Comprenez la classification supervisée
Le chapitre précédent développe la prévision d'une variable cible quantitative appliquée, par exemple, à la prévision de la concentration en ozone. En revanche, le problème de reconnaissance de l'activité humaine vise à la prévision d'une classe d'activité ou encore de la classe d'une variable , cette fois qualitative. Il s'agit d'un problème de classification supervisée ou reconnaissance de forme.
Historiquement, les deux méthodes partageant l'objectif de discrimination, ou de prévision, d'une variable quantitative Y, et apparues en premier sont :
la régression logistique ou binomiale.
L'analyse discriminante développée par Fisher propose la prévision d'une classe parmi les modalités de , alors qu'en principe la régression logistique est adaptée à une variable à deux classes ou binaire : succès ou échec, présence d'une maladie, défaut de paiement, occurrence d'un événement... Néanmoins, cette même méthode, à condition que la taille de l'échantillon le permette, est largement utilisée pour de la discrimination en classes en construisant modèles d'une classe contre les autres.
Pour la prévision de la classe d'un nouvel individu ou d'une nouvelle instance, les modèles fournissent probabilités d'occurrence de chaque classe, et c'est la classe de probabilité maximale qui l'emporte. Cette stratégie est prise par défaut dans la librairie lors de l'utilisation de la régression logistique avec .
Après ces méthodes historiques, bien d'autres modèles ou algorithmes ont été proposés avec le même objectif de prévision d'une classe ou modalité d'une variable qualitative binaire ou à classes : plus proches voisins, arbre binaire de décision, réseau de neurones (perceptron), machine à vecteur support (SVM) ainsi que les algorithmes d'agrégation d'arbres : boosting, random forest... Se reporter aux tutoriels du dépôt pour les expérimenter.
Classification binaire par régression logistique
Nous avons vu précédemment comment ajuster une variable quantitative, à valeurs dans , par une combinaison linéaire des variables explicatives . Ce que la régression logistique vise à modéliser est la probabilité d'occurrence (succès, maladie...) d'une classe de qui est à valeur dans l'intervalle .
Plus précisément, le choix d'une fonction lien permet de faire correspondre les deux domaines de variation et afin de relier une probabilité avec un prédicteur linéaire classique . Si désigne la probabilité de la classe 1 de ou , la fonction lien dite canonique couramment utilisée est la fonction logistique et le modèle s'écrit :
L'estimation des paramètres de ce modèle est obtenue par l'exécution d'un algorithme de maximisation (e.g. Newton Raphson) de la log-vraisemblance du modèle.
La prévision d'une probabilité de est fournie par :
La prévision de la classe de est obtenue en comparant cette probabilité avec une valeur seuil ou cut-off, par défaut ; si et sinon.
Moyennant des hypothèses sur la loi de (binomiale), la planification de l'expérience et la répartition de l'échantillon, des procédures de test et d'estimation par intervalle de confiance des prévisions sont accessibles. Consulter la bibliographie à ce sujet. Nous nous limitons ici au seul objectif de prévision.
Courbe ROC
Matrice de confusion
Une erreur quadratique moyenne (RMSE) est généralement utilisée pour évaluer une erreur de prévision ou risque en régression. Ce critère n'est pas adapté au cas de la classification supervisée. Il est souvent remplacé par un simple taux d'erreur calculé à partir de la matrice de confusion. Cette matrice est simplement une table de contingence ou tableau obtenu par le croisement des deux variables : classe observée vs classe prédite.
Dans le cas fréquent de la discrimination de deux classes, la plupart des méthodes (e.g. régression logistique) estiment, pour chaque individu , un score ou une probabilité que cet individu prenne la modalité . Cette probabilité comprise entre 0 et 1 est comparée avec une valeur seuil fixée a priori, par défaut :
Pour un échantillon de taille dont l'observation de est connue ainsi que les scores fournis par un modèle, la matrice de confusion associée à cette valeur de seuil est :
Prévision | Observation | Observation | Total |
|
|
| |
Total |
Les quantités suivantes sont considérées :
vrais positifs : les observations bien classées ( et ) ;
vrais négatifs : les observations bien classées ( et ) ;
faux négatifs : les observations mal classées ( et ) ;
faux positifs : les observations mal classées ( et ) ;
le taux d'erreur : ;
le taux de vrais positifs ou sensibilité ou taux de positifs pour les individus qui le sont effectivement ;
le taux de vrais négatifs ou spécificité ou taux de négatifs pour les individus qui le sont effectivement ;
le taux de faux positifs .
Courbe ROC et AUC
Les notions de spécificité et de sensibilité proviennent de la théorie du signal ; leurs valeurs dépendent directement de celle du seuil . En augmentant , la sensibilité diminue tandis que la spécificité augmente, car la règle de décision devient plus exigeante. Un bon modèle associe grande sensibilité et grande spécificité pour la détection d'un signal. Ce lien est représenté graphiquement par la courbe ROC (Receiver Operating Caracteristic) de la sensibilité (probabilité de détecter un vrai signal) en fonction de un moins la spécificité (probabilité de détecter un signal à tort) pour chaque valeur du seuil.
On montre qu'une courbe ROC est croissante monotone. Plus une courbe de la figure ci-dessous se rapproche du carré, meilleure est la discrimination, correspondant à la fois à une forte sensibilité et une grande spécificité. L'aire sous la courbe : AUC (area under curve) mesure la qualité de discrimination du modèle, tandis qu'une analyse de la courbe aide au choix du seuil.
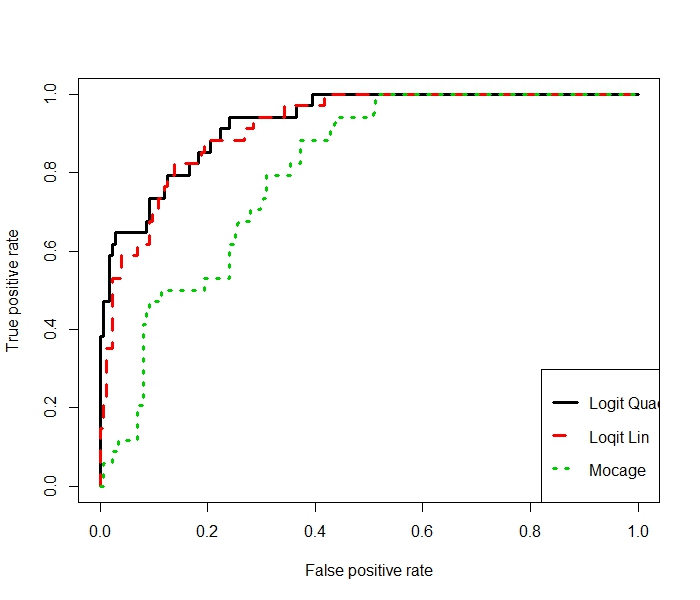
Ce graphique compare trois courbes ROC. Celle issue du modèle MOCAGE en vert avec celles issues de deux modèles de régression logistique, l'un linéaire, l'autre quadratique car faisant intervenir des interactions. Pour comparer des modèles ou méthodes de complexités différentes, ces courbes doivent être estimées sur un échantillon test. Elles sont bien évidemment optimistes sur l'échantillon d'apprentissage. De plus, l'AUC ne définit pas un ordre total entre modèles, car les courbes ROC peuvent se croiser.
Ces résultats montrent encore plus clairement l'intérêt de l'adaptation statistique de la prévision MOCAGE, mais aussi la difficulté de la décision qui découle de la courbe ROC. Le choix du seuil, et donc de la méthode à utiliser si les courbes se croisent, dépend d'un choix dans ce cas politique : quel est le taux de faux positifs acceptable d'un point de vue économique, ou le taux de vrais positifs à atteindre pour des raisons de santé publique ? Le problème majeur est de pouvoir quantifier les coûts afférents, par la définition d'une matrice dissymétrique de ces coûts de mauvais classement en vue d'optimiser le choix de .
Autre critère pour la discrimination à deux classes
Une autre difficulté concerne les cas où les classes sont déséquilibrées ; ainsi, les jours de dépassement du seuil critique de concentration en ozone sont relativement rares.
D'autres critères ont été proposés pour intégrer cette difficulté dont le Score de Pierce basé sur le taux de bonnes prévisions : et le taux de fausses alertes : . Le score de Pierce est alors défini par PSS et est compris entre et . Il évalue la qualité de la prévision. Si ce score est supérieur à 0, le taux de bonnes prévisions est supérieur à celui des fausses alertes et plus il est proche de 1, meilleur est le modèle.
Le score de Pierce a été conçu pour la prévision d'événements climatiques rares afin de pénaliser les modèles ne prévoyant jamais ces événements () ou encore générant trop de fausses alertes ( ). Le modèle idéal prévoyant tous les événements critiques ( ) sans fausse alerte (). Une autre stratégie consiste à introduire des coûts de mauvais classement pour pondérer un score.
