Dans ce chapitre, nous allons voir comment passer d'une topologie prototypée en local à un cluster Storm où les topologies sont exécutées de manière distribuée. Notre cluster va suivre une architecture maître-esclaves classique, avec en plus un composant Zookeeper pour synchroniser les différents serveurs entre eux.
Nous allons voir que nous allons déployer nos topologies en production sans avoir à les modifier ; cela nous garantit que nos topologies se comporteront de la même manière en local et en production.
Mais avant de passer en production, nous allons créer une topologie Storm connectée à un cluster Kafka. Cela va nous permettre de découvrir comment connecter un spout Storm à un topic Kafka ; nous allons également voir comment réaliser un fenêtrage ("windowing") des données.
Vélos redux
Commençons par créer une topologie Storm sur la base de notre application de surveillance des vélos développée dans la partie précédente.
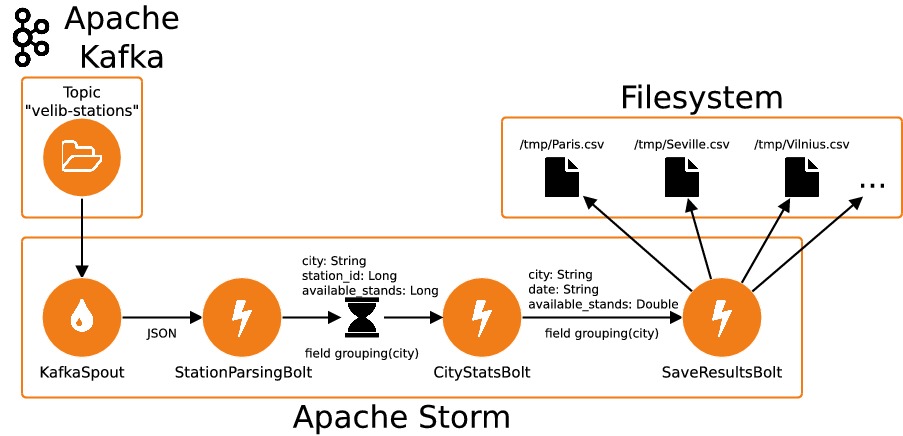
Le code de cette topologie est disponible dans le dépôt git du cours. Cette topologie contient deux nouveautés par rapport à la topologie développée dans le chapitre précédent :
Les données sont émises par un
KafkaSpoutconnecté au topicvelib-stationsd'un cluster Kafka. Pour exécuter notre topologie, on a donc besoin d'un cluster Kafka fonctionnel. Voici comment créer unKafkaSpout:public class App { public static void main( String[] args ) ... { ... // Création d'un objet KafkaSpoutConfigBuilder // On passe au constructeur l'adresse d'un broker Kafka ainsi que // le nom d'un topic KafkaSpoutConfig.Builder spoutConfigBuilder = KafkaSpoutConfig.builder("localhost:9092", "velib-stations"); // On définit ici le groupe Kafka auquel va appartenir le spout spoutConfigBuilder.setGroupId("city-stats"); // Création d'un objet KafkaSpoutConfig KafkaSpoutConfig<String, String> spoutConfig = spoutConfigBuilder.build(); // Création d'un objet KafkaSpout builder.setSpout("stations", new KafkaSpout<String, String>(spoutConfig)); ... } }
Le bolt
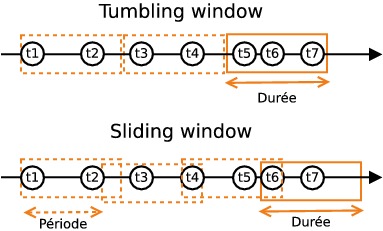
CityStatsBoltest unWindowedBolt, ce qui signifie qu'il traite des séquences de tuples, et non des tuples individuels dans la méthodeexecute. Le rôle de ce bolt est de calculer une moyenne du nombre d'emplacements libres par station et par tranche de cinq minutes. Nous avons ici créé un "tumbling window spout" configuré avec une durée de cinq minutes : la méthodeexecutedu bolt sera exécutée toutes les cinq minutes avec les tuples accumulés durant ces cinq minutes. Par opposition, un "sliding window spout" aurait eu une fenêtre glissante : toutes lesnminutes (oùnest la période de la fenêtre), la méthodeexecuteaurait été exécutée avec les tuples accumulés dans les cinq dernières minutes.
Pour soumettre notre topologie à un cluster, il suffit d'exécuter notre application en ajoutant l'option "remote" à la ligne de commande :
$ storm jar ./target/velos-1.0-SNAPSHOT.jar velos.App remoteOn utilisera alorsStormSubmitterau lieu d'unLocalClusterpour soumettre notre topologie :
public class App
{
public static void main( String[] args ) ... {
...
Config config = new Config();
config.setMessageTimeoutSecs(60*30);
String topologyName = "velos";
if(args.length > 0 && args[0].equals("remote")) {
StormSubmitter.submitTopology(topologyName, config, topology);
}
else {
LocalCluster cluster = new LocalCluster();
cluster.submitTopology(topologyName, config, topology);
}
}
}Cependant, nous avons alors besoin d'un cluster Storm en état de fonctionnement... Voyons maintenant comment lancer un tel cluster.
Lancement d'un cluster Storm
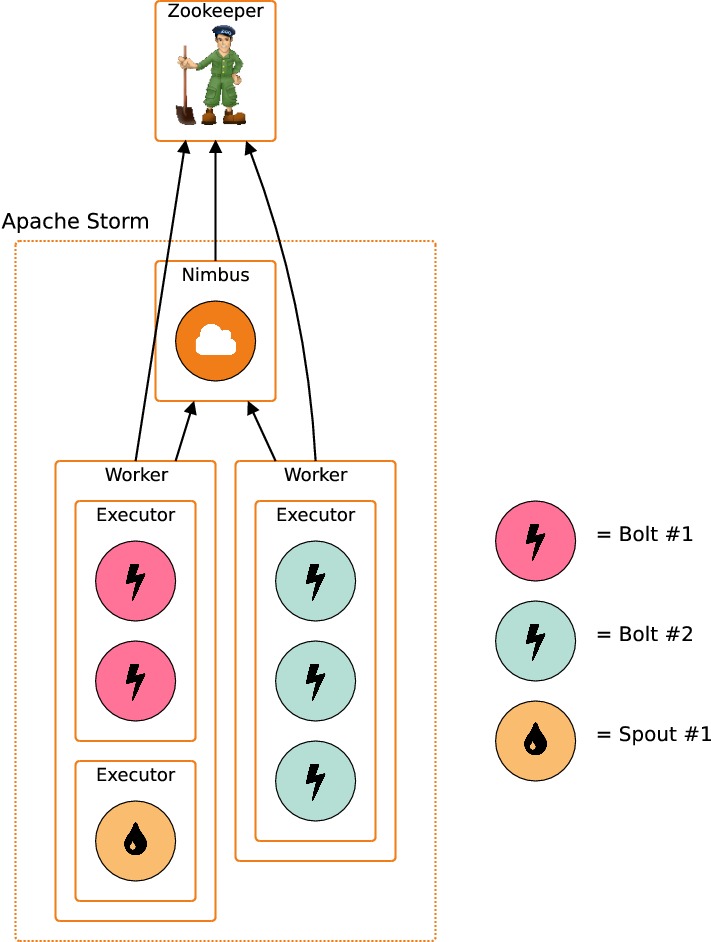
Un cluster Storm a besoin pour fonctionner de trois composants :
Un cluster Zookeeper pour réaliser la synchronisation entre les différents nœuds
Un nœud maître qui est une application appelée "Nimbus"
Des nœuds esclaves ("workers") orchestrés sur chacune des machines par un superviseur
Nous allons maintenant lancer les différents composants dans ce même ordre.
Nous commençons par lancer Zookeeper ; comme indiqué dans la partie précédente, il suffit de télécharger l'archive binaire et de l'exécuter :
$ ./bin/zkServer.sh start-foregroundNous lançons ensuite une instance de Nimbus, qui sera notre nœud maître. Pour cela, il faut modifier le fichier de configurationconf/storm.ymlpour qu'il contienne les lignes suivantes :
conf/storm.yaml:
storm.zookeeper.servers: ["localhost"]
storm.zookeeper.port: 2181
storm.local.dir: "/tmp/storm"
# Worker-specific
nimbus.seeds: ["localhost"]
supervisor.slots.ports: [6700, 6701, 6702, 6703]Les trois premières lignes seront communes à Nimbus et aux différents workers, tandis que les deux dernières ne seront utilisées que par les workers.
Pour lancer Nimbus, nous pouvons alors exécuter la commande :
$ ./bin/storm nimbusQuatre workers seront ensuite lancés (sous supervision) par la commande :
$ ./bin/storm supervisorLe nombre de workers lancés correspond au nombre de ports définis par le paramètresupervisor.slots.ports(la valeur indiquée est celle utilisée par défaut). Les workers sont lancés sous supervision, de sorte que chacun d'eux peut être redémarré en cas de plantage.
Mais à quoi correspond un worker Storm, exactement ? Chaque worker est en charge d'exécuter un sous-ensemble d'une topologie. Pour exécuter plusieurs topologies en parallèle, il faut donc plusieurs workers. Chaque workers est en charge de plusieurs executors : chaque executor est exécuté dans un thread séparé. Un executor est en charge de plusieurs tâches qui correspondent toutes au même composant (spout ou bolt). Par défaut, il y a une seule tâche par executor.
Déploiement d'une application
Maintenant que nous avons un cluster Storm et un cluster Kafka fonctionnels, on est prêts à y soumettre notre topologie. Pour cela, il faut procéder en deux temps : notre application doit d'abord être empaquetée, puis le fichier.jarcorrespondant sera envoyée au cluster Storm.
L'empaquetage de notre topologie se fait de la même manière que précédemment :
$ mvn packageCependant, il y a une différence avec l'exemple du chapitre précédent : ici, l'empaquetage donne un "fat jar", c'est-à-dire un fichier.jarqui contient toutes les dépendances nécessaires. Les dépendances que nous avons ajoutées au projet sontkafka_2.12etstorm-kafka-client, pour interagir avec Kafka. Ces dépendances doivent être ajoutées au projet, mais sans embarquer les sous-dépendanceszookeepernilog4jcar elles sont fournies au runtime par Storm. Par ailleurs, pour réaliser un "fat jar" avec Maven, nous avons besoin du plugin maven-shade-plugin. En bref, toutes ces modifications peuvent être réalisées en ajoutant du contenu à notre fichier pom.xml :
<project>
...
<dependencies>
...
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka_2.12</artifactId>
<version>0.10.2.0</version>
<exclusions>
<exclusion>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
</exclusion>
<exclusion>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-kafka-client</artifactId>
<version>1.1.0</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>3.0.0</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<artifactSet>
<excludes>
<exclude>org.apache.storm:storm-core</exclude>
<exclude>org.apache.logging.log4j</exclude>
<exclude>org.slf4j</exclude>
</excludes>
</artifactSet>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>Après avoir créé un "fat jar", on peut soumettre notre topologie au cluster à l'aide de la commande :
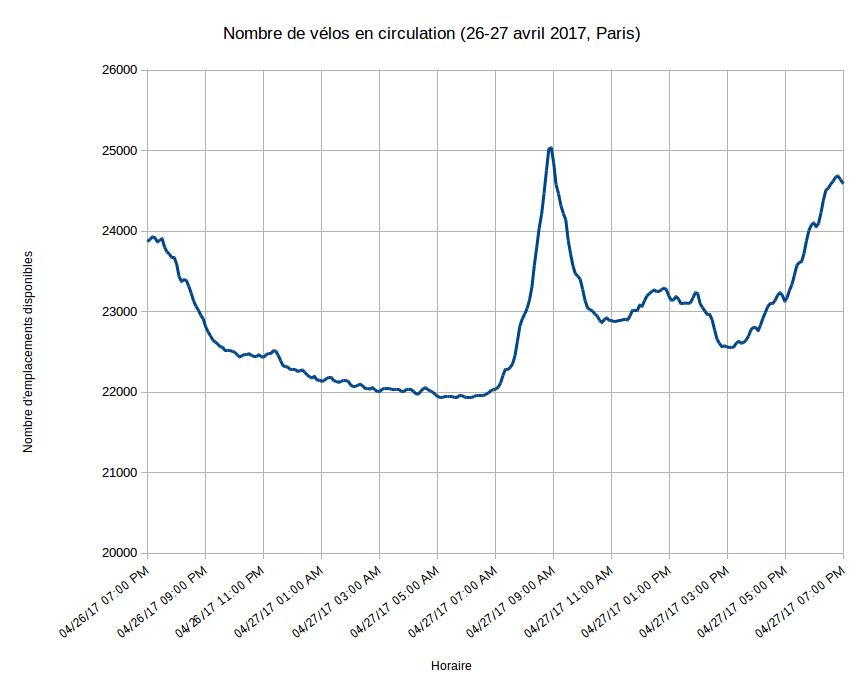
$ ./bin/storm jar ~/code/workspace/analytics/target/analytics-1.0-SNAPSHOT.jar analytics.App remoteAu bout de cinq minutes, vous devriez voir apparaître des fichiers*.csvdans le répertoire/tmpcorrespondant aux différentes villes. Libre à vous de tracer une courbe indiquant pour chaque ville le nombre de vélos en circulation en fonction du temps. Par exemple, voici les statistiques collectées sur 24h entre le 26 et le 27 avril 2017 :
Storm UI
Notre topologie devrait correctement fonctionner, ce que vous pouvez vérifier en consultant les fichiers de logs produits :
$ tail -f logs/worker-artifacts/*/*/worker.logCependant, il est assez incommode de contrôler un cluster entier en ne consultant que les fichiers de logs. Pour examiner l'état de notre cluster et la progression de chaque topologie, le mieux reste encore de passer par une interface graphique. Pour ça, Storm embarque Storm UI qui vous permet de visualiser votre cluster à partir de votre navigateur :
$ ./bin/storm uiEn exécutant la commande ci-dessus, un service web est créé sur le port 8080 qui permet de visualiser et d'administrer le cluster décrit dansconf/storm.yml. Vous pouvez y accéder en vous rendant sur la page http://localhost:8080 dans votre navigateur. Différents services sont accessibles dans Storm UI ; en particulier, voici une capture d'écran de notre topologie "velos" prise après quelques minutes de traitement :
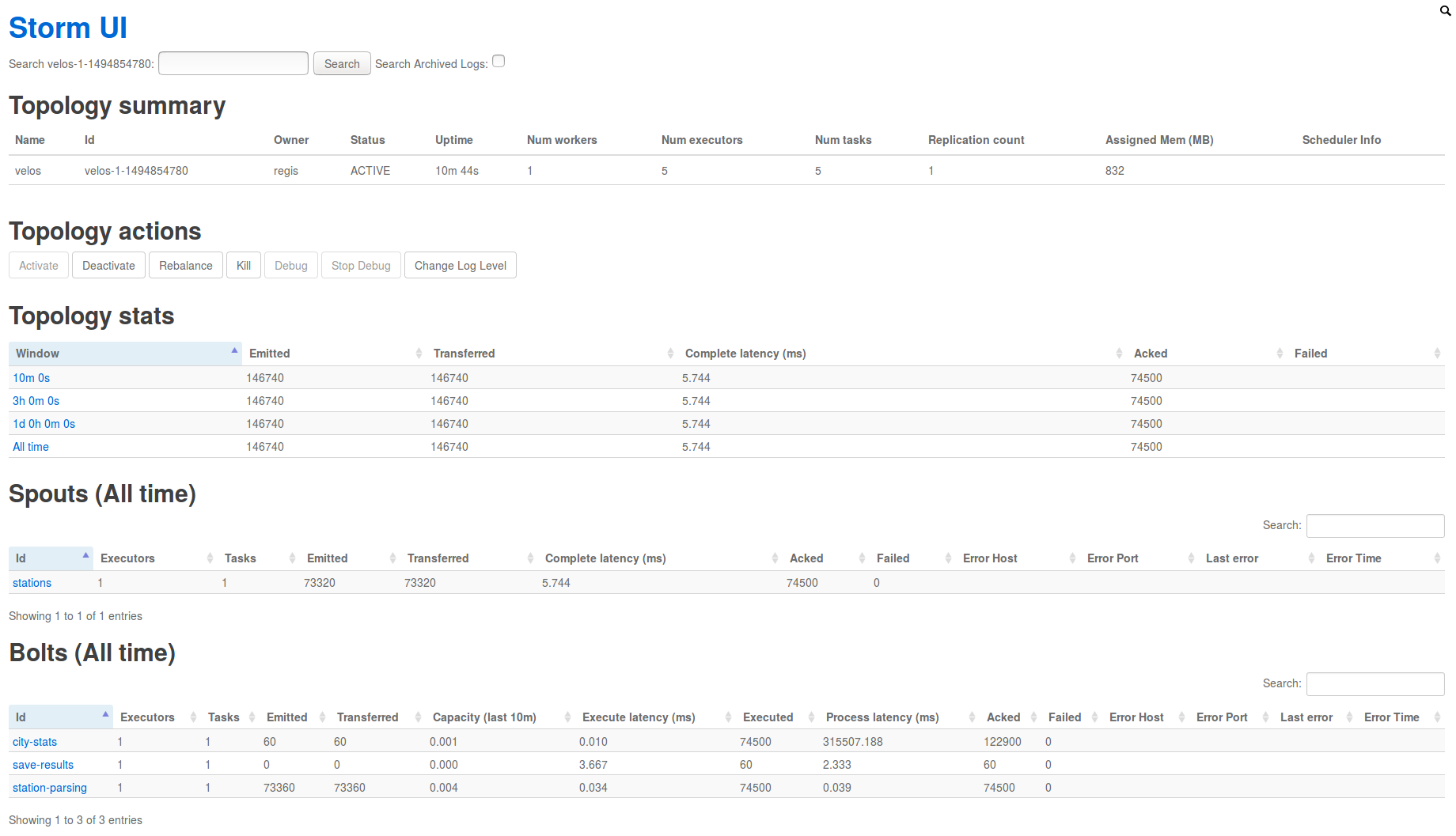
Supervision
Lancer tous ces process dans une même console peut être assez fastidieux ; d'autant que ces process doivent être lancés dans un ordre particulier et de manière supervisée (c'est-à-dire qu'ils doivent être redémarrés en cas de plantage). Pour simplifier le lancement et la supervision d'un cluster, vous pouvez utiliser supervisord, qui est un système générique de supervision de process. Pour l'installer sous Debian/Ubuntu, exécutez simplement :
$ sudo apt install supervisorPour les autres OS, consultez la documentation officielle.
Vous pouvez alors créer un fichier/etc/supervisor/conf.d/storm.confcontenant :
[group:storm]
programs=zookeeper,storm-nimbus,storm-workers,storm-ui,kafka,kafka-manager
[program:zookeeper]
command=bash ./bin/zkServer.sh start-foreground
directory=/home/regis/code/zookeeper-3.4.10
user=regis
autorestart=true
priority=990
[program:storm-nimbus]
command=bash ./bin/storm nimbus
directory=/home/username/code/apache-storm-1.1.0
user=username
autorestart=true
priority=991
[program:storm-workers]
command=bash ./bin/storm supervisor
directory=/home/username/code/apache-storm-1.1.0
user=username
autorestart=true
priority=992
[program:storm-ui]
command=bash ./bin/storm ui
directory=/home/username/code/apache-storm-1.1.0
user=username
autorestart=true
priority=992
[program:kafka]
command=bash ./bin/kafka-server-start.sh ./config/server.properties
directory=/home/username/code/kafka_2.12-0.10.2.0
user=username
autorestart=true
priority=991
[program:kafka-manager]
command=bash ./bin/kafka-manager
directory=/home/username/code/kafka-manager/target/universal/kafka-manager-1.3.3.4
environment=ZK_HOSTS="localhost:2181"
user=username
autorestart=true
priority=992(N'oubliez pas d'ajuster le chemin vers votre dépôt de code ainsi que le nom d'utilisateur)
Chargez cette nouvelle configuration en exécutant :
$ sudo supervisorctl updateVous pouvez alors lancer tous ces process d'un coup en exécutant :
# N'oubliez pas les ":" à la fin ! (pour indiquer qu'il s'agit du groupe storm)
$ sudo supervisorctl restart storm:
