Modélisez des données complexes
Les données permettant la prévision de la concentration (variable quantitative) en ozone ou de celle du dépassement du seuil (variable qualitative) ont servi à illustrer la procédure de choix de modèle par pénalisation Lasso. Voyons plus précisément à quels résultats cette approche conduit.
Prévision de la concentration en ozone
Le modèle de régression, ou plutôt la sélection des variables, a été optimisé par pénalisation Lasso et optimisation du paramètre de pénalisation par validation croisée, comme cela est expliqué dans la section précédente et opéré dans le tutoriel. La comparaison des modèles est obtenue en traçant le graphe des résidus de la prévision de l'échantillon test en fonction des valeurs prédites.
Comme prévu, les résidus du modèle Mocage se dispersent nettement plus que ceux du modèle obtenu par adaptation statistique.
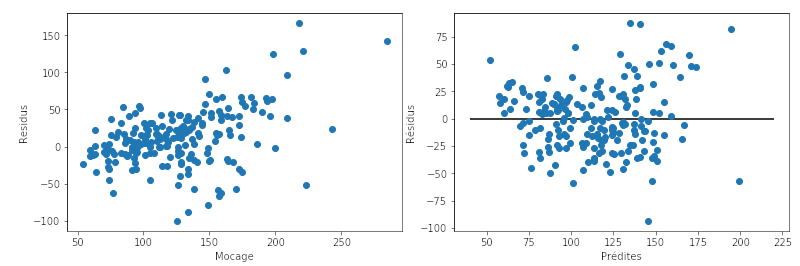
Il faut alors comparer les erreurs de prévisions ou risques estimés sur l'échantillon test : 1 565 (Mocage) est à comparer avec 859, de même que les valant respectivement et . Remarquons que l'optimisation du modèle par sélection Lasso de variable a amélioré le RMSE et le correspondants. Ils valent respectivement 871 et 0,50 pour le modèle linéaire intégrant toutes les variables sans sélection.
Il est en effet intéressant de se préoccuper des valeurs des paramètres du modèle, afin d'évaluer l'importance des variables et de comprendre leur influence sur la concentration en ozone.
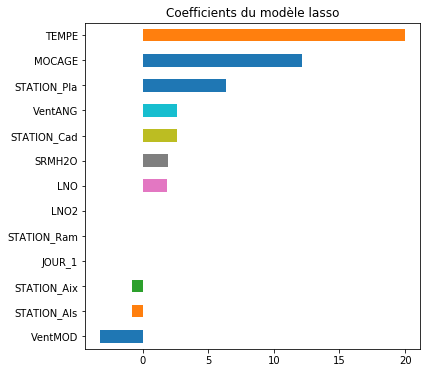
Ces paramètres montrent des différences géographiques entre les stations. La situation est plus critique à Plan-de-Cuques (banlieue nord de Marseille) qu'à Aix-en-Provence. Ils soulignent l'importance de la température dont l'influence locale est sans doute sous-estimée dans le modèle déterministe Mocage, qui joue un rôle évidemment important dans la prévision. Un vent fort tend naturellement à réduire la concentration en ozone.
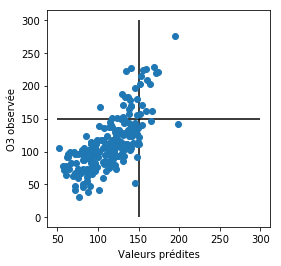
Une fois que la concentration en ozone est prévue, il est facile de voir si celle-ci dépasse le seuil légal dans le graphique ci-dessous associé à la matrice de confusion ;
| Pas de dépassement observé | Dépassement observé |
Pas de dépassement prédit | 162 | 20 |
Dépassement prédit | 5 | 13 |
Remarquer la dissymétrie de la matrice de confusion à rapprocher de la forme du nuage des résidus commentée ci-dessus. Remarquer également le nombre relativement élevé de faux négatifs : pas de dépassement prédit, alors qu'il a été observé au regard des vrais positifs. Calculer le score de Pierce à titre illustratif.
Prévision de dépassement du seuil
Les mêmes données sont utilisées pour modéliser directement le dépassement de seuil sans passer par l'étape de modélisation de la concentration. Une fois optimisé par validation croisée, le modèle conduit à une prévision similaire de l'échantillon test avec la matrice de confusion ci-dessous.
| Pas de dépassement observé | Dépassement observé |
Pas de dépassement prédit | 162 | 18 |
Dépassement prédit | 5 | 15 |
La qualité de prévision semble un peu meilleure mais, compte tenu de la faible taille de l'échantillon test, l'estimation du risque est peu fiable et les différences peu significatives. C'est la raison pour laquelle la procédure d'estimation du risque est itérée fois en considérant différentes séparations aléatoires des échantillons d'apprentissage et de test.
Cette procédure spécifique, dite de validation croisée Monte Carlo, conduit à l'estimation de erreurs de prévision ou risques pour comparer plusieurs algorithmes ou méthodes de prévision. Il est possible de calculer la moyenne de ces erreurs, une moyenne pour chaque méthode ou encore d'afficher les diagrammes boîtes des distributions de ces erreurs.
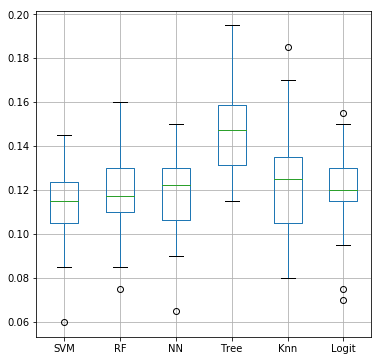
Le graphique ci-dessus compare donc plusieurs méthodes de discrimination binaire : machine à vecteurs supports, forêt aléatoire, réseau de neurones, arbre de décision, plus proches voisins et régression logistique. Même si la taille de l'échantillon test est modeste, le résultat permet de conclure que les méthodes ne conduisent pas à des résultats significativement très différents.
Nous laisserons néanmoins de côté les arbres de décision moins performants et réseaux de neurones, plus proches voisins avec des erreurs plus dispersées. Finalement, entre les SVM, un peu meilleurs mais opaques, et une régression logistique interprétable, il peut être préférable de choisir la régression logistique.
Il faudrait ajouter à ces résultats une comparaison des courbes ROC comme tracées dans la section précédente, afin de faire intervenir le choix politique du seuil de décision dans la discussion.
Reconnaissance de l'activité humaine
Un modèle, ou plutôt 6 modèles de régression logistique, sont estimés sur les données issues des transformations des signaux enregistrés par des smartphones. En effet, par défaut, la librairie estime autant de modèles que de classes lorsque la variable est qualitative avec plus de 2 classes. Comme précédemment, une pénalisation Lasso est utilisée pour opérer une sélection de variables. Chaque modèle bénéficie d'une sélection de variables spécifique mais dirigée par la même valeur du coefficient de pénalisation Lasso.
La sélection de variables ne conduit pas à un modèle simplifié : l'interprétation des coefficients des 6 modèles n'est pas raisonnablement possible. Les résultats se résument finalement à une matrice de confusion et un taux global d'erreur de moins de 4 %, ce qui est tout à fait raisonnable et en accord avec les résultats de la phase exploratoire des données.
| Marcher | Monter un escalier | Descendre un escalier | Etre assis | Etre debout | Etre couché |
Marcher | 491 | 3 | 2 | 0 | 0 | 0 |
Monter un escalier | 18 | 453 | 0 | 0 | 0 | 0 |
Descendre un escalier | 4 | 5 | 411 | 0 | 0 | 0 |
Etre assis | 0 | 4 | 0 | 430 | 56 | 1 |
Etre debout | 2 | 0 | 0 | 12 | 518 | 0 |
Etre couché | 0 | 0 | 0 | 0 | 0 | 537 |
Deux activités : assis vs. debout restent difficiles à discriminer.
