Modélisez les relations entre différentes entités

Modélisez les relations entre images
Découvrez le principe d’un graphe
Vous vous demandez peut-être :
Pourquoi passer des prédictions individuelles des réseaux de neurones convolutifs (CNN) à une structure de graphe ?
La réponse réside dans la nature relationnelle de vos données d'images. Dans DermaMNIST, deux images présentant des textures, couleurs ou motifs similaires (par exemple, deux kératoses actiniques avec des bordures rugueuses comparables) devraient logiquement appartenir à la même classe, même si l'une est labellisée et l'autre non.
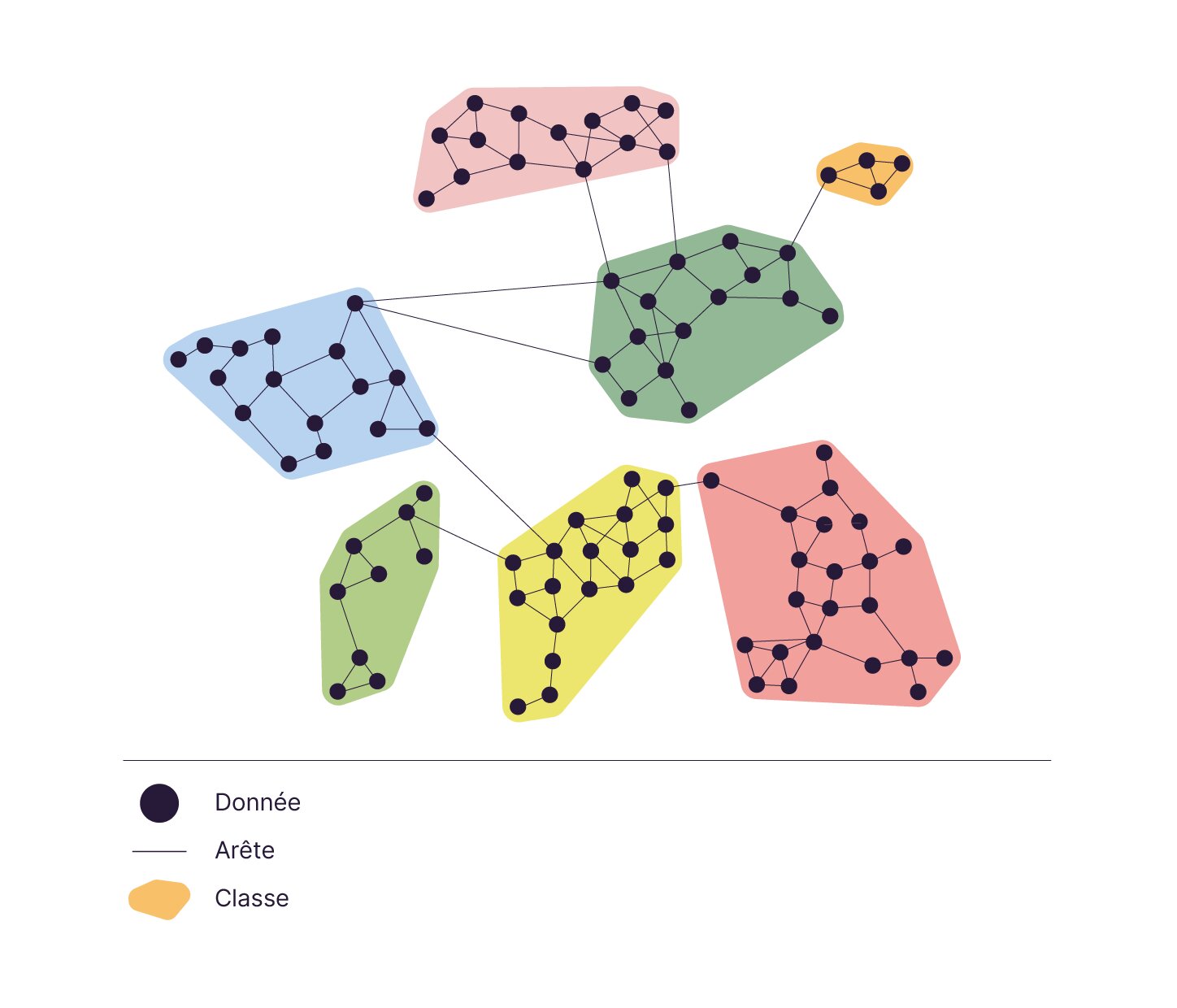
Un graphe est une structure mathématique parfaite pour capturer ces relations. Il se compose de :
Nœuds (vertices en anglais) : chaque nœud (ou point sur l’image) représente une image de votre jeu de données. Votre jeu de données comprend 350 images labellisées + 6657 images non labellisées = 7007 nœuds au total.
Arêtes (edges en anglais) : chaque arête connecte deux nœuds avec un poids représentant leur similarité (plus le poids est élevé, plus les images sont similaires)
Labels initiaux : seuls les 350 nœuds labellisés possèdent des labels connus au départ
Construction du graphe : de l'embedding aux similarités
La première étape critique consiste à représenter chaque image par un embedding (vecteur de caractéristiques de dimension réduite) qui capture ses propriétés essentielles.
Détaillons comment cela fonctionne dans la section suivante !
Propagez des labels aux nœuds non labellisés
Comment les labels se propagent-ils d’une image labellisée à une image non labellisée ?
Imaginez un réseau social où une rumeur se propage de personne à personne : ici, les rumeurs sont les labels des 350 images labellisées, et elles se diffusent vers les 6657 images non labellisées à travers les arêtes du graphe, comme les rumeurs se propageraient en les repostant.
Voici comment la propagation fonctionne :
Le processus commence par l’initialisation : les 350 nœuds labellisés conservent leur label fixe (par exemple,
1pour un mélanome,2pour un nævus), tandis que les nœuds non labellisés n’ont pas de label initial ou de distribution uniforme.À chaque itération, chaque nœud non labellisé met à jour son label probable en calculant une moyenne pondérée des labels de ses voisins, les poids étant déterminés par les similarités des arêtes. Par exemple, si une image non labellisée est fortement connectée à une image de mélanome labellisée, elle recevra une forte probabilité pour cette classe.
Dans notre implémentation, nous avons utilisé l’algorithme LabelSpreading de scikit-learn, qui automatise ce processus.
Un aspect crucial est le réglage des hyperparamètres. Par exemple :
un
ktrop faible (comme3) crée un graphe trop clairsemé, où les labels ne se propagent pas efficacement,tandis qu’un
ktrop élevé (comme20) dilue les similarités en connectant des images peu pertinentes.
Nos tests ont montré que k=7 offrait un bon compromis, avec une propagation stable mais limitée par la qualité des embeddings.
Comment éviter que des erreurs de propagation ne faussent les résultats ?
La régularisation via alpha aide à limiter la diffusion excessive, mais la qualité des embeddings reste déterminante. Si les embeddings ne distinguent pas bien les classes (par exemple, mélanomes et nævus mélanocytaires visuellement proches), la propagation peut attribuer des labels incorrects. C’est pourquoi la qualité des embeddings est toute aussi importante que l’optimisation des paramètres du LabelSpreading !
Appliquez ces concepts sur DermaMNIST : résultats et analyse
Dans nos expérimentations, nous avons extrait les embeddings à partir de la couche finale de notre CNN simple, entraîné sur les 350 images labellisées. Ces embeddings, bien que fonctionnels pour la pseudo-labellisation, se sont révélés moins adaptés à la construction d’un graphe de similarité. Après avoir construit un graphe k-NN avec k=7 et propagé les labels via LabelSpreading ( gamma=1.0 , alpha=0.2 ), nous avons obtenu les métriques suivantes sur l’ensemble de test :
AUC :
0.505(contre0.824pour la baseline supervisée,0.844pour la pseudo-labellisation)Accuracy :
0.367(contre0.489supervisé,0.605pseudo-labellisation)F1-score macro :
0.355(contre0.234supervisé,0.301pseudo-labellisation)
Ces résultats, bien que inférieurs à ceux de la pseudo-labellisation, méritent une analyse approfondie pour comprendre leurs limites et leur potentiel.
La principale raison de cette performance modeste réside dans la qualité des embeddings. Le CNN simple, entraîné sur seulement 350 images, produit des représentations qui ne capturent pas pleinement les nuances visuelles entre les sept classes de lésions cutanées, comme les différences subtiles entre un mélanome et un nævus mélanocytaire. Cela implique un graphe dont les connexions ne reflètent pas toujours les véritables relations entre classes, limitant l’efficacité de la propagation.
Un autre facteur est le faible pourcentage d’images labellisées (5% du jeu de données total). Avec seulement 350 nœuds labellisés sur 7007, la propagation dépend fortement de la connectivité de ces nœuds dans le graphe. Si certains nœuds labellisés sont mal connectés ou si les classes rares (comme les lésions vasculaires) sont sous-représentées dans les voisins proches, la diffusion des labels peut être biaisée ou insuffisante. Nos tests montrent que les classes visuellement ambiguës, comme les mélanomes, souffrent particulièrement de ce problème, ce qui explique le F1-score macro relativement stable mais modéré.
Comment améliorer ces résultats ?
Il y a plusieurs pistes d’amélioration à explorer :
utiliser un modèle pré-entraîné
ajuster les hyperparamètres du graphe
combiner pseudo-labellisation et propagation sur graphes
Piste n°1 - Utiliser un modèle pré-entraîné
Une piste prometteuse est d’utiliser un modèle pré-entraîné, comme un ResNet par exemple, pour générer des embeddings plus riches. Les modèles pré-entraînés, formés sur des jeux de données comme ImageNet, capturent des caractéristiques visuelles plus générales et discriminantes, ce qui pourrait renforcer la qualité du graphe et la précision de la propagation. Par exemple, extraire les embeddings depuis la couche average pooling de ResNet (dimension 512 ou plus) pourrait mieux distinguer les textures complexes des lésions cutanées, améliorant les connexions dans le graphe.
Piste n°2 - Ajuster les hyperparamètres du graphe
Une autre approche consiste à ajuster les hyperparamètres du graphe.
Par exemple, augmenter
kà15pourrait inclure plus de voisins, favorisant une diffusion plus large, mais au risque de connecter des images moins pertinentes.À l’inverse, réduire
kà5concentre la propagation sur les similarités locales, mais peut isoler certains nœuds.
Nos tests suggèrent que k=7 est un bon point de départ, mais des expérimentations supplémentaires sont nécessaires pour optimiser ces paramètres dans le contexte de DermaMNIST.
Piste n°3 - Combiner pseudo-labellisation et propagation sur graphes
Enfin, une stratégie hybride pourrait combiner les forces de la pseudo-labellisation et de la propagation sur graphes. Par exemple, vous pourriez utiliser les pseudo-labels les plus confiants (seuil 0.95) pour augmenter le nombre de nœuds labellisés avant la propagation, renforçant ainsi la diffusion des labels. Cette approche pourrait compenser le faible pourcentage initial de labels et améliorer les performances globales.
À vous de jouer !

Alors, vous m’avez vu venir avec mes pistes d’améliorations… ? Vous ne pensiez quand même pas que c’est moi qui allais le faire !
Allez, je récapitule le défi :
Boostez la propagation avec des embeddings ResNet
Chargez un modèle ResNet18 pré-entraîné depuis torchvision.models. Extrayez les embeddings depuis la couche
avgpool(dimension 512) pour toutes les images DermaMNIST. Reconstruisez le graphek-NNaveck=10,gamma=1.0, et appliquez la propagation avecLabelSpreading(alpha=0.2).Comparez les métriques (AUC, accuracy, F1-score macro) avec celles obtenues avec le CNN simple. Les embeddings ResNet améliorent-ils la précision de la propagation ? Analysez les différences par classe, notamment pour les lésions ambiguës comme les mélanomes.
Testez l’impact des hyperparamètres : essayez
k=5etk=15, ainsi quegamma=0.5etgamma=2.0. Quel est l’effet sur la convergence et les performances ? Visualisez les distributions des labels propagés pour détecter d’éventuels biais.Expérimentez une approche hybride : utilisez les pseudo-labels générés dans le chapitre Catégorisez l'inconnu avec la pseudo-labellisation ; (seuil
0.95) pour augmenter le nombre de nœuds labellisés (par exemple, 1000 au lieu de 350). Relancez la propagation et comparez les résultats.
En résumé
La propagation de labels sur graphes offre une approche structurelle pour l’apprentissage semi-supervisé, modélisant les images DermaMNIST comme un réseau de similarités où les labels se diffusent des 350 nœuds labellisés vers les 6657 nœuds non labellisés.
Bien que notre implémentation avec un CNN simple ait donné des résultats modestes (AUC
0.505, accuracy0.367), elle met en lumière l’importance de la qualité des embeddings et du réglage des hyperparamètres :k,gamma,alpha
Le prochain chapitre vous introduira aux SGANs, une approche encore plus créative pour exploiter les données non labellisées. Continuez à expérimenter avec méthode et précision !
