Maintenez des prédictions stables avec la régularisation par cohérence

Comprenez le principe de la régularisation par cohérence
Et si vos modèles pouvaient rester confiants même face à des changements subtils dans les données ?
Deux approches populaires incarnent cette idée :
Mean Teacher | Unsupervised Data Augmentation (UDA) |
Dans cette approche, un modèle “enseignant” (teacher) guide un modèle “étudiant” (student) en fournissant des prédictions stables, mises à jour progressivement via une moyenne exponentielle mobile (EMA) des poids de l’étudiant. | Cette approche, quant à elle, pousse cette logique plus loin en appliquant des augmentations fortes sur des données non annotées et en exigeant que les prédictions restent alignées avec celles obtenues sur des versions faiblement augmentées. |
Découvrez un cas d’usage
Prêt à élargir vos horizons ?
Jusqu’ici, nous avons exploré la classification avec DermaMNIST, mais le SSL brille aussi dans d’autres domaines, comme la segmentation d’images.
Ici, la régularisation par cohérence entre en jeu avec des augmentations intelligentes. Prenons une image de Kvasir-SEG :
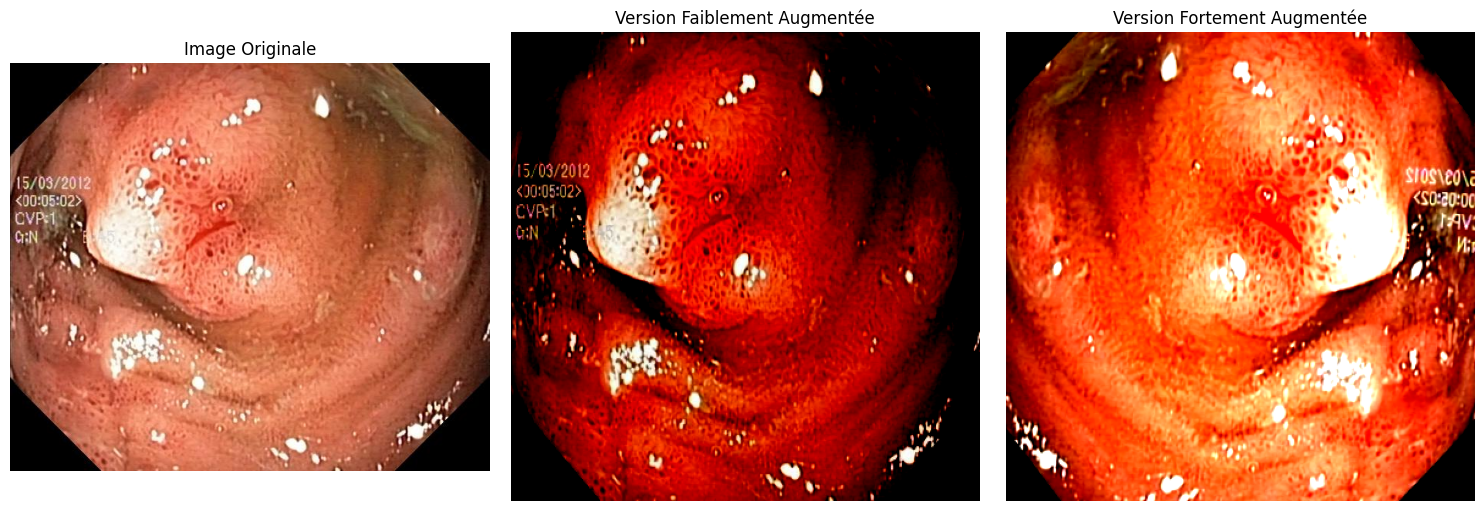
Une légère rotation ou un changement de contraste (augmentation faible) est appliqué pour l’entraînement supervisé. Sur les données non annotées, des transformations plus poussées (comme des déformations ou des ajustements de couleur) créent des versions fortement augmentées. Guidé par un enseignant stable, le modèle apprend à prédire des masques cohérents entre ces versions. Cela permet de tirer parti des nombreuses images non annotées de Kvasir-SEG pour améliorer la précision des segmentations, même avec peu d’annotations initiales.
Ce cas d’usage montre la polyvalence du SSL : qu’il s’agisse de classer des types de lésions ou de segmenter des images de polypes, les principes de cohérence s’adaptent. Cela ouvre la porte à des applications médicales variées.
Pourquoi avoir deux modèles, un étudiant qui évolue rapidement et un enseignant plus stable ?
L’étudiant (student) est entraîné de manière classique avec un optimiseur comme Adam, ce qui le rend dynamique : à chaque lot (batch), ses poids sont ajustés en fonction des pertes supervisées (sur les données annotées) et de cohérence (sur les non annotées). Cela lui permet d’explorer de nouvelles solutions, mais il peut aussi être instable, avec des fluctuations dues au bruit des gradients ou aux perturbations aléatoires des augmentations.
À l’inverse, l’enseignant est une version stable de l’étudiant : ses poids ne sont pas mis à jour par les pertes réalisées lors de la prédiction, mais par l’EMA, une moyenne pondérée des poids de l’étudiant au fil des itérations. Cela le rend stable, comme un professeur expérimenté qui filtre les variations passagères pour offrir un accompagnement fiable. Cette stabilité est essentielle en SSL : elle fournit des prédictions cohérentes pour guider l’étudiant sur les données non annotées, évitant que des erreurs temporaires ne se propagent.Une astuce géniale pour des domaines comme l’imagerie médicale, où les images varient naturellement.
Appliquez des méthodes de perturbation des données
Comment perturber les données intelligemment pour renforcer un modèle ?
Les méthodes de perturbation jouent un rôle central dans la régularisation par cohérence. Elles consistent à modifier les images de manière contrôlée pour simuler des variations réalistes, tout en préservant leur… cohérence ! Ces perturbations se divisent en deux catégories principales :
Augmentations géométriques
Augmentations photométriques
Et elles sont particulièrement adaptées à l’imagerie médicale comme Kvasir-SEG.
Augmentations géométriques | Augmentations photométriques |
Les augmentations géométriques transforment la structure spatiale des images. Par exemple, une rotation aléatoire de 10° ou un léger recadrage peut reproduire des variations d’orientation lors d’une endoscopie. Un retournement (flip) horizontal simule la symétrie des organes, tandis qu’un zoom modéré évoque des changements de focale. Ces modifications sont appliquées de façon légère pour les versions faibles (ex. ±10° de rotation) et de façon plus intensive pour les augmentations fortes (ex. ±30° avec déformation), forçant le modèle à produire des prédictions cohérentes malgré les changements de forme. | Les augmentations photométriques altèrent les propriétés visuelles. Un ajustement de luminosité ou de contraste peut imiter des différences d’éclairage en salle d’opération. Une modification de saturation reflète les variations de couleur entre patients, et un ajout de bruit gaussian reproduit des artefacts d’équipement. Comme pour les augmentations géométriques, les versions faibles sont subtiles (±10 % de contraste), tandis que les augmentations fortes amplifient ces effets (bruit plus intense, changements de teinte). Cela enseigne au modèle à ignorer les variations non essentielles. |
Par exemple, une augmentation faible pourrait combiner une rotation ±10° et un ajustement de contraste ±10 %, tandis qu’une augmentation forte pourrait inclure une rotation ±30°, un bruit gaussien et un changement de couleur. Testées sur Kvasir-SEG, les perturbations améliorent la robustesse des segmentations en simulant la variabilité réelle des images médicales.
Construisez un modèle de segmentation d'images
Ce code montre comment l’étudiant apprend sur les données annotées (perte supervisée) tout en s’alignant sur les prédictions de l’enseignant sur des versions perturbées (perte de cohérence). La mise à jour par EMA garantit que l’enseignant reste une référence stable.
Comment l’idée de régularisation par cohérence a-t-elle été mise en œuvre ?
Voyons comment le code applique cet algorithme, étape par étape :
Préparation : On prépare tout d’abord les bases :
Une moyenne glissante (EMA) pour mettre à jour l’enseignant (avec
alpha=0.99pour un changement tout doux).Les mesures d’erreur : cross-entropy (pour guider avec les images annotées) et MSE (Mean Square Error, pour vérifier la cohérence). Le réglage appelé
consistency_weight(poids de cohérence), fixé à0.1, équilibre ces deux types d’erreurs.Un optimiseur Adam pour faire progresser l’étudiant.
Boucle d’entraînement : Sur 5 tours d’entraînement (epochs, ajustables), l’étudiant est en mode actif, tandis que l’enseignant reste en observation (sans ajuster ses calculs directement avec gradients).
Perte supervisée : L’étudiant tente de deviner sur les images avec masques connus et réduit son erreur (cross-entropy) par rapport aux vraies réponses. Ça lui permet de s’appuyer sur ces rares images annotées pour bien apprendre les bases.
Perte de cohérence : L’enseignant donne ses prédictions sur des images légèrement modifiées (non annotées). L’étudiant, lui, travaille sur des versions plus transformées de ces mêmes images, et on compare leurs résultats (MSE) après un passage par une fonction
softmax. Ça pousse l’étudiant à rester constant, même face à des changements.Perte totale et mise à jour : On additionne ces erreurs avec un poids, et on ajuste l’étudiant en conséquence lors de la rétropropagation (ou backpropagation en anglais). Ensuite, la moyenne glissante (EMA) met à jour l’enseignant, rendant son apprentissage plus stable que l’étudiant en prenant la moyenne des anciens réglages de l’étudiant.
Suivi : On garde un œil sur les erreurs moyennes à chaque tour : une baisse de l’erreur de cohérence montre que l’étudiant devient plus solide face aux variations.
Vérifier les progrès : Pour voir si tout va bien, dessinez un graphique avec les erreurs sur les images annotées (epoch_sup_losses) et celles de cohérence (epoch_con_losses) à chaque tour. Si les deux diminuent régulièrement, c’est bon signe : par exemple, une erreur sur les masques qui passe de 1.5 à 0.7 prouve une meilleure prédiction, et une erreur de cohérence qui chute de 0.3 à 0.1 montre plus de résistance aux changements. Si l’erreur de cohérence saute partout, essayez de modifier les transformations ou le réglage consistency_weight.
À vous de jouer !

Vous êtes prêts à mettre la main à la pâte ?
Voici un défi pour tester la régularisation par cohérence sur Kvasir-SEG :
Variez les augmentations : Appliquez une rotation de ±15° et un ajustement de contraste de ±15 % comme une augmentation faible, puis ajoutez un bruit gaussien et une déformation pour une augmentation forte. Observez l’impact sur la perte de cohérence.
Ajustez le poids : Modifiez
consistency_weight(ex. 0.2 ou 0.05) et analysez comment cela influence la stabilité des prédictions sur les masques.Testez la convergence : Augmentez le nombre d’epochs à 10 et suivez l’évolution des pertes supervisées et de cohérence. Une diminution régulière indique un apprentissage réussi.
Appliquez une méthode hybride : Combinez les prédictions de Mean Teacher avec des pseudo-labels. Cela améliore-t-il la segmentation des images de polypes ?
En résumé
La régularisation par cohérence, via Mean Teacher ou UDA, stabilise les prédictions en s’appuyant sur des perturbations intelligentes, comme les augmentations géométriques et photométriques.
Appliquée à la segmentation de Kvasir-SEG, elle exploite les données non annotées pour affiner les masques, avec un code simple mais efficace.
Les atouts de la régularisation par cohérence sont évidents, mais son succès repose sur un ajustement prudent.
Le prochain chapitre vous permettra de vous ouvrir vers des techniques avancées comme FixMatch, FlexMatch et MixMatch. Imaginez ce que vous pourriez accomplir en mixant tout ce que vous avez vu jusqu’ici !
