Dans le chapitre précédent, on a vu que pour gérer des flux de données temps réel il nous fallait deux composants :
Une file de messages.
Un système de traitement de flux de données.
Dans cette partie, nous allons nous intéresser à Apache Kafka qui remplit le rôle de file de messages. En fait, Kafka est bien plus qu'une file de messages et peut être utilisé comme une plateforme complète d'échanges de données. En pratique, cela signifie que Kafka peut agir comme une plateforme distribuée qui centralise tous les messages qui transitent entre différentes applications. Pour comprendre l'utilité d'une telle plateforme, imaginons une plateforme web classique composée d'une application, d'une base de données ainsi que de quelques workers asynchrones. Le rôle des workers est d'exécuter les tâches asynchrones de la plateforme, comme l'e-mailing, et ils sont orchestrés par RabbitMQ. Les logs des différents serveurs sont aggrégés par syslog-ng. Des workers supplémentaires analysent périodiquement les logs pour générer des statistiques. Enfin, les performances (utilisation CPU, RAM disponible, espace disque) des serveurs sont collectées par statsd et envoyés vers Graphite.
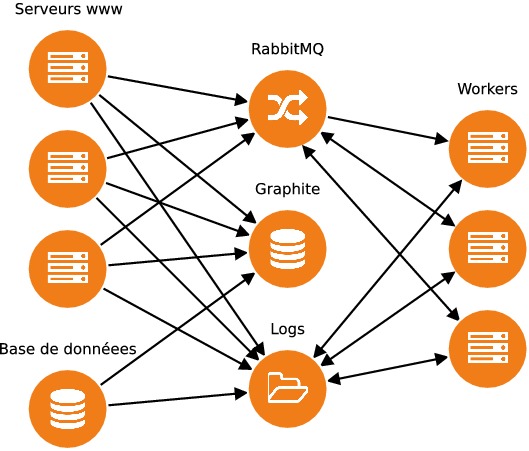
Comme on peut le voir dans le schéma d'architecture ci-dessus, plusieurs services sont chargés de recevoir des messages et de les transmettre à d'autres services. Kafka permet de centraliser les messages et de les redistribuer à une variété de services, ce qui simplifie considérablement l'architecture de l'application.
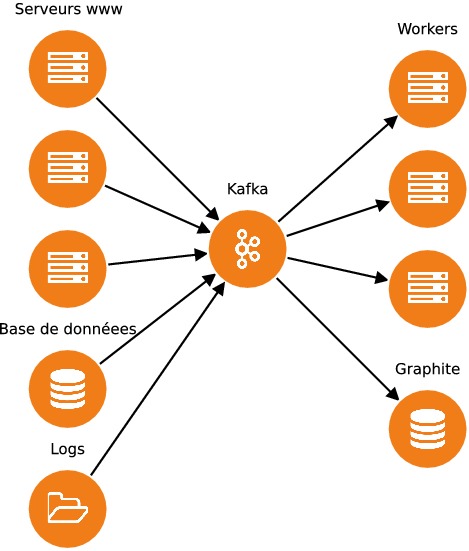
Cette partie ne va donc couvrir qu'une partie des fonctionnalités de Kafka, mais quand vous l'aurez terminée vous aurez en main toutes les clés pour aborder par vous-mêmes les sujets plus avancés.
Installation
On va commencer par installer Kafka. En fait d'installation, il suffit de télécharger et de décompresser la dernière archive contenant les binaires de Kafka sur le site dédié :
wget http://apache.crihan.fr/dist/kafka/0.10.2.1/kafka_2.10-0.10.2.1.tgz
tar xzf kafka_2.10-0.10.2.1.tgz
cd kafka_2.10-0.10.2.1/Dans le reste de ce cours nous allons utiliser la version 0.10.2.0 de Kafka qui supporte la version 2.10 de Scala.
Pour exécuter Kafka, nous avons besoin de lancer deux composants :
Zookeeper, qui est le gestionnaire de cluster de Kafka.
Un serveur Kafka que l'on nommera broker.
La version de Kafka que vous avez téléchargée inclut les binaires de Zookeeper ainsi qu'un fichier de configuration prêt à l'emploi. Pour lancer Zookeeper il suffit donc d'exécuter :
$ ./bin/zookeeper-server-start.sh ./config/zookeeper.propertiesVoici le contenu de notre fichier de configuration de Zookeeperconfig/zookeeper.properties:
dataDir=/tmp/zookeeper
clientPort=2181
maxClientCnxns=0Comme indiqué dans ce fichier de configuration, Zookeeper est un serveur avec lequel on peut communiquer sur le port 2181. On peut donc vérifier que Zookeeper a été correctement lancé avec un petit appel àtelnet:
$ telnet localhost 2181Zookeeper n'est pas notre file de messages, mais c'est un composant essentiel pour que Kafka fonctionne : en tant que gestionnaire de cluster, c'est Zookeeper qui est en charge de réaliser la synchronisation des différents éléments d'un cluster. Dans un cluster composé de plusieurs machines, les différents services passent par Zookeeper pour échanger des données et stocker leur configuration ; Zookeeper permet également la découverte de services. Vous n'aurez pas à savoir grand-chose de plus sur Zookeeper, mais vous êtes encouragés à consulter la documentation officielle ainsi que le wiki pour en apprendre plus.
Maintenant que Zookeeper est lancé, on peut lancer un serveur Kafka :
$ ./bin/kafka-server-start.sh ./config/server.propertiesLe fichier de configuration de Kafka est relativement long ; voici les clauses les plus notables :
# Identifiant de notre broker
broker.id=0
# Nom d'hôte et port sur lequel écoute le broker Kafka
listeners=PLAINTEXT://:9092
# Décommentez cette ligne pour permettre la suppression de topic, ce qui
# sera utile par la suite
delete.topic.enable=true
# Vérifiez que vous disposez de suffisamment d'espace disque sur la
# partition qui contient ce répertoire
log.dirs=/tmp/kafka-logs
num.partitions=1
# Paramètres concernant la rétention des données
log.retention.hours=168
log.segment.bytes=1073741824
log.retention.check.interval.ms=300000
# Connexion à Zookeeper
zookeeper.connect=localhost:2181
zookeeper.connection.timeout.ms=6000D'après ce fichier de configuration, Kafka écoute désormais sur le port 9092, ce qu'on peut vérifier comme précédemment avec telnet :
$ telnet localhost 9092Le consumer est roi
Avec une instance de Zookeeper et un broker Kafka qui tournent localement sur notre machine, on dispose d'un cluster Kafka minimal qui va bientôt nous permettre de transmettre des messages d'un process à un autre. Dans Kafka, les messages sont appelés des records ; les records sont regroupés par topic (sujet). Pour envoyer un message, il faut avant tout commencer par créer un topic. On crée un topic "blabla" en exécutant le scriptkafka-topics.shsitué dans le répertoirebin/de Kafka :
$ ./bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic blablaNotez que je passe à la commande des options qui indiquent le nombre de partitions et le taux de réplication du topic ; on verra plus tard à quoi ça correspond.
Je peux vérifier que mon topic "blabla" a bien été créé en listant les topics existants :
$ ./bin/kafka-topics.sh --list --zookeeper localhost:2181
__consumer_offsets
blablaOn peut également obtenir quelques propriétés du topic avec l'option--describepassée au même script :
$ ./bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic blabla
Topic:blabla PartitionCount:1 ReplicationFactor:1 Configs:
Topic: blabla Partition: 0 Leader: 0 Replicas: 0 Isr: 0La description inclut le taux de réplication et le nombre de partitions de mon topic ; pour l'instant on ne sait pas ce que c'est, mais on va en parler avant la fin de ce cours (promis !). En attendant, commençons par produire quelques messages. Dans Kafka, les messages sont produits par des producers et consommés par des consumers. Kafka propose deux outils en ligne de commande permettant de produire et de consommer des messages assez simplement.
Voici la commande pour produire des messages dans le topic "blabla" :
# Chaque ligne que vous écrirez après cette commande sera considérée comme un message
$ ./bin/kafka-console-producer.sh --broker-list localhost:9092 --topic blablaEt voici comment consommer les messages du topic "blabla" :
$ ./bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic blablaAprès avoir lancé le producer et le consumer, essayez de taper quelques messages dans l'entrée standard du producer. Ces messages devraient apparaître dans la sortie du consumer.
On reste groupier
En l'état, le consumer ne reçoit que les messages envoyés par le producer alors que le consumer est allumé. Il est possible de récupérer tous les messages envoyés dans le topic en passant l'option--from-beginning. Ceci illustre le fait que les messages sont conservés dans le topic même après avoir été consommés. En fait, ils restent dans le topic pendant 168 heures (7 jours) avant d'être effacés ; cette durée est définie par le paramètrelog.retention.hoursprésent dans le fichier de configuration de Kafka.
Mais en fait, on aimerait que le consumer traite une seule fois chacun des messages du topic "blabla" : y compris les messages émis alors que le consumer était éteint. Pour cela, il faut assigner le consumer à un groupe. Un des rôles de Kafka sera de contrôler où en est chaque groupe de consumers dans la lecture de chaque topic. Pour assigner le consumer à un groupe, il suffit de définir la propriétégroup.idau moment où l'on lance le consumer :
$ ./bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic blabla --consumer-property group.id=mygroupAprès avoir lancé ce consumer, vous pouvez vérifier que chaque message est transmis une et une seule fois au consumer, et ce même lorsque le consumer est éteint. La liste des groupes de consumers peut être obtenue à l'aide du scriptkafka-consumer-groups.sh:
$ ./bin/kafka-consumer-groups.sh --bootstrap-server localhost:9092 --list
Note: This will only show information about consumers that use the Java consumer API (non-ZooKeeper-based consumers).
mygroupDes informations plus précises peuvent être obtenues sur le groupe "mygroup" :
$ ./bin/kafka-consumer-groups.sh --bootstrap-server localhost:9092 --describe --group mygroup
Note: This will only show information about consumers that use the Java consumer API (non-ZooKeeper-based consumers).
Consumer group 'mygroup' has no active members.
TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG CONSUMER-ID HOST CLIENT-ID
blabla 0 31 34 3 - - -Dans ce cas particulier, le résultat de la commande indique que le topicblablacontient 34 messages et que le groupe "mygroup" en a consommé 31 ; il a un "lag" de 3 messages.
60 millions de consumers
Pour pouvoir passer à l'échelle et faire du Big Data, il va nous falloir plus qu'un seul consumer par topic. On a envie de réaliser des calculs de manière distribuée, donc on aimerait avoir plusieurs consumers différents, sur plusieurs machines, pour un même topic. C'est exactement pour cette raison qu'ont été conçus les groupes dans Kafka. Mais à ce stade, si on essaye de lancer un second consumer du topic "blabla" dans le groupe "mygroup", avec la même commande que précédemment, on va s'apercevoir qu'un seul des deux consumers va recevoir des messages.
Si un seul consumer reçoit des messages, c'est pour nous protéger ;) Le problème qu'on rencontre, c'est que s'il y a plusieurs consumers par partition, Kafka ne peut pas garantir que l'ordre dans lequel seront traités les messages sera le bon. Pour comprendre cette explication, il faut comprendre ce qu'est une partition.
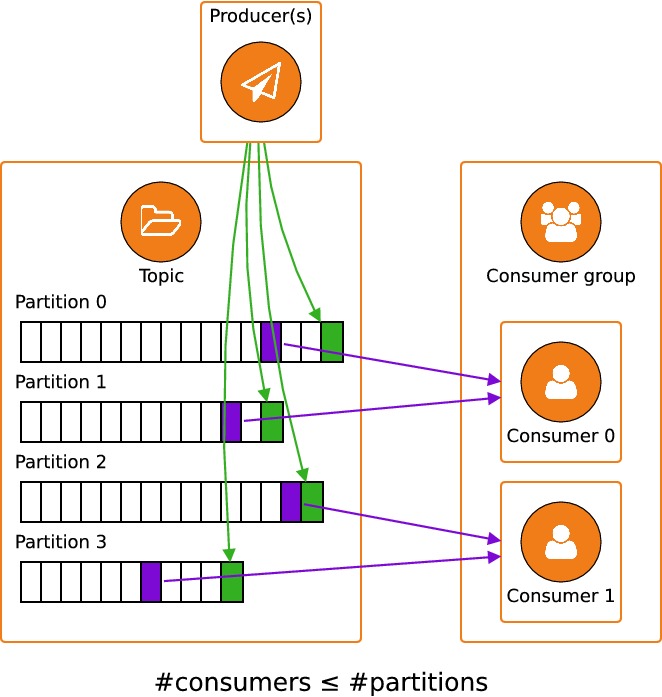
Une partition est une manière de distribuer les données d'un même topic. Lors de la création d'un topic, on indique le nombre de partitions souhaité, comme on l'a vu plus haut avec l'option--partitionspassée à la commandekafka-topics.sh --create.
Un topic peut être composé de plusieurs partitions. Chacune de ces partitions contient des messages différents. Lorsqu'un producer émet un message, c'est à lui de décider à quelle partition il l'ajoute. Ce choix d'une partition peut se faire de différentes manières, dont voici quelques exemples (non exhaustifs) :
Aléatoirement : pour chaque message, une partition est choisie au hasard. C'est ce qui est fait par notre
kafka-console-producer.Round robin : le producer itére sur les partitions les unes après les autres pour distribuer un nombre de message égal sur chaque partition.
Hashage : le producer peut choisir une partition en fonction du contenu du message. C'est une fonctionnalité que nous verrons dans le chapitre suivant.
Les messages stockés dans chaque partition sont transmis à chacun des groupes de consumers : chaque partition représente une file FIFO (premier entré, premier sorti). Pour chaque groupe de consumers, Kafka conserve en mémoire l'emplacement du curseur de lecture de chacune des partitions : l'emplacement de ce curseur est l'offset dans la partition. Stocker cette donnée ne requiert qu'unlongpar partition et par groupe, ce qui permet à un très grand nombre de groupes de consumers de lire les données en provenance de Kafka.
C'est la responsabilité des consumers de demander à Kafka de modifier leur offset dans chaque partition. Donc si l'on pouvait avoir plusieurs consumers par partition, on ne pourrait pas garantir que les messages soient traités dans le bon ordre. Pour comprendre cela, imaginons que deux consumersC1etC2tentent tous les deux de lire les messages en provenance d'une partitionP:
C1reçoit le message dont l'offset estn.C1traite le messagen.C1termine le traitement den.C1déplace le curseur de la partitionPà l'emplacementn+1.C2reçoit le message dont l'offset estn+1.
Dans ce scénario (imaginaire)C1etC2ne sont jamais occupés en même temps ; le calcul n'utilise donc pas les ressources de manière efficace. C'est pourtant la seule manière de garantir que les messages d'une même partition sont traitées dans l'ordre. Si l'étape 4 était avancée avant l'étape 2,C2pourrait commencer le traitement du messagen+1, mais on ne pourrait pas garantir que le messagen+1serait entièrement traité avant le messagen.
La conclusion est qu'il ne peut y avoir qu'un seul consumer par partition. Par contre, un même consumer peut lire des messages en provenance de plusieurs partitions différentes. Ceci peut se résumer par l'inégalité :#consumers ≤ #partitions.
Il faut noter que lorsqu'on a plusieurs partitions, pour un ou plusieurs consumers, on ne peut plus garantir que les messages seront traités dans le même ordre qu'ils sont arrivés dans le topic. Mais dans la plupart des cas on n'a besoin de respecter un ordre qu'au sein d'un groupe de messages. Par exemple, dans un centre commercial, si un client X arrive à l'heuretdans une boucherie et qu'un autre client Y arrive àt+1dans le salon de manucure d'à côté, Y n'aura pas besoin d'attendre que X ait acheté sa côte de bœuf pour se faire poser du vernis. Ce qui importe, c'est que le premier arrivé soit le premier servi dans chaque magasin.
Revenons à notre problème initial, qui est le passage à l'échelle : on conclut de notre analyse que pour augmenter le nombre de consumers, il faut aussi augmenter le nombre de partitions de notre topic. Quand on a créé le topic "blabla", on n'a créé qu'une seule partition en passant l'option--partitions 1. Pour modifier le nombre de partitions il faut exécuter la même commandekafka-topics.shavec l'option--alter:
$ ./bin/kafka-topics.sh --alter --zookeeper localhost:2181 --topic blabla --partitions 2Avec cette commande on fait passer le nombre de partition à 2. Les nouveaux messages envoyés par le producer seront alors envoyés aléatoirement à l'une ou l'autre des deux partitions ; une partition différente sera affectée à chacun des deux consumers, de manière automatique, et les deux consumers vont donc recevoir des messages différents.
