreur, et donc plus de variations entre les valeurs prédites et les valeurs réelles. Dans ce cas, on dirait que le modèle a réussi à expliquer la totalité des variations. Les variations autour de la moyenne sont mesurées par la variance. Un modèle parfait aurait expliqué 100 % de la variation.
Ce pourcentage est calculé grâce à la formule de décomposition de la variance (analysis of variance, en anglais : ANOVA).
SCT (somme des carrés totale) traduit la variation totale de Y , SCE (somme des carrés expliquée) traduit la variation expliquée par le modèle et SCR (somme des carrés résiduelle) traduit la variation inexpliquée par le modèle.
Pour la régression linéaire, le pourcentage de variation expliquée est donné par le coefficient de détermination noté :
Critiquons ce résultat !
Ces résultats signifient que je ne consomme que 1.74 € par jour, cela me paraît peu ! De plus, 10.94 € de stock à chaque course, c'est énorme !
C'est vrai... à y regarder de plus près, on voit qu'il a 2 points qui "sortent du lot", on les appelle des outliers. En connaissant mes propres habitudes de consommation, je sais que je ne fais jamais les courses à plus de 15 jours d'intervalle. Ces deux points, pour lesquels attente = 15 jours, correspondent en fait à des retours de vacances (durant lesquelles je n'ai pas fait de courses). Comme je ne souhaite pas que ceux-ci interfèrent dans mon calcul, je les écarte.
Une fois écartés, j'obtiens ces nouvelles estimations :
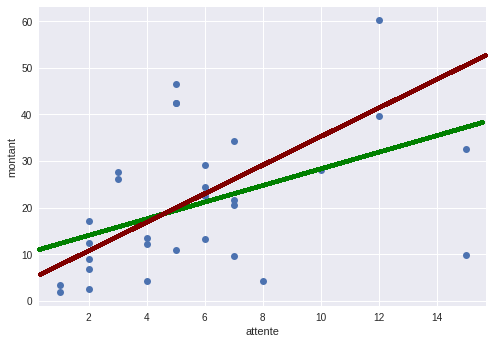
Ce résultat est bien différent du précédent. Avec seulement 2 individus écartés, les résultats changent beaucoup. On dit donc que le traitement statistique que nous venons d'appliquer (la régression linéaire avec estimation par la méthode des moindres carrés) est peu robuste aux outliers.
En résumé
Un modèle de régression linéaire est un modèle statistique qui cherche à établir une relation linéaire entre une variable, dite expliquée, et une ou plusieurs variables, dites explicatives.
La régression linéaire peut être utilisée pour comprendre les variations d'une variable mais également à des buts de prédiction.
Elle consiste dans le cas de deux variables quantitatives et , à déterminer et de sorte à obtenir l'équation suivante :
L'objectif est donc de déterminer et pour minimiser l'erreur supposée commise par notre modèle, représentée par : la méthode la plus utilisée pour cela est la méthode des moindres carrés ordinaire (MCO).
Le coefficient de détermination noté permet d'évaluer la qualité d'un modèle. Il représente le pourcentage de variation expliquée de la variable cible par notre modèle.
Partons maintenant dans l'analyse entre une variable quantitative et une variable qualitative avec ANOVA – rendez-vous au prochain chapitre !
