Dans le chapitre précédent nous avons introduit le traitement de données temps réel à partir d'un exemple concret, mais il existe bien d'autres applications où le traitement de données temps réel a du sens. Je vous propose d'en découvrir quelques unes dans ce chapitre.
Agrégation de logs et supervision d'erreurs
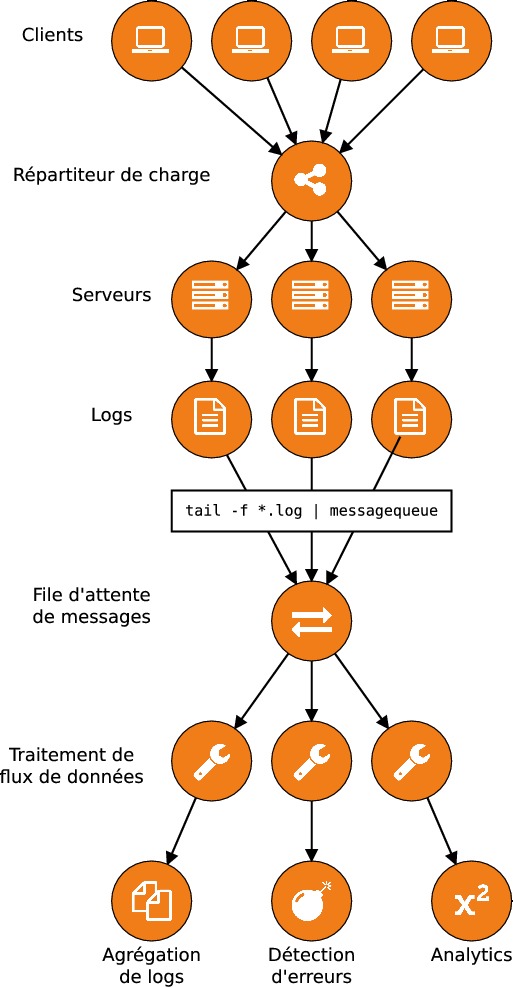
Un problème qui émerge systématiquement dans les applications distribuées est celui de l'agrégation des logs. Une application distribuée sur plusieurs serveurs génère des logs sur chacun de ces serveurs : cela signifie que pour déboguer une application distribuée, il faut examiner les logs présents sur chacun des serveurs indépendamment. Ceci peut rendre le débogage très compliqué, voire impossible à partir de plusieurs dizaines de serveurs. C'est typiquement ce qui peut se produire dans une application web dont les différents serveurs sont accessibles derrière un répartiteur de charge ("load balancer").
Pour résoudre ce problème, la première étape consiste à agréger les logs sur un seul serveur. Il existe différents outils pour réaliser cela, mais on peut tout à fait envisager de les remplacer par une file d'attente de messages. L'avantage, c'est qu'une telle file permet non seulement d'agréger des logs, mais également de les transmettre à un système de traitement de flux pour analyse. Une application classique est la détection des erreurs et l'envoi d'alertes : lorsqu'une exception est levée dans une application, la stacktrace de l'erreur est transmise par e-mail à l'équipe technique.
Le schéma de fonctionnement d'une telle architecture peut être représenté ainsi :
Déclenchement de tâches asynchrones
Certaines tâches ne doivent pas être réalisées de manière synchrone : soit parce qu'elles ne concernent pas l'utilisateur, soit parce qu'il faudrait faire patienter l'utilisateur trop longtemps avant qu'elles ne finissent de s'exécuter. C'est ce que nous avons vu dans le chapitre précédent avec l'envoi d'e-mails. Une fois qu'une file de messages et un système de traitement de flux ont été mis en place, il est possible d'exécuter un grand nombre de tâches en parallèle qui permettront d'extraire énormément de valeur des données générées sans affecter les performances de l'application principale. C'est par exemple ce qui est fait dans les plateformes d'hébergement de vidéos qui doivent mettre en place des tâches de transcodage des fichiers uploadés par les utilisateurs pour obtenir des vidéos en différentes résolutions.
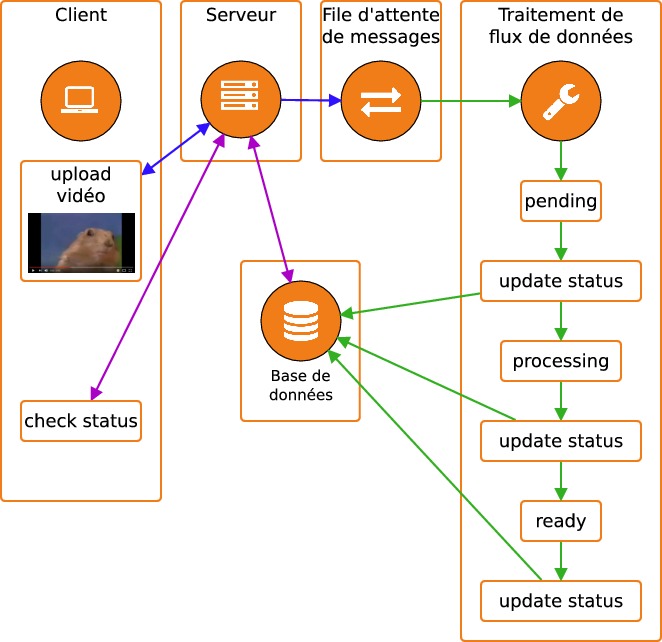
Dans ce schéma, les utilisateurs réalisent des requêtes périodiques sur le serveur pour obtenir des informations sur la progression du transcodage. Notez le rôle prépondérant de la base de données qui permet au serveur frontal de communiquer avec le système de traitement des données. Cette communication se fait de manière indirecte, puisque le traitement des données se fait dans un process séparé de celui du serveur.
Supervision
La supervision de serveurs et de clusters de serveurs est fréquemment réalisée en passant par un système de gestion de flux de données ; c'était d'ailleurs une des raisons qui ont conduit le réseau social professionnel LinkedIn à développer Kafka. Pour en savoir plus, je vous encourage à consulter cet article décrivant comment LinkedIn a déployé un système de supervision global pour mesurer en temps réel les performances de ses serveurs.
