Améliorez le modèle

Dans ce chapitre nous allons plonger dans la recherche des meilleurs paramètres d'un modèle, dans le but d'accroître ses performances.
On a beaucoup parlé jusqu'à maintenant d'optimisation des modèles sans montrer en quoi cela consistait exactement. En effet, les modèles de régression linéaire et logistique n'ont pas de paramètres. Dans une régression linéaire tout dépend des prédicteurs utilisés. Il est donc impossible de jouer sur leurs paramètres pour améliorer leur performance.
Reconnaissez un modèle qui sous-performe
Nous avons vu tout au début de ce cours, au chapitre 2, partie 1, que pour évaluer les performances d'un modèle, on scinde le dataset en 2 sous-ensembles (entraînement et test) et que l'on évalue la performance d'un modèle par son score sur le sous-ensemble de test.
Dans la suite, on note score(train) et score(test) les scores du modèle sur les données d'entraînement et de test.
Le calcul du score sur les données d'entraînement et de test vont nous permettre de distinguer un bon modèle d'un mauvais modèle.
Le modèle ne comprend rien aux données.
Sonscore(train)est faible, il n'arrive simplement pas à comprendre les données d'entraînement. Conséquence directe, les données de test seront aussi incomprises, donc lescore(test)sera faible. On parle dans ce cas de biais du modèle.Le modèle est bon et sait généraliser.
Lesscore(train)etscore(test)sont satisfaisants. Youhou ! Your job is done. Prochaine étape : la production.Le modèle ne sait pas généraliser.
Lescore(train)est bon mais lescore(test)est faible. Le modèle colle trop aux données d'apprentissage et ne sait pas extrapoler aux données qu'il n'a pas rencontrées.
On peut illustrer ces 3 cas par la figure suivante :
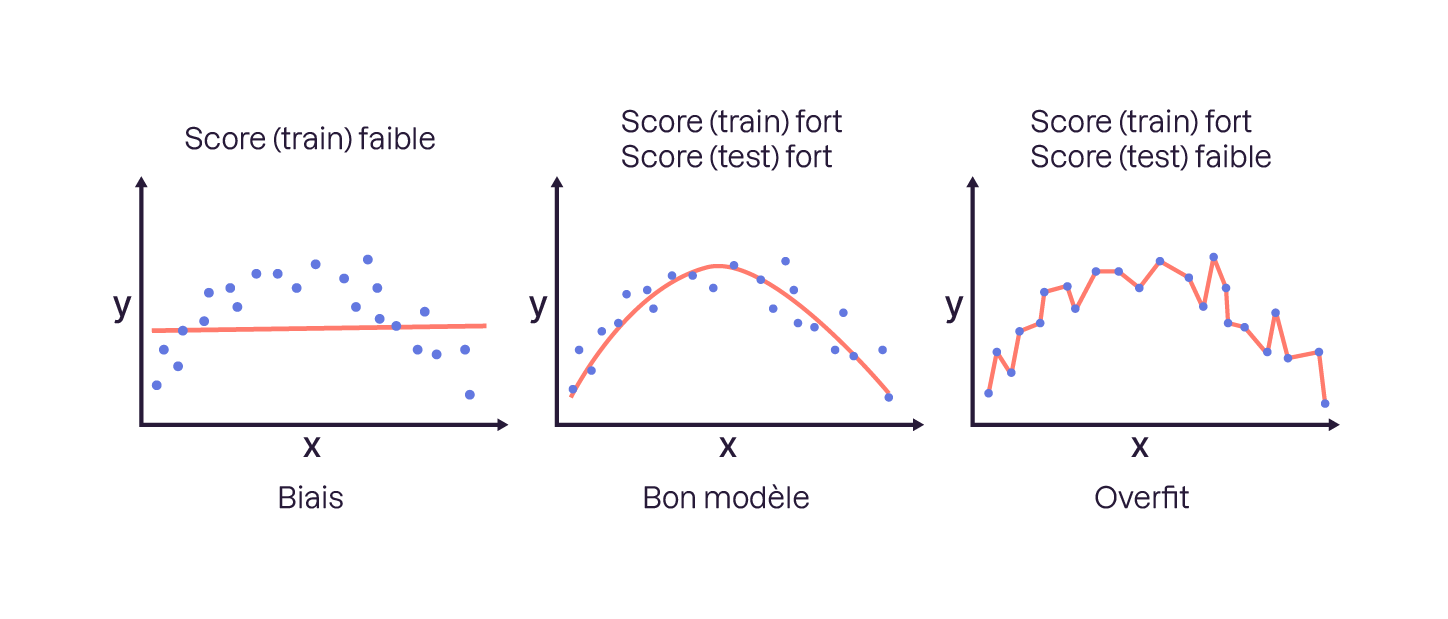
(Il existe encore un dernier cas : bon score(test) mais mauvais score(train). Il reflète la plupart du temps une anomalie statistique et arrive très rarement. On ne le prend pas en compte.)
Nous allons illustrer tout cela ainsi que les remèdes potentiels pour pallier les faiblesses du modèle en biais ou en overfit.
Mais avant, fourbissons nos armes. Il nous faut un dataset et un modèle qui dépendent de paramètres.
Nous allons construire un modèle qui prédit le stade de développement de l'arbre.
Un cas de classification a 4 catégories que nous avons déjà vues :
Jeune (arbre)Jeune (arbre)AdulteAdulteMature
Dans le dataset, ces catégories sont numérisées en 1, 2, 3 et 4.
Pourquoi prendre un arbre de décision ?
Simplement parce que ce type de modèle se prête parfaitement à la démonstration d'overfitting et de biais. Les modèles linéaires de régression sont incapables d'overfitter autrement que sur des jeux de données de démonstrations, et le k-means serait peu réaliste dans notre contexte.
Comprenez la notion d’arbre de décision
Un arbre de décision est un enchaînement de règles de classification établies automatiquement à partir des variables prédictrices.
On peut représenter un arbre graphiquement comme un arbre renversé. Pour l'instant nous nous contenterons de cette introduction simple.
Voici un exemple :
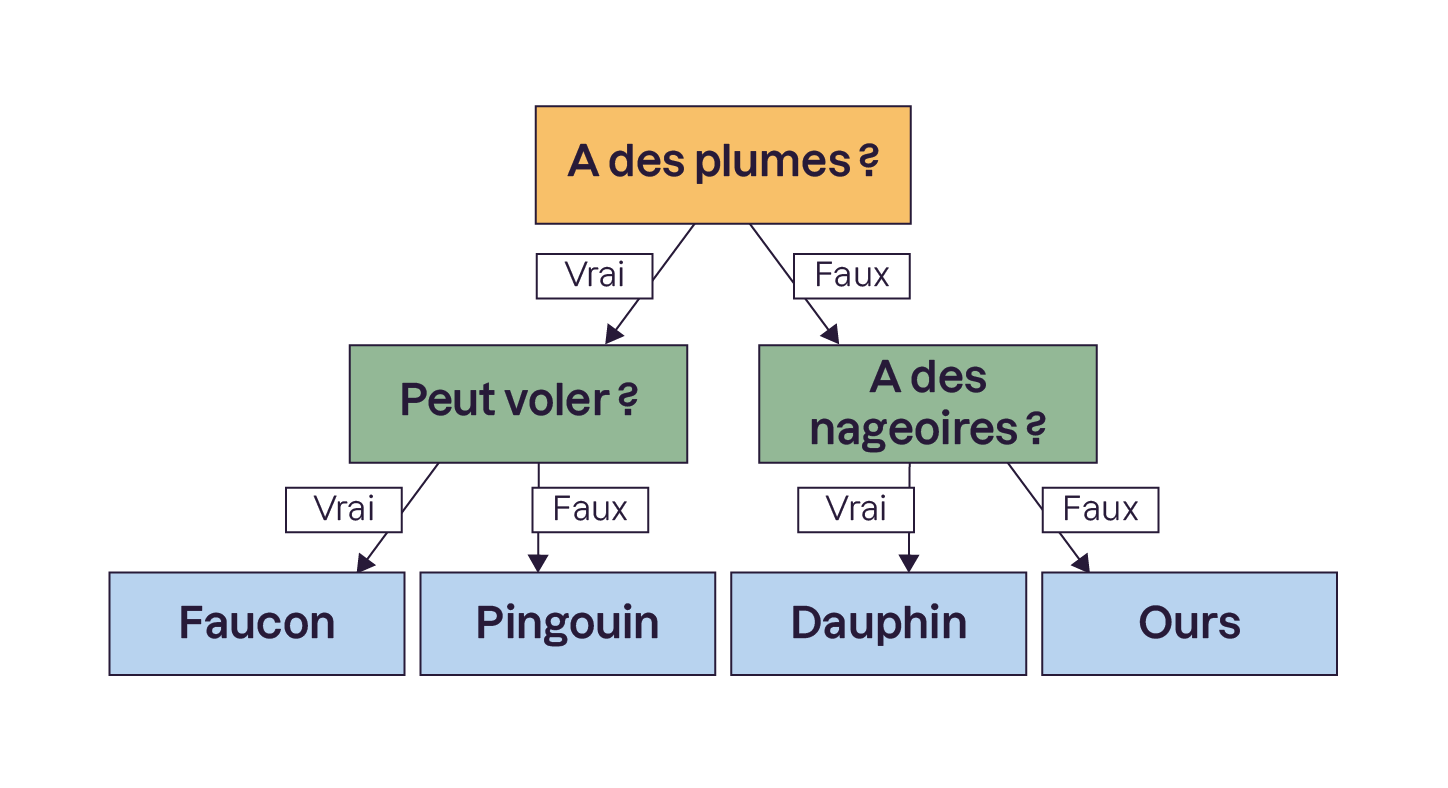
Dans le Machine Learning, les règles de bifurcation se feront à partir de critères statistiques sur les variables.
Par exemple :
si [hauteur_m > 10 & libelle_francais = 'Platane' ]
Alors stade de développement = Mature
Sinon [autre règle]L'algorithme d'entraînement détermine les critères des différentes règles (variables concernées, seuils, valeurs catégoriques) qui sont les plus efficaces pour faire aboutir la tâche de classification. L'algorithme répond à un critère prédéfini pour établir la règle de bifurcation.
Une caractéristique saute aux yeux, c'est le nombre de nœuds de l'arbre, autrement dit sa profondeur.
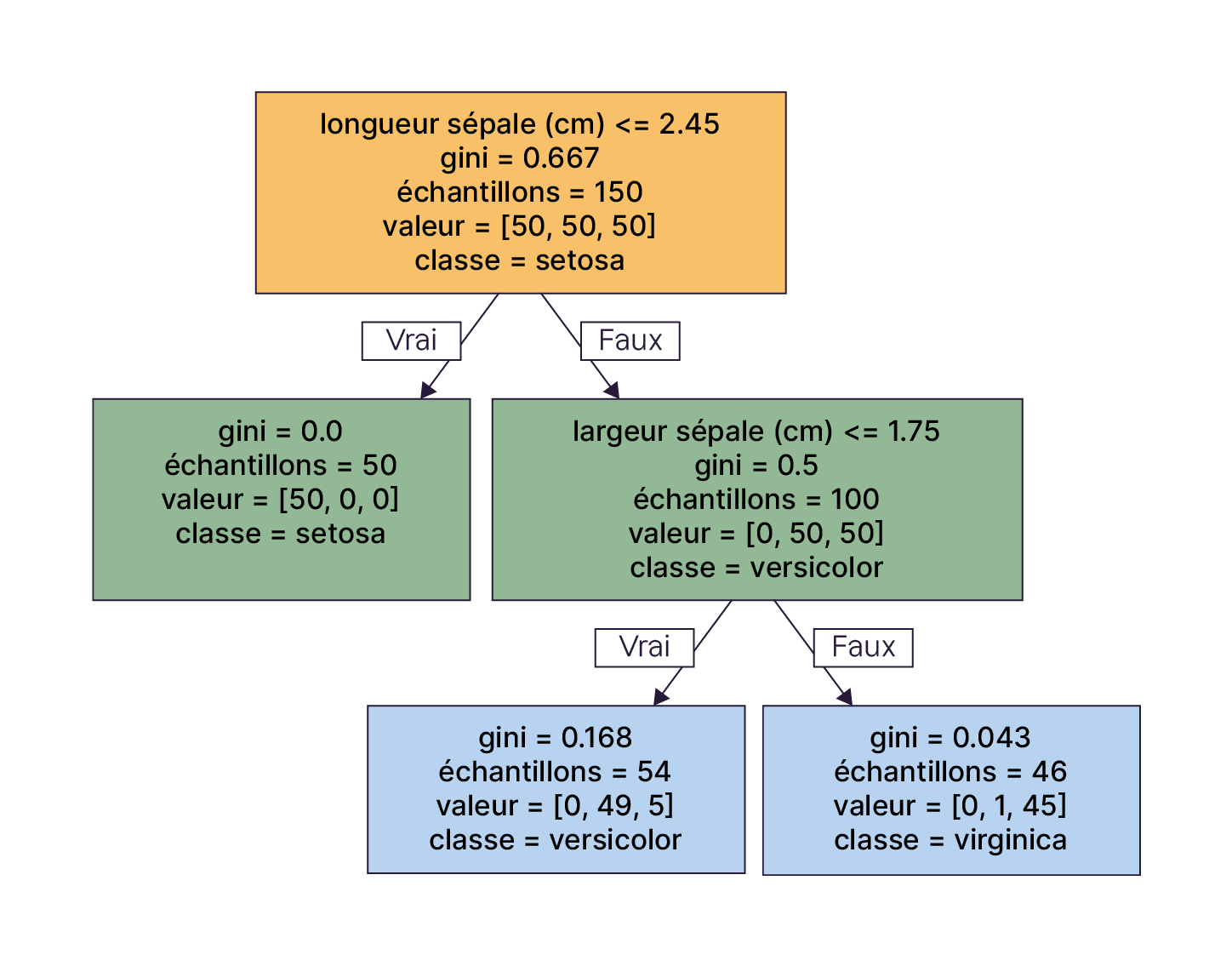
Et voici un arbre de décision profond :
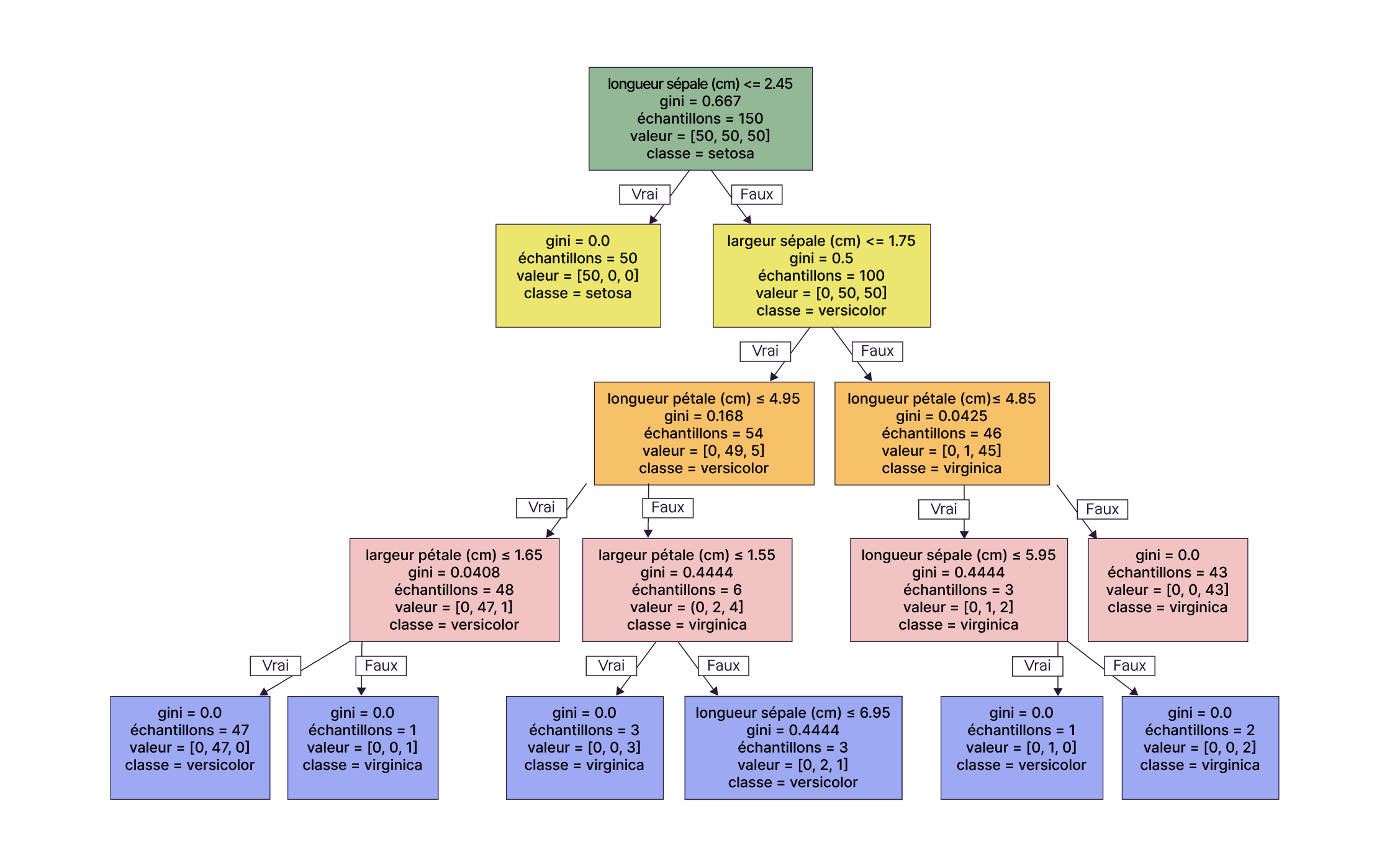
Minimisez le biais du modèle
Chargeons les données :
filename = 'https://raw.githubusercontent.com/OpenClassrooms-Student-Center/8063076-Initiez-vous-au-Machine-Learning/master/data/paris-arbres-numerical-2023-09-10.csv'
data = pd.read_csv(filename)
X = data[['domanialite', 'arrondissement', 'libelle_francais', 'genre', 'espece', 'circonference_cm', 'hauteur_m']]
y = data.stade_de_developpement.valuesScindons les données en train et test :
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split( X, y, train_size=0.8, random_state=808)Importons le classificateur DecisionTreeClassifier :
from sklearn.tree import DecisionTreeClassifierLimitons la profondeur de l'arbre à 3 et entraînons le modèle :
clf = DecisionTreeClassifier(
max_depth = 3,
random_state = 808
)
clf.fit(X_train, y_train)Pour le score, on utilise l'AUC :
from sklearn.metrics import roc_auc_score
train_auc = roc_auc_score(y_train, clf.predict_proba(X_train), multi_class='ovr')
test_auc = roc_auc_score(y_test, clf.predict_proba(X_test), multi_class='ovr')
print("train",train_auc)
print("test", test_auc)
train 0.89
test 0.89Voici la matrice de confusion :
from sklearn.metrics import confusion_matrix
y_train_hat = clf.predict(X_train)
y_test_hat = clf.predict(X_test)
print(confusion_matrix(y_test, y_test_hat))
[[ 5570 1402 300 2]
[ 1060 3847 2750 8]
[ 211 1481 13328 466]
[ 4 7 565 877]]ainsi que le rapport de classification qui donne plusieurs scores :
from sklearn.metrics import classification_report
print(classification_report(y_test, y_test_hat))
precision recall f1-score support
1 0.81 0.77 0.79 7274
2 0.57 0.50 0.53 7665
3 0.79 0.86 0.82 15486
4 0.65 0.60 0.63 1453
accuracy 0.74 31878
macro avg 0.70 0.68 0.69 31878
weighted avg 0.73 0.74 0.74 31878On voit que la precision (le ratio de bonne pioche parmi tous les positifs) est faible pour les catégories Jeune (arbre)Adulte et Mature (respectivement 0,57 et 0,67) et nous observons un recall de 0,5 pour la catégorie Jeune (arbre) aussi très faible.
Donc ce modèle a besoin de tendresse.
C'est un bon exemple d'un modèle biaisé.
Notez cependant que le score(test) et le score(train) sont presque égaux :
clf.score(X_train, y_train)
0.731
clf.score(X_test, y_test)
0.74Quels remèdes pour minimiser le biais du modèle ?
Plusieurs stratégies sont envisageables :
Ajouter des données. Sur un dataset trop petit, le modèle n'aura pas assez d'exemples pour assimiler les dynamiques internes. Ajouter des données pourra l'aider. On peut soit collecter plus de données et les ajouter au dataset, soit utiliser des techniques d'augmentation de données qui créent des échantillons artificiels et gonflent donc artificiellement le dataset d'entraînement.
Le fameux feature engineering où l'on va s'efforcer de transformer ou d'ajouter des variables pour encoder plus d'informations exploitables par le modèle.
Modifier les paramètres du modèle pour améliorer sa performance. C'est ce que nous allons faire maintenant.
Identifiez et compensez l'overfit
Reprenons maintenant notre arbre de décision, mais cette fois sans limiter sa profondeur.
Pour cela on fixe la valeur max_depth = None .
clf = DecisionTreeClassifier(
max_depth = None,
random_state = 808
)
clf.fit(X_train, y_train)
clf.score(X_test, y_test)
0.81Le modèle est en effet meilleur : on passe de 0,74 à 0,81. Mais on remarque que sur le sous-ensemble d'entraînement on a carrément 0,94 !
clf.score(X_train, y_train)
0.935048231511254Nous sommes bien dans un cas d'overfitting où :
le modèle colle aux données d'entraînement (le score(train) est excellent) ;
et ne sait pas reproduire la même performance sur les données de test (le score(test) est faible).
Donc à un moment, entre maxdepth = 3 et max_depth = infini , les score(train) et score(test) ont divergé. Il nous faut trouver un juste milieu pour ce paramètre.
Faisons croître max_depth en enregistrant les scores sur train et test.
L'AUC est plus parlante que l'accuracy pour cette démonstration :
scores = []
for depth in np.arange(2, 30, 2):
clf = DecisionTreeClassifier(
max_depth = depth,
random_state = 808
)
clf.fit(X_train, y_train)
train_auc = roc_auc_score(y_train, clf.predict_proba(X_train), multi_class='ovr')
test_auc = roc_auc_score(y_test, clf.predict_proba(X_test), multi_class='ovr')
scores.append({
'max_depth': depth,
'train': train_auc,
'test': test_auc,
})
scores = pd.DataFrame(scores)On obtient la figure ci-dessous, avec max_depth en abscisse et AUC en ordonnée :
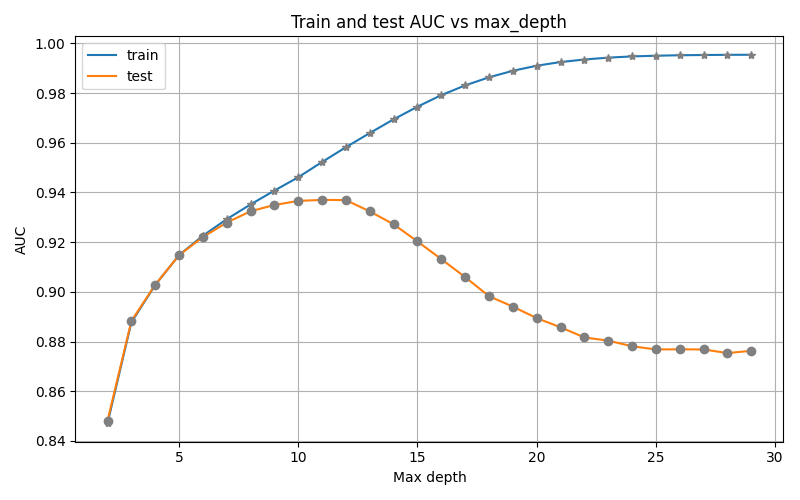
Quand on augmente max_depth , l'AUC(train) croît jusqu'à presque atteindre un score parfait de 1. Ce score atteint ensuite un plateau. Augmenter la profondeur de l'arbre ne sert plus à rien à partir de max_depth = 20 .
L'AUC(test) par contre, croît jusqu'à atteindre un maximum autour de 0.94 ( max_depth = 9 ). Elle décroît ensuite jusqu'à 0.87 pour rejoindre elle aussi un plateau vers max_depth = 20 .
On observe bien les 3 cas de comportement du modèle :
à gauche, le modèle sous-performe (biais) ;
à droite, il overfit ;
au milieu, on obtient la meilleure performance sur le test set.
On a ainsi trouvé la valeur optimale du paramètre max_depth pour ce modèle et ce dataset donnés, soit 9 ou 10 .
Comment remédier à l'overfit en général ?
Un modèle qui overfit est un modèle trop complexe. Dans notre contexte, la complexité se traduit par la profondeur de l'arbre. Dans le cas d'une régression, la complexité serait traduite par trop de variables prédictives et pour le k-means(), trop de clusters.
La première stratégie de remédiation est d'augmenter la taille du dataset d'entraînement. En effet, plus il y aura d'échantillons, plus la complexité du modèle sera diluée dans la masse d'informations. Mais cela n'est pas toujours possible. Ce qui nous amène au concept de régularisation que l’on verra dans le chapitre suivant.
En résumé
En comparant les scores de performance sur les sous-ensembles d'entraînement et de test, on peut distinguer deux cas de sous-performance du modèle :
le sous-apprentissage, ou biais, aboutit à un score faible sur les 2 sous-ensembles. L'ajout de nouvelles données ou la sélection de paramètres plus efficaces pour le modèle sont des stratégies de remédiation classiques ;
le sur-apprentissage, ou overfit, se traduit par un écart significatif entre les scores sur les sous-ensembles d'entraînement (élevé) et de test (bien plus faible).
Dans le chapitre suivant, nous allons voir deux techniques pour accroître la capacité des modèles à faire des prédictions sur des données qu'ils n'ont pas déjà rencontrées : la régularisation et la validation croisée.
