Pourquoi doit-on traiter certaines données en temps réel ? Qu'est-ce qui les rend si spéciales, et pourquoi faut-il mettre en place des outils spécifiques pour les récolter et les analyser ? Pour répondre à ces questions, je vous propose de prendre pour exemple une application web standard. Il s'agit de la startup YouHouHou.com qui développe un produit permettant l'ubérisation de la transformation digitale as-a-service dans le cloud. C'est un créneau très porteur.
Les développeurs de la startup ont rapidement créé un prototype simple de l'application dont voici le schéma d'architecture :
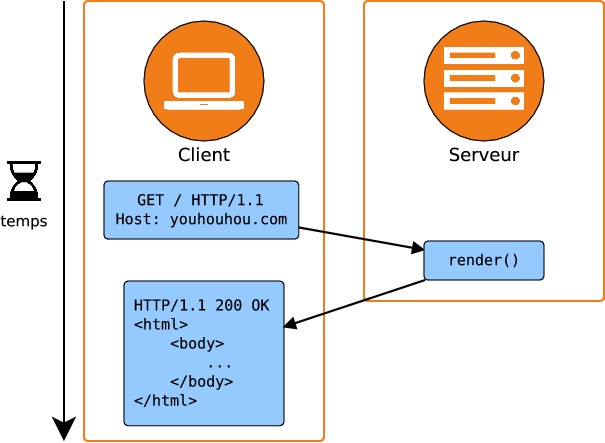
C'est un schéma de fonctionnement très classique : un client réalise une requête HTTP sur un serveur web ; le serveur web interprète la requête et renvoie une réponse correctement formatée. Cette réponse contient essentiellement le code source au format HTML de la page demandée. Ce schéma de fonctionnement est très simple et il a l'avantage de permettre au client de recevoir une réponse de manière très rapide de la part du serveur.
Quelques semaines plus tard, une interview du fondateur de YouHouHou publiée sur un site spécialisé déclenche un pic de trafic sur YouHouHou.com (je vous avais dit qu'il s'agissait d'un créneau porteur). Pour leverager une growth exponentielle, polir le funnel et faire rentrer des prospects dans le pipe du CRM, les décisionnaires de YouHouHou suggèrent de mettre en place un outil qui permette de détecter les nouvelles sources de trafic. En d'autres termes, il faut détecter les sites qui pointent vershttp://youhouhou.com, réaliser le décompte des visites pour chaque source et prévenir l'équipe communication lorsque la source est nouvelle. Pour cela, il faut examiner l'en-têteRefererde la requête HTTP.
L'équipe technique réagit rapidement et produit une solution simple consistant à stocker dans une base de données lerefererde chacune des visites. Par ailleurs, un e-mail est envoyé à l'équipe communication lorsqu'un nouveaurefererest détecté :
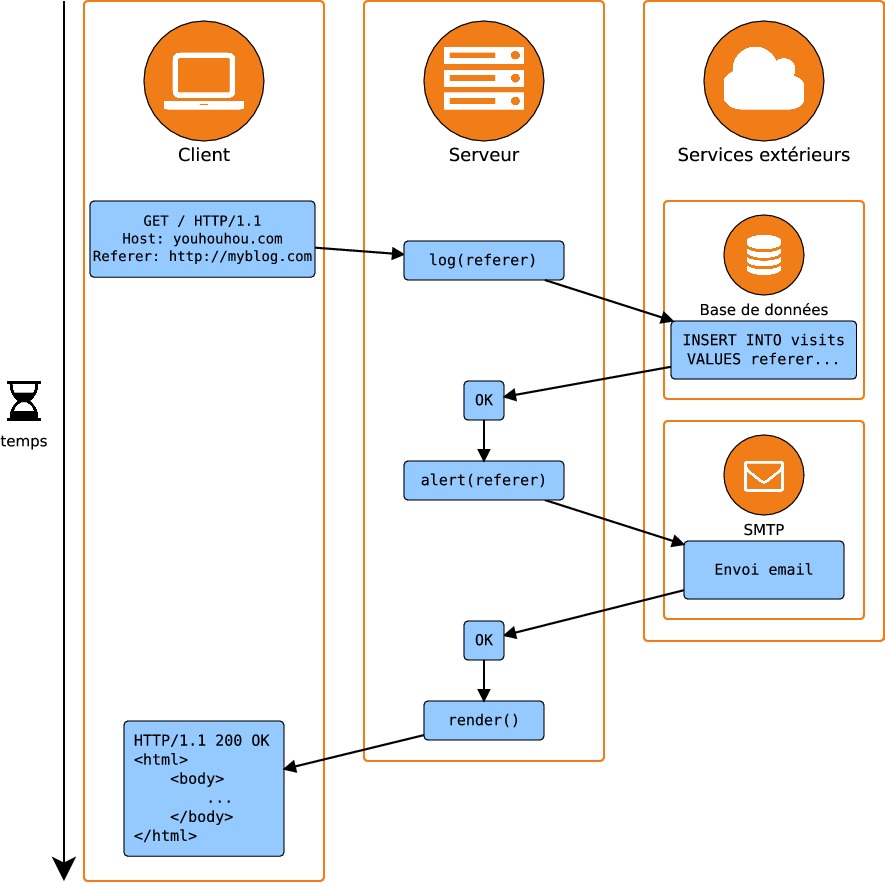
Il devient immédiatement évident que l'application répond beaucoup plus lentement qu'auparavant. Et pour cause : les clients doivent patienter pendant que sont réalisées les requêtes à la base de données et au serveur SMTP chargé de l'envoi des e-mails. Le problème est que ces requêtes à des services extérieurs sont réalisées de manière synchrone : c'est-à-dire que lors de chaque action, on attend qu'elle soit terminée avant d'entreprendre la suivante. Ceci cause une latence pour l'utilisateur.
Un second problème est celui de la fiabilité. Par exemple, que se passe-t-il si le serveur SMTP tombe en panne, ou s'il doit être redémarré ? La requête envoyée au serveur SMTP renverra une erreur et l'envoi d'e-mail sera impossible, au moins temporairement. Il y a alors trois possibilités, dont aucune n'est vraiment acceptable :
Renvoyer à l'utilisateur une erreur 500 : cette erreur indique qu'il y a eu un dysfonctionnement côté serveur et la page ne peut pas être chargée. Cela signifie que les utilisateurs ne pourront pas utiliser l'application YouHouHou lorsque le serveur SMTP est inaccessible.
Faire comme si de rien n'était en ignorant l'erreur renvoyée par le serveur SMTP et en renvoyant à l'utilisateur la page demandée : toute possibilité de prévenir l'équipe de communication est alors perdue.
Ré-essayer de joindre le serveur SMTP jusqu'à ce qu'il réponde correctement : si le serveur SMTP ne répond toujours pas au bout d'un temps T=10 secondes, abandonner et renvoyer à l'utilisateur une réponse conforme, comme dans l'option #2. Toutes les requêtes qui parviennent à l'application mettront alors au moins 10 secondes avant de se terminer, ce qui est considérable. Ce scénario est décrit dans le schéma suivant :
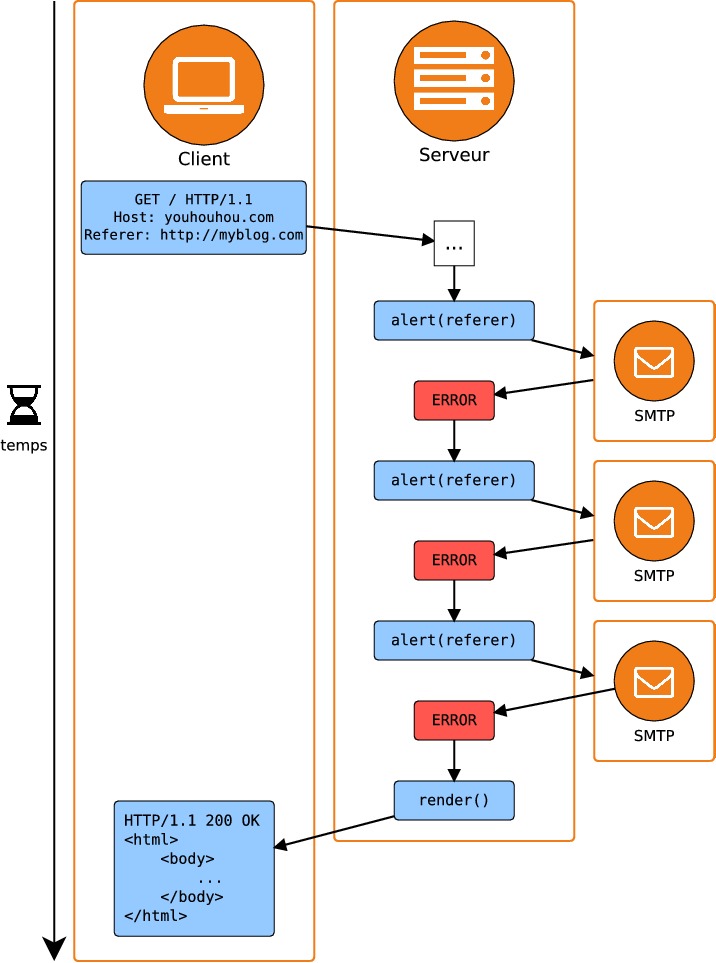
La possibilité que le serveur SMTP devienne subitement indisponible n'est pas du tout fantaisiste : lorsqu'on fait appel à des services externes, la question n'est pas de savoir si ils vont tomber en panne, mais quand. Par exemple, on peut imaginer que le serveur SMTP tombe à court d'espace disque à cause de la quantité de logs qu'il a produits — c'est un classique. Cela signifie-t-il pour autant qu'une application doit toujours être en état de bon fonctionnement, quelle que soit la panne subie ? Non, bien sûr. Il est tout à fait envisageable d'afficher une page d'erreur lorsqu'un composant critique devient indisponible, comme par exemple la base de données principale.
Cependant, dans le scénario que nous avons décrit, le serveur SMTP n'est pas un composant nécessaire à l'affichage de la page : le client se fiche complètement de savoir si l'équipe communication a correctement été informée de sa visite. Il n'est donc pas normal que sa visite déclenche un code d'erreur, ni même qu'elle subisse une latence additionnelle à cause du serveur SMTP.
Du synchrone à l'asynchrone
Peut-être avez-vous deviné quelle est la solution au problème ? Elle consiste à réaliser les appels aux services extérieurs de manière asynchrone, c'est-à-dire en parallèle à la requête réalisée par le client. Il existe plusieurs manières de réaliser cela, mais notre cahier des charges comporte deux contraintes fortes :
Les actions entreprises à la suite d'une visite doivent être exécutées avec une latence faible,
et avec une tolérance aux pannes.
La première contrainte reflète le fait que l'on a besoin d'être informés rapidement du comportement des utilisateurs de notre application. Autrement dit, il n'est pas envisageable de réaliser une tâche périodique qui analyserait les nouveaux referers, une fois par heure ou par jour. Il s'agit donc d'une approche résolument différente du traitement en "batch", que vous connaissez peut-être déjà si vous avez utilisé Apache Spark ou Hadoop (sinon, n'hésitez pas à consulter ce cours sur OpenClassrooms !). C'est la contrainte de temps réel.
Notez qu'ici, "temps réel" ne signifie pas "instantanément" : comme on l'a vu, traiter les événements instantanément se ferait au détriment de l'expérience utilisateur. Il vaut mieux comprendre "temps réel" comme : "le plus rapidement possible sans impact négatif notable sur l'expérience utilisateur". Dans le reste de ce cours, l'échelle de temps qui nous intéresse sera la seconde : on considérera que si la durée qui sépare la production d'une donnée de son exploitation est inférieure à la seconde, alors on fait bien du temps réel.
La seconde contrainte provient du fait que les données générées par la visite d'un utilisateur sont précieuses et ne doivent pas être perdues à cause de l'indisponibilité temporaire d'un composant. Cette contrainte nous empêche de lancer simplement la tâche à exécuter dans un thread d'exécution parallèle à la requête de l'utilisateur puisqu'il faut envisager le fait que cette tâche échoue, voire que le code dont elle dépende soit bogué.
La solution qui obéit à ces deux contraintes comporte deux composants supplémentaires : tout d'abord, nous avons besoin d'un composant dont la tâche va être de recevoir des messages, de les stocker puis de les redistribuer à la demande. Ce composant est une file d'attente de message (message queue). Le second composant récupère les données stockées sous forme de messages dans la file et les traite en réalisant les tâches correspondantes : c'est un système de traitement de flux de données (stream processing system).
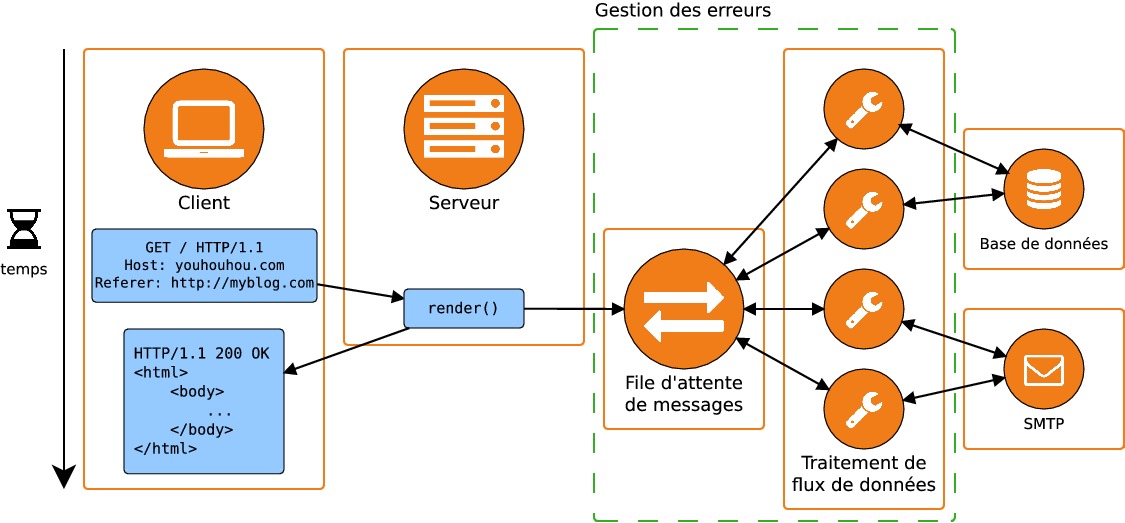
La file de messages doit répondre à plusieurs contraintes :
L'ajout de messages dans la file doit se faire avec une latence faible et qui ne dépend pas du nombre de messages déjà dans la file.
La lecture des messages doit pouvoir se faire en conservant l'ordre dans lequel les messages sont arrivés.
Pour stocker les données de manière fiable, une file de messages doit pouvoir stocker ses données de manière redondée et distribuée.
De son côté, le système de traitement des flux de données doit également obéir à des contraintes :
Chaque étape de traitement des données doit pouvoir se faire de manière distribuée de manière à passer à l'échelle avec le volume de données.
Le système de traitement de données doit avoir accès à un système de stockage (base de données, stockage de fichiers...) pour stocker le résultat des traitements.
Il faut pouvoir détecter l'échec de traitement d'un message pour adopter une réaction appropriée ; par exemple, il peut être souhaitable de tenter plusieurs fois de traiter les messages en échec.
La boîte à outil du temps réel
Dans le monde du Big Data, il existe un grand nombre d'outils qui peuvent être utilisés en tant que file d'attente de messages et système de traitement de flux. Quels sont les critères qui peuvent justifier le choix de l'un ou l'autre outil ? Pour choisir notre outil de gestion de flux de données, nous avons recherché les fonctionnalités suivantes :
Les composants choisis doivent pouvoir fonctionner avec une faible latence et de manière distribuée pour pouvoir passer facilement à l'échelle.
La file d'attente de messages doit avoir une durée de rétention des messages configurable et sans impact sur ses performances.
Afin d'être tolérant aux pannes, notre système doit disposer d'une retry policy claire.
Dans la suite de ce cours nous allons nous pencher sur Apache Kafka et Apache Storm mais il existe d'autres outils similaires. À fonctionnalités comparables, notre choix s'est porté sur ces deux outils pour des raisons liées à leur popularité auprès des data architects et des entreprises. Mais nous avons également envisagé de présenter les outils suivants :
File de messages : RabbitMQ, Apache Flume, Scribe.
Traitement de flux de données : Spark Streaming, Apache Flink, Apache Samza.
