Explorez des données complexes
ACP de données de pollution
Besse et al. (2007) considèrent un jeu de données observées dans le contexte de la prévision, pour le lendemain, de la concentration en ozone dans différentes agglomérations, afin d'évaluer les risques de dépassement du seuil légal.
Le problème peut être considéré :
comme un cas de régression : la variable à prévoir est une concentration en ozone ;
mais également comme une discrimination binaire : dépassement ou non du seuil légal.
Il n'y a que 8 variables explicatives dont une ( ) est déjà une prévision de concentration d'ozone mais obtenue par un modèle déterministe de mécanique des fluides (équations de Navier et Stockes). Il s'agit d'un exemple d'adaptation statistique. La prévision déterministe sur la base d'un maillage global (30 km) est améliorée localement, à l'échelle d'une ville, par un modèle statistique incluant cette prévision ainsi que des informations connues sur la base d'une grille locale, spatiale et temporelle plus fine :
: le type de jour, férié ou non ;
: la concentration d'ozone effectivement observée le lendemain à 17 h locales, correspondant souvent au maximum de pollution observée ;
: prévision de cette pollution obtenue par un modèle déterministe de mécanique des fluides (équation de Navier et Stockes) ;
: température prévue par Météo France pour le lendemain 17 h ;
: rapport d'humidité ;
: concentration en dioxyde d'azote ;
: concentration en monoxyde d'azote ;
: lieu de l'observation : Aix-en-Provence, Rambouillet, Munchhausen, Cadarache et Plan de Cuques ;
: force du vent ;
: orientation du vent.
L'étude préliminaire rudimentaire a conduit à la transformation () de certaines variables de concentration (cf. ). Les données sont résumées par leur représentation dans le premier plan de l'analyse en composantes principales réduites.
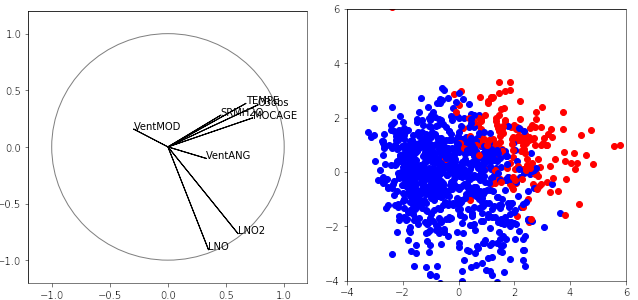
Ce graphique résume la structure de corrélation assez intuitive des variables. Un premier groupe (température, mocage, rapport d'humidité) est corrélé et concourt à la concentration en ozone. Deux autres variables liées à la concentration en oxyde d'azote sont également corrélées entre elles et avec le premier axe, mais décorrélées du premier groupe.
Enfin, les variables décrivant le vent sont mal représentées dans le premier plan et liées avec le 3 axe. Le graphique des individus à droite met en évidence les difficultés à venir pour discriminer les deux classes respectivement colorées en rouge et bleu : présence ou non d'un pic de concentration avec dépassement du seuil légal.
En présence d'une variable qualitative à deux classes, l'AFD qui se réduit à un graphe de dimension 1, défini par l'axe reliant les deux barycentres, n'a que peu d'intérêt.
ACP des transformations des signaux
Appliquons les deux méthodes d'exploration multidimensionnelle aux données obtenues après transformation des signaux temporels issus d'un smartphone, d'abord avec l'ACP en considérant seulement les données issues des signaux, puis avec l'AFD en ajoutant la variable qualitative correspondant au type d'activité (debout, assis, couché...).
L'ACP prend tout son sens lorsqu'elle est appliquée à des données de très grande dimension ; variables ou caractéristiques sont observées ou plutôt calculées à partir des signaux bruts sur individus, ou plutôt expérimentations d'une activité. Le tutoriel réalise tous les calculs en Python pour représenter l'analyse en composantes principales réduites, puis l'AFD de ces données.
Décroissance des valeurs propres
Une première information est fournie par la décroissance des valeurs propres, c'est-à-dire par la décroissance des variances de chaque variable principale. Un graphique spécifique précise les choses en opérant des diagrammes boîtes parallèles des composantes principales.
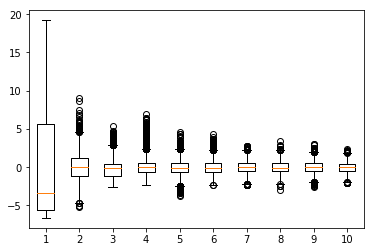
De gauche à droite, chaque diagramme boîte représente la distribution de chaque composante principale, ici, les 10 premières des 561 composantes. La première composante de plus grande variance est associée à une grande boîte accompagnée d'une grande moustache puis, la variance décroissant, les boîtes deviennent de plus en plus petites.
Noter la présence de nombreuses valeurs atypiques. Nous nous limiterons aux trois premières composantes, considérant ensuite que les composantes de boîte trop petite ne sont associées qu'à du bruit sans information pour distinguer les activités.
Représentation des variables
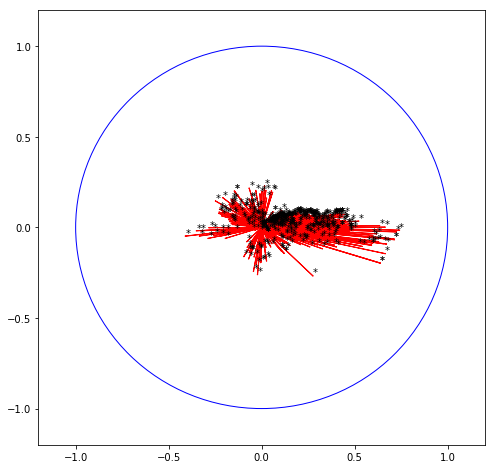
Lorsque le nombre de variables est raisonnable, la représentation de celles-ci dans le premier plan factoriel aide à comprendre la structure de corrélation. Avec trop grand, cette représentation est inexploitable.
Représentation des individus
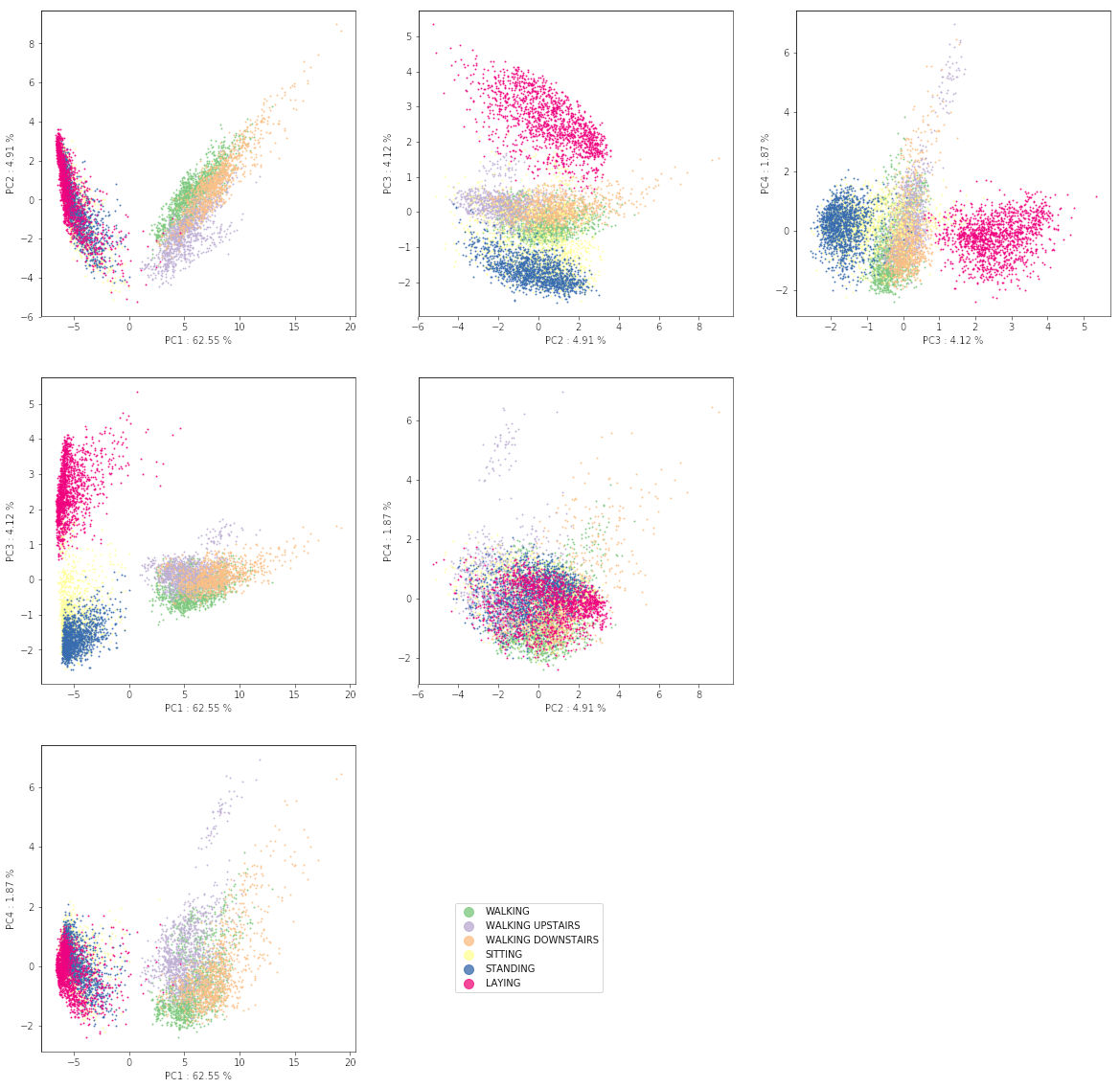
En revanche, il est très informatif de représenter chacune des 6 activités dans les trois premiers axes factoriels, en associant une couleur à chaque activité. Il apparaît que, même sans savoir qu'il y a 6 types de données, les activités se distinguent assez naturellement. Plus précisément, deux groupes d'activités : dynamique ou statique, sont clairement distingués, expliquant ainsi la grande variance du premier axe.
Néanmoins, il apparaît comme difficile de séparer, discriminer nettement certains couples d'activités.
AFD des transformations des signaux
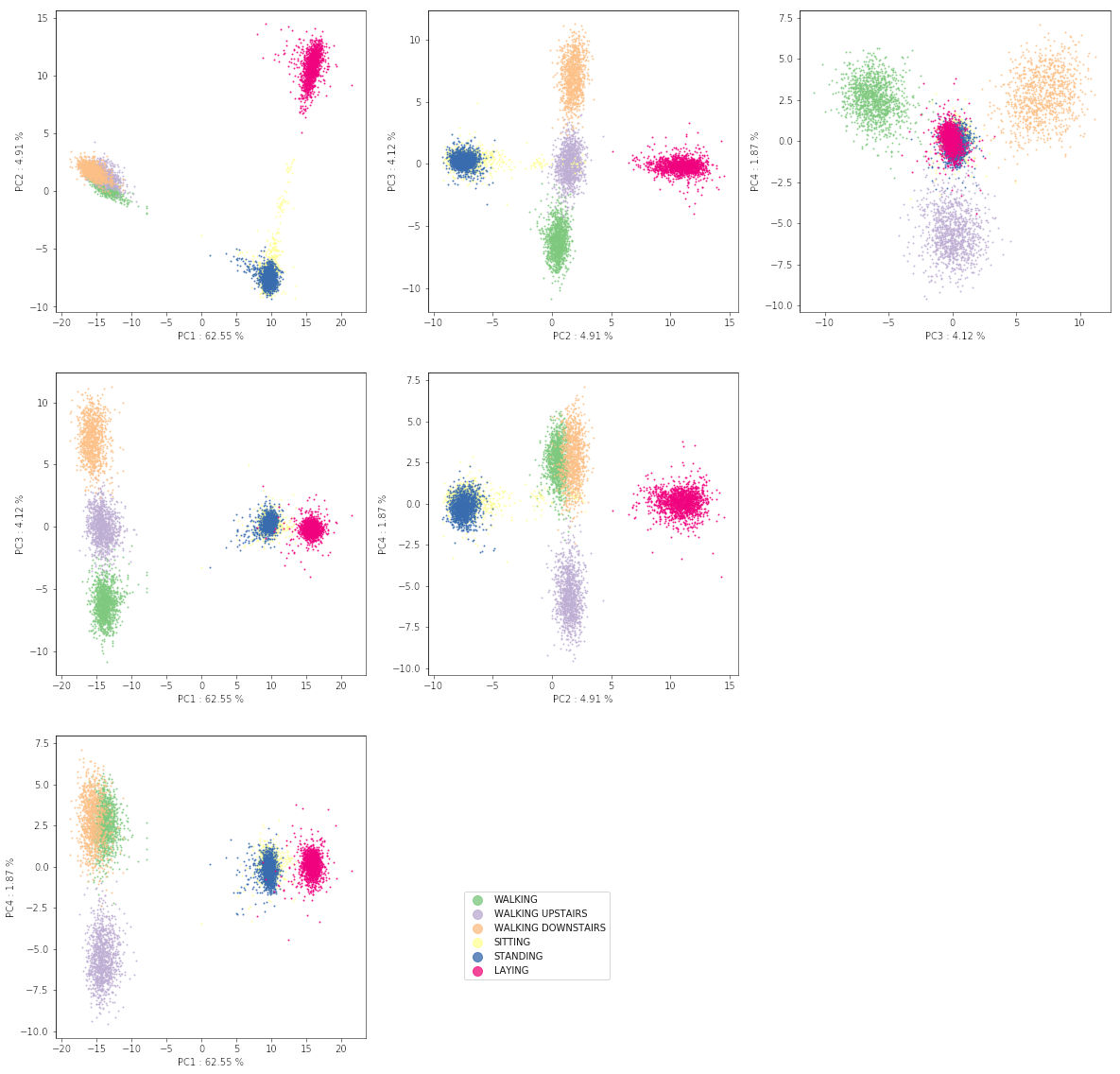
La couleur d'un point est fonction de l'activité connue. L'ACP des 6 barycentres des classes en utilisant la métrique de Mahalanobis (matrice inverse de la variance intra-classe) a pour effet d'encore mieux séparer les 6 classes. En considérant les trois premiers axes ou plutôt les projections sur les plans définis par ces trois premiers axes, il apparaît que les classes d'activités sont bien séparées dans cet espace à 3 dimensions. À l'exception des deux classes : assis, couché, plus difficiles à séparer, il existe un plan de projection dans lequel une classe se distingue des autres. Autrement dit, il existe des hyperplans ou séparations linéaires des classes.
La construction de ces hyperplans, frontières entre les classes, est l'objectif implicite de la prochaine partie. Leur connaissance conduit à des règles de décision pour la prévision d'une activité dont les signaux, ou plutôt les caractéristiques, sont connues mais pas la classe.
