Jusqu'à présent, on a vu comment utiliser Kafka sur une machine locale : ce genre d'infrastructure est suffisante pour réaliser des tests, mais en production on va avoir besoin de plusieurs niveaux de redondances de manière à ne pas avoir un single point of failure (SPOF). Dans ce chapitre, on va voir ensemble comment distribuer les données sur plusieurs serveurs Kafka, et de manière redondante. On va également utiliser un outil d'administration doté d'une interface web pour contrôler notre cluster.
Déploiement d'un cluster distribué
En production, il est nécessaire de disposer de plusieurs serveurs Kafka. Par exemple, si l'on doit redémarrer un cluster, il vaut mieux avoir plusieurs machines que l'on redémarre l'une après l'autre de sorte que l'on n'ait pas d'interruption de service. Pour cela, il faut faire grandir notre cluster de manière horizontale. Ce n'est pas très compliqué : si vous savez déjà comment lancer un serveur (comme on l'a vu dans le chapitre précédent), alors vous savez en lancer plusieurs !
Si vous avez suivi les instructions du chapitre précédent, vous disposez déjà d'un serveur Kafka qui communique avec un serveur Zookeeper. Pour lancer un second serveur Kafka en local, il suffit de modifier sa configuration de sorte qu'elle ne rentre pas en conflit avec celle du premier serveur :
$ cd kafka_2.12-0.10.2.0/
$ cp config/server.properties config/server1.propertiesLes paramètres à modifier dansconfig/server1.propertiessont les suivants :
$ vim config/server1.properties
broker.id=1
listeners=PLAINTEXT://:9093
log.dirs=/tmp/kafka-logs-1Le paramètre
broker.idsert d'identifiant unique à notre serveur ; il doit prendre une valeur différente pour chaque serveur.L'adresse indiquée par
listenersdoit être différente de celle sur laquelle va écouter le premier serveur puisque nous faisons tourner les deux serveurs sur la même machine. Notez que si vous exécutez plusieurs serveurs Kafka sur des machines différentes, vous n'avez pas besoin de modifier ce paramètre.Le répertoire
log.dirsdans lequel le serveur Kafka stockera ses données doit être différent d'un serveur à un autre. Là non plus, vous n'aurez pas non plus à modifier ce paramètre si vous exécutez les différents serveurs Kafka sur des machines différentes.
Une fois que ce fichier de configuration a été modifié, on est prêts à lancer un second serveur en passant ce nouveau fichier de configuration en argument :
$ ./bin/kafka-server-start.sh ./config/server1.propertiesRéplication des données
Le fait d'avoir plusieurs serveurs Kafka va nous permettre de supporter la panne d'un ou plusieurs serveurs. Mais pour cela, il faut que les données soient correctement répliquées sur les différents serveurs. En effet, si une donnée n'est présente que sur un unique serveur, elle va devenir indisponible lorsque ce serveur tombera en panne ou sera redémarré.
La réplication des données est un paramètre que l'on peut ajuster lors de la création d'un topic. Dans les chapitres précédents on a utilisé l'option--replication-factor 1lors de la création de nos topics. Pour augmenter le taux de réplication d'un topic, il suffit de modifier ce paramètre :
$ ./bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 2 --partitions 10 --topic velib-stationsEn exécutant cette commande, on a créé un topic "velib-stations" doté de dix partitions et d'un taux de réplication de 2. Cela signifie que les données seront systématiquement répliquées sur deux serveurs, ce qui devrait nous prémunir contre la panne d'un serveur.
On peut vérifier que les partitions sont bien distribuées entre les serveurs avec la commande suivante :
$ ./bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic velib-stations
Topic:velib-stations PartitionCount:10 ReplicationFactor:2 Configs:
Topic: velib-stations Partition: 0 Leader: 1 Replicas: 1,0 Isr: 1,0
Topic: velib-stations Partition: 1 Leader: 0 Replicas: 0,1 Isr: 0,1
Topic: velib-stations Partition: 2 Leader: 1 Replicas: 1,0 Isr: 1,0
Topic: velib-stations Partition: 3 Leader: 0 Replicas: 0,1 Isr: 0,1
Topic: velib-stations Partition: 4 Leader: 1 Replicas: 1,0 Isr: 1,0
Topic: velib-stations Partition: 5 Leader: 0 Replicas: 0,1 Isr: 0,1
Topic: velib-stations Partition: 6 Leader: 1 Replicas: 1,0 Isr: 1,0
Topic: velib-stations Partition: 7 Leader: 0 Replicas: 0,1 Isr: 0,1
Topic: velib-stations Partition: 8 Leader: 1 Replicas: 1,0 Isr: 1,0
Topic: velib-stations Partition: 9 Leader: 0 Replicas: 0,1 Isr: 0,1Le résultat de cette commande indique que chaque partition possède un leader attitré : le leader est responsable de l'écriture des données par les producers et de la lecture des données par les consumers. Cependant, il n'est pas du ressort des producers ni des consumers d'adresser leurs requêtes au leader de chacune des partitions. Il suffit d'indiquer au producer ou au consumer l'adresse d'un ou plusieurs brokers du cluster ; les requêtes en écriture et en lecture seront automatiquement transmises au leader de chacune des partitions.
La commande ci-dessus indique également sur quel broker se trouve chacune des replicas de chaque partition ainsi que les in sync replicas (ISR). Les ISR correspondent aux replicas contenant des versions à jour des données.
Pour tester la résilience de notre nouveau cluster, il suffit d'éteindre un des brokers. Éteignons par exemple le broker 0 et exécutons à nouveau la commande précédente :
$ ./bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic velib-stations
Topic:velib-stations PartitionCount:10 ReplicationFactor:2 Configs:
Topic: velib-stations Partition: 0 Leader: 1 Replicas: 1,0 Isr: 1
Topic: velib-stations Partition: 1 Leader: 1 Replicas: 0,1 Isr: 1
Topic: velib-stations Partition: 2 Leader: 1 Replicas: 1,0 Isr: 1
Topic: velib-stations Partition: 3 Leader: 1 Replicas: 0,1 Isr: 1
Topic: velib-stations Partition: 4 Leader: 1 Replicas: 1,0 Isr: 1
Topic: velib-stations Partition: 5 Leader: 1 Replicas: 0,1 Isr: 1
Topic: velib-stations Partition: 6 Leader: 1 Replicas: 1,0 Isr: 1
Topic: velib-stations Partition: 7 Leader: 1 Replicas: 0,1 Isr: 1
Topic: velib-stations Partition: 8 Leader: 1 Replicas: 1,0 Isr: 1
Topic: velib-stations Partition: 9 Leader: 1 Replicas: 0,1 Isr: 1Comme on peut le voir, le seul broker qui fonctionne encore est maintenant le nouveau leader qui a été assigné à chacune des partitions ; celles-ci ne disposent plus qu'une d'une seule ISR. En production il s'agirait ici d'un événement "orange" (entre le rouge et le vert) : il n'y a pas eu de perte de données, mais il suffirait qu'un serveur supplémentaire soit arrêté pour rendre tout le service indisponible.
Il est possible de tester notre architecture avec notre couple de producer/consumer. Il faut simplement indiquer l'adresse de plusieurs brokers, de sorte que la production et la réception de message fonctionne même en cas de panne d'un des serveurs :
producer = KafkaProducer(bootstrap_servers=['localhost:9092', 'localhost:9093'])
consumer = KafkaConsumer(..., bootstrap_servers=['localhost:9092', 'localhost:9093'], ...)N'hésitez pas à tester un couple producer/consumer en éteignant et en rallumant alternativement l'un des deux brokers. Vous pourrez également vérifier que lorsque les deux brokers sont à nouveau fonctionnels, ils deviennent à nouveau chacun leader de la moitié des partitions. Cependant, par défaut ce changement n'intervient que toutes les cinq minutes. Pour accélérer le ré-équilibrage des partitions, vous pouvez modifier le paramètreleader.imbalance.check.interval.secondsdans le fichier de configuration des brokers.
Kafka avec des images
L'administration d'un cluster Kafka en ligne de commande peut sembler un peu... austère, disons. Vous pouvez avoir un aperçu visuel de votre cluster à l'aide de Kafka-Manager ; Kafka-Manager fournit une interface utilisateur qui permet de visualiser et de réaliser certaines tâches d'administration sans passer par la ligne de commande.
Pour installer Kafka-Manager, il est nécessaire de cloner le dépôt git correspondant :
$ git clone https://github.com/yahoo/kafka-manager.git
$ cd kafka-manager/Puis lancez le packaging :
$ ./sbt clean distVous avez le temps de prendre un café pendant que les dépendances nécessaires sont téléchargées... La dernière commande devrait générer une archivekafka-manager-1.3.3.4.zipdans le répertoiretarget/universal/. Avant de lancer Kafka Manager, il faut décompresser cette archive :
cd target/universal/
unzip kafka-manager-1.3.3.4.zip
cd kafka-manager-1.3.3.4/Kafka-Manager est prêt à être lancé en indiquant l'adresse de Zookeeper dans une variable d'environnement :
ZK_HOSTS=localhost:2181 ./bin/kafka-managerUne fois que Kafka-Manager est lancé, vous pouvez accéder à l'interface utilisateur à l'adresse http://localhost:9000. Il faudra créer un cluster dont la version de Kafka est la plus haute possible (0.10.1.0) et activer l'option "Poll consumer information". Ce cluster une fois créé, vous aurez accès à la liste des topics et des brokers
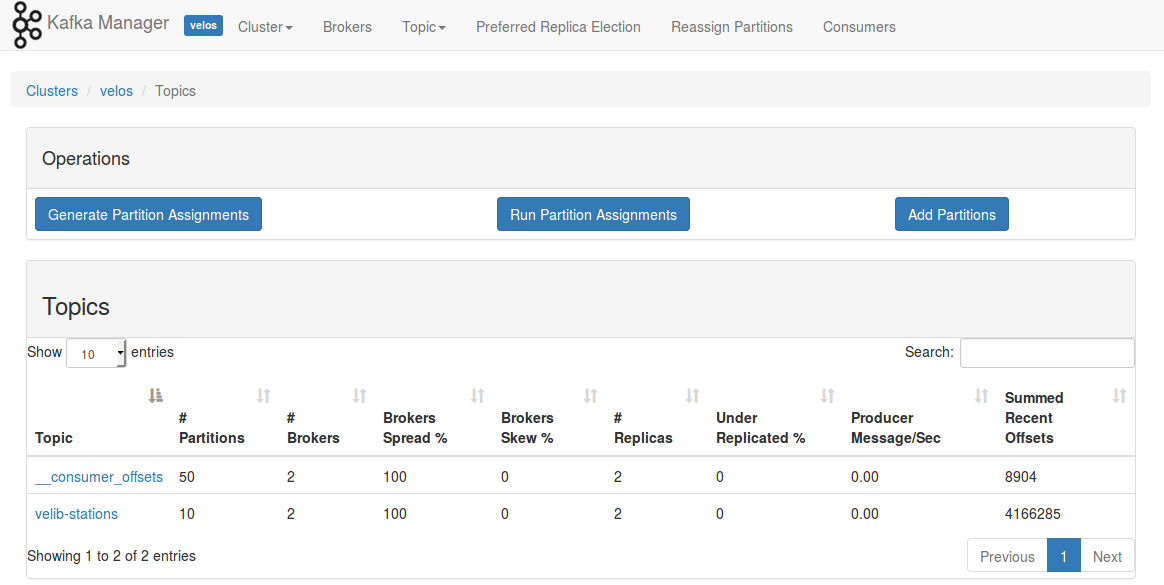
N'hésitez pas jouer avec cette interface pour découvrir ses différentes fonctionnalités !
Allez au zoo, oui, mais au zoo distribué
Le dernier composant qu'il nous reste à modifier pour pouvoir passer à l'échelle de manière fiable est Zookeeper. Jusqu'à présent, notre cluster Kafka n'a utilisé un cluster Zookeeper constitué que d'un seul nœud. Pour augmenter le nombre de serveur Zookeeper, nous allons procéder de la même manière qu'avec Kafka.
Nous allons commencer par télécharger les binaires de Zookeeper et les décompresser :
$ wget http://apache.crihan.fr/dist/zookeeper/zookeeper-3.4.10/zookeeper-3.4.10.tar.gz
$ tar xzf zookeeper-3.4.10.tar.gz
$ cd zookeeper-3.4.10/Pour chacun des serveurs Zookeeper que nous allons exécuter, nous allons créer un fichier de configuration et un répertoire contenant les données du nœud :
conf/zoo1.cfg:
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/tmp/zookeeper1
clientPort=2181
server.1=host1:2888:3888
server.2=host2:2888:3888conf/zoo2.cfg:
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/tmp/zookeeper2
clientPort=2182
server.1=host1:2888:3888
server.2=host2:2888:3888Si vous désirez exécuter plusieurs serveurs Zookeeper en local, n'oubliez pas de définir des valeurs différentes pour les paramètresdataDiretclientPort. Les paramètresserver.Xindiquent les urls des différents serveurs ; ce paramètre doit donc être le même pour tous les serveurs. Mais comment un serveur Zookeeper sait-il quelle url utiliser ? Il faut pour cela indiquer à chaque serveur quel est sont identifiant en créant le fichiermyid:
$ mkdir /tmp/zookeeper$
$ mkdir /tmp/zookeeper2
$ echo 1 > /tmp/zookeeper1/myid
$ echo 2 > /tmp/zookeeper2/myidDans l'exemple ci-dessus, il sera affecté l'identifiant 1 au serveur dont ledataDirest/tmp/zookeeper1.
On peut alors lancer les différents serveurs en exécutant :
$ ./bin/zkServer.sh start-foreground ./conf/zoo1.cfg
$ ./bin/zkServer.sh start-foreground ./conf/zoo2.cfg