Comprenez les enjeux et objectifs de ce cours
Nous nous intéressons dans ce cours à des objets connectés et plus précisément aux données générées par des objets connectés. Nous apportons une réponse à la question :
Que peut apporter la science des données, ou plus exactement les algorithmes d'apprentissage automatique (machine learning), pour les valoriser ? Ou encore, comment embarquer une composante d'intelligence artificielle (IA) dans un objet connecté ?

Oublions le GPS pour nous intéresser à l'accéléromètre et au gyroscope. Ces capteurs génèrent des signaux temporels. Un smartphone est capable de mesurer, enregistrer ou transmettre, en permanence, des accélérations selon les trois directions x, y et z, et des accélérations angulaires autour de ces trois mêmes axes. Imaginez le volume de données généré par des milliers voire des millions de ces objets connectés.
La question est alors de savoir que faire de cette masse de données, comment les valoriser. Vous pouvez par exemple installer une application "podomètre" sur votre smartphone ; pensez également à l'utilité d'un détecteur de chute pour personne dépendante ou pour un motard.
Si vous vous intéressez aux objets connectés et à la valorisation des données que ces objets peuvent générer, découvrez et comprenez dans ce cours les capacités de l'IA, et plus précisément de l'apprentissage automatique, à atteindre cet objectif. Réciproquement et plus généralement, si vous vous intéressez à l'IA, à la science des données et à l'apprentissage automatique (machine learning), et que vous voulez appliquer ces compétences à des signaux temporels complexes, suivez ce cours !
Objectif à terme
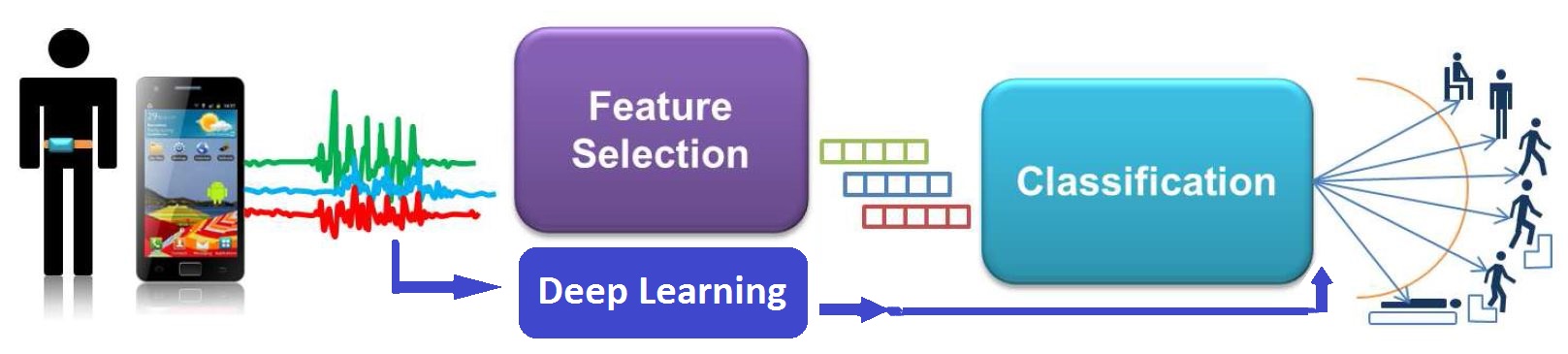
Le schéma ci-dessus résume le processus pour atteindre l'objectif visé à terme : une phase d'acquisition des signaux puis des phases aboutissant à la reconnaissance de l'activité. Plus précisément, deux stratégies sont possibles : une première stratégie à partir des signaux transformés ou une deuxième exécutée directement sur les signaux bruts.
Réalisations dans ce cours
Ce cours vous accompagne dans la réalisation des différentes étapes préparant cet objectif. Ces réalisations sont proposées sous la forme d'un tutoriel ou plus précisément d'un notebook ou calepin Jupyter écrit en Python et faisant appel aux principales librairies d'apprentissage automatique ( ) et d'apprentissage profond ou deep learning ( ).
Pour atteindre l'objectif d'identification des activités, vous allez suivre et réaliser dans les calepins différentes étapes.
Une étape préliminaire d'exploration des données est indispensable. Elle permet de découvrir les principales caractéristiques des données : signaux bruts et transformés (feature engineering) ; de les représenter, afin de pouvoir évaluer leur pouvoir discriminant, c'est-à-dire leur capacité à séparer les classes d'activités les unes des autres.
L'étape suivante est celle d'apprentissage ou entraînement des algorithmes. Deux stratégies sont mises en œuvre et comparées :
la première consiste à préalablement exécuter un ensemble de transformations de ces signaux pour en extraire des nouvelles variables ou features ; le choix de ces transformations est issu d'une expertise métier en traitement du signal. L'objectif de discrimination ou reconnaissance des activités est alors un problème de classification supervisée ou reconnaissance de forme. Cet objectif est atteint en entraînant un certain type d'algorithme d'apprentissage sur les transformations des signaux ;
la deuxième possibilité consiste à entraîner un algorithme d'apprentissage supervisé directement sur les signaux bruts. Nous verrons alors que seul un réseau de neurones profond, c'est-à-dire du deep learning, permet d'atteindre l'objectif de reconnaissance avec des résultats similaires à ceux de la première stratégie.
Bien que plus complexe au plan théorique, la réalisation de la deuxième stratégie est motivée par des questions d'économie d'énergie et en conséquence d'autonomie de la batterie. En effet, demander à un objet embarqué de calculer, en temps réel, un ensemble complexe de transformations, n'est pas réaliste. En revanche, c'est concrètement réalisé en câblant un réseau de neurones dans des puces économes dédiées à la reconnaissance d'un ou de visages, et implantées dans un appareil photo.
Expérimentation
Décrivons le processus expérimental qui a permis de constituer la base des données qui serviront à l'entraînement des algorithmes.
Elles sont le résultat d'une expérimentation détaillée :
30 volontaires ont porté un smartphone pendant des activités bien identifiées : marcher, monter ou descendre un escalier, être assis, debout ou couché ;
qu'ils ont répétées de nombreuses fois ;
pendant ce temps, 9 signaux sont enregistrés pendant une durée de 2,56 secondes : accélérations en x, y et z, accélérations corrigées de la pesanteur, accélérations angulaires en x, y et z. Les signaux sont échantillonnés à une fréquence de 50 Hz. Ce choix conduit à des séries de 128 valeurs par observation, séries qui peuvent donc être facilement traitées par un algorithme de transformée de Fourier rapide.
Cette expérimentation fournit un tableau ou data frame comportant près de 14 000 lignes et 1 152 plus une colonnes. La dernière colonne est la variable qualitative à 6 classes, variable cible ou label de l'activité. Ce data frame constitue la base d'entraînement.
Ces données sont publiques. Elles ont été acquises par Anguita et al. (2013) qui décrit très en détail le plan expérimental. Elles sont disponibles sur un site de l'université de Californie Irvine dédié à l'apprentissage automatique.
Signaux enregistrés
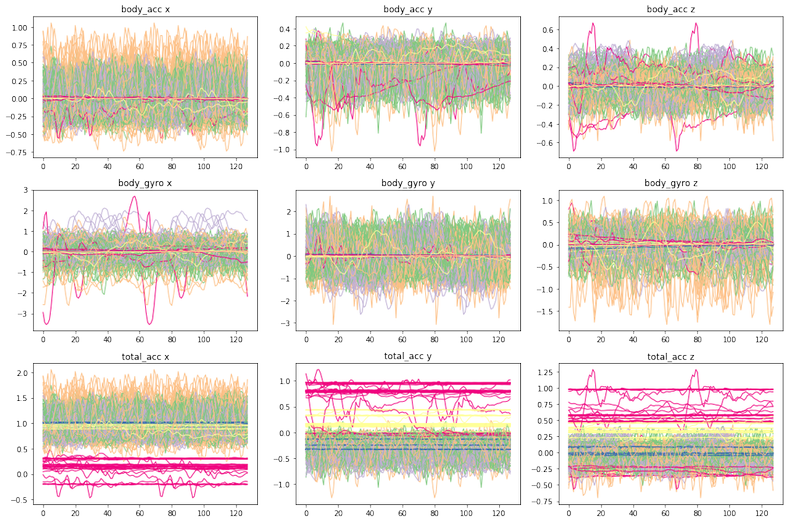
La figure ci-dessus représente ainsi l'ensemble des approximativement 14 000 signaux enregistrés pendant 2,56 secondes, échantillonnés à 50 Hz et pour chaque expérimentation. La couleur désigne l'activité. Il y a un ensemble de courbes par type de signal ou type d'accélération fourni par l'accéléromètre ou le gyroscope. Ces graphiques font surtout ressortir la complexité des données. Ce type de signal, très bruité, se retrouve dans l'observation de beaucoup de phénomènes physiques. La démarche de science des données qui suit n'est donc pas spécifique aux seules données issues de smartphones.
