De la statistique à la science des données et à l'IA
Avant d'entrer dans le vif du sujet et de savoir ce que peuvent science des données et intelligence artificielle (IA), il est bon, en introduction, de rappeler d'où ces pratiques proviennent. Voici quelques repères historiques marquants de cette évolution.
1930-70 h-Octets Statistique inférentielle
Les années 30 voient le développement de la statistique inférentielle avec notamment les travaux de Sir Ronald Fisher. Une hypothèse est posée, une expérience planifiée, une statistique de test calculée (Student, ANOVA) ; la statistique est comparée à une valeur seuil. L'hypothèse est acceptée ou rejetée avec un risque contrôlé. Il s'agit, par exemple, de montrer qu'une molécule est significativement active, qu'une semence est significativement plus productive... De plus, la décision prise sur l'échantillon peut être inférée à la population entière. Ce cours ne s'intéresse pas à cette statistique inférentielle ni aux pratiques de test associées.
1940-50 Intelligence artificielle
Parallèlement, les premiers ordinateurs sont produits pour répondre aux besoins de l'effort de guerre. Ces découvertes motivent par ailleurs les premières réflexions sur la notion d'intelligence artificielle, avec pour objectif de simuler le fonctionnement du cerveau. Mc Culloch (neurophysiologiste) et Pitts (logicien) introduisent en 1943 le neurone formel, tandis que Turing (1950) développe la première théorisation de l'IA et que Rosenblatt (1957) propose de modéliser le fonctionnement de la rétine par un réseau de neurones formel appelé perceptron.
1970s kO Analyse des données et exploratory data analysis
Les années 70 connaissent une remise en cause des modèles statistiques très contraignants car basés sur des hypothèses de nature probabiliste difficiles à vérifier, voire contredites. La plus grande diffusion des ordinateurs permet une approche exploratoire multidimensionnelle de l'analyse des données, notamment avec l'analyse en composantes principales (ACP), basée sur des considérations géométriques au lieu de probabilistes. De son côté, l'IA développe des procédures de raisonnement automatique associant, dans un système expert, bases de connaissances constituées de règles logiques et moteur d'inférence.
1980s MO IA, Réseaux de neurones, Statistique fonctionnelle
Les années 80 connaissent des développements plus méthodologiques avec la possibilité d'estimer des modèles statistiques non plus paramétriques mais fonctionnels, c'est-à-dire de grande dimension, et d'entraîner des réseaux de neurones relativement complexes. C'est l'apparition de l'algorithme de rétropropagation du gradient. L'intelligence artificielle de cette période abandonne alors les systèmes experts aux temps d'exécution rédhibitoires (NP complets) au profit des réseaux de neurones. L'approche symbolique est supplantée par l'approche connexionniste.
1990s GO Data mining et données préacquises
Dans les années 90, la fouille de données, ou data mining, fait son apparition avec principalement des applications en marketing quantitatif dans le tertiaire : banque, assurance, vente par correspondance. Ces grandes entreprises disposent déjà de bases de données clients conséquentes à des fins comptables : des milliers de clients décrits par des dizaines de variables. L'objectif est de valoriser ces données en les utilisant pour améliorer la gestion de la relation client ou GRC : scores d'appétence pour des campagnes publicitaires, risque de crédit.
Pour ce faire, des suites logicielles commercialisées associent des requêtes d'extraction dans des bases de données, des outils exploratoires et de classification non supervisée, des modèles statistiques comme la régression logistique ou des arbres de décision, les premiers algorithmes d'apprentissage supervisé comme les réseaux de neurones...
L'ensemble de ces capacités de gestion, traitement et analyse des données intégrées dans une même suite logicielle devient le data mining.
En fait, deux choses sont nouvelles :
- l'intégration dans une même suite logicielle ;
- et surtout le fait que les données ne soient plus issues d'une planification expérimentale comme en statistique inférentielle. Les données sont préalables à l'analyse, acquises pour d'autres finalités, par exemple comptables, et il faut faire avec...
C'est, pour le statisticien, devenu un prospecteur de données, un premier changement de paradigme : ne plus pouvoir planifier l'expérience.
2000s TO Apprentissage statistique, Bio-informatique : p >> n
Le début du siècle a connu de profondes ruptures dans les biotechnologies à la suite du premier séquençage du génome. Pour chaque échantillon biologique, ce sont maintenant des milliers voire des millions d'informations qui sont observables ; des occurrences de millions de mutations possibles sur le génome, des expressions de dizaines de milliers de gènes, des expressions de protéines, de métabolites... En conséquence, les ensembles de données à étudier présentent beaucoup plus de colonnes, variables ou features que de lignes, échantillons ou instances ; , le nombre de variables, est beaucoup plus grand que n, la taille de l'échantillon. Ceci crée une situation d'indétermination qui a poussé à des développements méthodologiques et algorithmiques originaux : modèles et algorithmes parcimonieux ou sparse.
C'est un deuxième changement de paradigme pour le statisticien devenu bio-informaticien.
À cette occasion apparaissent ou réapparaissent des algorithmes dits d'apprentissage statistique (statistical learning) : boosting, support vector machine, random forest, réseaux de neurones..., sous-ensemble de l'apprentissage automatique, lui-même sous-ensemble de l'intelligence artificielle.
2010s PO Grosses Data, Science des données et IA p et n très grands
Plus récemment, avec l'avènement des réseaux sociaux, le succès planétaire de Google et des autres GAFAM, le volume des données, c'est-à-dire le nombre de clients, d'échantillons, et la taille des bases de données explosent ; la fouille devient science des données. Leur volume associé à la puissance de calcul autorisent l'entraînement d'algorithmes d'apprentissage statistique excessivement complexes, dont le deep learning avec des millions de paramètres ou poids à estimer. La convergence entre données massives, puissance de calcul et algorithmes d'apprentissage conduit à des succès retentissants en reconnaissance d'images, traduction automatique ou encore jeu de go et véhicules autonomes... tout ceci concourt au succès de l'IA propulsée par un battage médiatique considérable.
Le troisième changement de paradigme concerne à la fois statisticiens, informaticiens et mathématiciens, devenus depuis 2008 data scientists, car le traitement de ces données massives nécessite certes de la puissance de calcul sur des systèmes de fichiers distribués comme Hadoop, mais aussi de nouvelles approches pour la résolution des problèmes d'optimisation afférents.
Méfiez-vous de ce battage médiatique et surtout des faux espoirs qu'il fait miroiter. Mêmes assemblées, toutes ces compétences ne peuvent rien avec des données pourries.;)
Data Scientist (n) : "Person who is better at statistics than any software engineer and better at software than any statistician " (J. Wills, Cloudera).
Traduction : un Data scientist est une personne qui est meilleure en statistique que n'importe quel ingénieur en logiciel et meilleure en logiciel que n'importe quel statisticien
Algorithme et décision automatique
Voici quelques exemples illustratifs d'applications au quotidien de la science des données ou, plus précisément, d'algorithmes d'IA ou apprentissage automatique :
le choix d'un traitement médical, d'une action commerciale, d'une action de maintenance préventive, d'accorder ou non un crédit, de surveiller un individu... toutes les décisions qui en découlent sont la conséquence d'une prévision ;
la prévision du risque ou de la probabilité de diagnostic d'une maladie, le risque de rupture d'un contrat par un client, qui est le score d'attrition ou churn, le risque de défaillance d'un système mécanique, de défaut de paiement d'un client ou encore de radicalisation d'un individu... Les exemples sont très nombreux et envahissent notre quotidien à la suite de sa datafication.
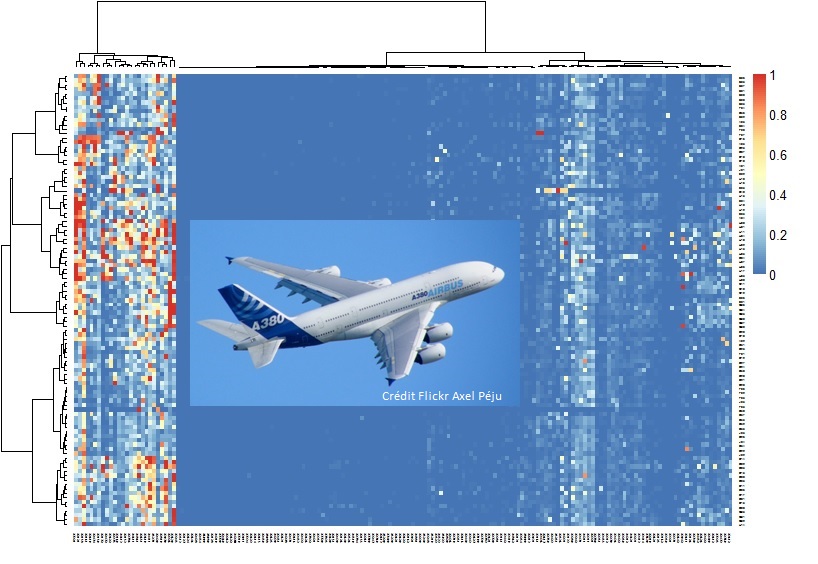
Visualisation et classification non supervisée avant analyse prédictive d'un recueil de messages d'incidents sur une flotte d'appareils
Le graphique ci-dessus est une visualisation avant analyse prédictive d'un recueil durant 6 mois de 700 000 messages d'incidents sur une flotte de 139 appareils. En ligne, les appareils ordonnés par une classification ascendante hiérarchique, en colonne les types d'incidents également ordonnés. La fausse couleur illustre un taux d'incidents.
Ces prévisions de risques ou scores, par exemple de crédit, sont produits par des algorithmes d'apprentissage supervisé, après entraînement sur une base de données où sont connus le comportement bancaire des clients et l'observation de bon remboursement ou non d'un emprunt.
