Modélisation et prévision
Dans les années 30 et notamment à la suite des travaux de Ronald Fisher, la statistique a été développée avec une finalité principalement explicative, pour un objectif d'aide à la décision. Par exemple : tester l'efficacité d'une molécule et donc d'un médicament, comparer le rendement de semences ou optimiser le choix d'un engrais, montrer l'influence d'un facteur (consommation de tabac, de sucre) sur des objectifs de santé publique.
La prise de décision est alors soumise à un test statistique permettant de contrôler le risque d'erreur encouru. Mais il se trouve que les mêmes modèles statistiques peuvent aussi être utilisés avec une finalité seulement prédictive : prévoir la concentration en ozone du lendemain, le risque de défaut de paiement d'une entreprise...
Deux modèles statistiques sont considérés :
La régression linéaire multiple qui vise à modéliser, prévoir une variable quantitative (cible ou dépendante) à l'aide d'un ensemble de variables (features ou caractéristiques) quantitatives et/ou qualitatives .
La régression logistique qui est une adaptation de la précédente afin de prévoir l'occurrence (défaut, succès, maladie...) d'une variable qualitative binaire ou plutôt, en premier lieu, la probabilité de cette occurrence.
Commençons par introduire le modèle de régression linéaire. Ayant observé les valeurs des variables sur un ensemble d'apprentissage d'objets individus ou instances, la modélisation par régression linéaire consiste à estimer au mieux les paramètres d'un modèle :
, ou matriciellement ,
où les sont des termes d'erreur.
L'estimation des paramètres par minimisation des moindres revient à minimiser la moyenne des carrés (MSE ou mean square error). La prévision de pour un nouvel individu est alors obtenue en appliquant le modèle :
.
Moyennant un ensemble d'hypothèses sur la loi des résidus : normalité, homoscédasticité, l'estimation du modèle peut être définie par un principe de maximisation de la log-vraisemblance. C'est en fait la même solution que celle issue des moindres carrés, mais cette approche confère de meilleures propriétés au modèle.
Avant d'aborder le problème plus complexe de reconnaissance d'une activité humaine à partir des signaux enregistrés par un smartphone, nous nous intéressons aux données de prévision de la concentration en ozone vues dans la partie 2 précédente, et détaillées dans le tutoriel . L'objectif est d'illustrer les modèles statistiques de régression. Cet exemple, à la fois de régression et de discrimination binaire, présente des vertus pédagogiques certaines qui permettent de l'utiliser comme fil rouge de comparaison entre toutes méthodes.
Le graphique ci-dessous utilise ces données pour comparer deux ajustements de modèle :
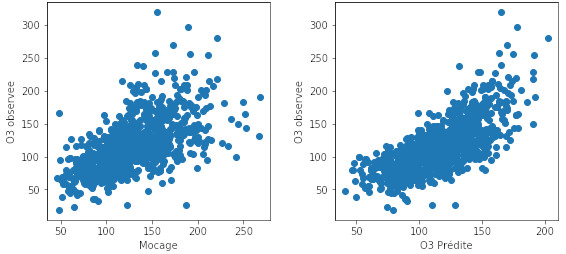
celui obtenu par le modèle déterministe MOCAGE à gauche et celui à droite obtenu par adaptation statistique en introduisant les autres variables explicatives. Le modèle (choix de variables) a été optimisé comme cela est expliqué par la suite. Les graphes représentent les valeurs observées en fonction des valeurs prédites .
Plus celles-ci sont proches de la diagonale et meilleur est l'ajustement du modèle (plus petits résidus). Le carré du coefficient de corrélation entre et est appelé coefficient de détermination. Il vaut pour MOCAGE et pour le modèle statistique intégrant un choix optimal de variables.
Erreur de prévision
En effet, l'erreur d'ajustement, encore appelée erreur apparente, est estimée sur des observations qui participent à l'ajustement du modèle. Par principe, elle est une version optimiste de l'erreur de prévision, qui concerne des observations nouvelles qui n'ont pas participé à l'ajustement du modèle. Les écarts ou résidus de la prévision sont en effet, sauf cas particuliers, de nature à être plus grands que les résidus minimisés lors de l'estimation.
Une façon élémentaire d'estimer une erreur de prévision consiste à opérer en deux phases après avoir séparé aléatoirement l'échantillon en deux parties :
- celle d'apprentissage pour estimer un modèle ou entraîner un algorithme ;
- et celle de test avec .
Une estimation de l'erreur de prévision ou risque : RMSE ou root mean square error, est alors fournie par :
RMSE\(= \frac{1}{n_t}\sum_{\boldsymbol{x}_i \in D_{n_t}^{\text{Test}}}(\hat{f}(\boldsymbol{x_i})-y_i)^2.\)
L'objectif majeur d'une étape d'apprentissage statistique est de déterminer le modèle ou l'algorithme, parmi tous ceux disponibles ou parmi une classe réduite de ceux interprétables, qui conduit à la plus petite erreur de prévision ou plus petit risque.
Sélection de modèle
La recherche du modèle statistique ou de l'algorithme d'apprentissage optimal nécessite de prendre conscience d'une réalité importante :
Rechercher le meilleur modèle parmi une famille donnée consiste, d'un point de vue statistique, à réaliser un meilleur compromis entre biais et variance. Ceci peut être illustré simplement dans le cas de la régression polynomiale.
Le graphique ci-dessous compare les ajustements d'un nuage de points par régression polynomiale. Les points sont successivement ajustés par des polynômes de degré 1, 3, 5 et 10.
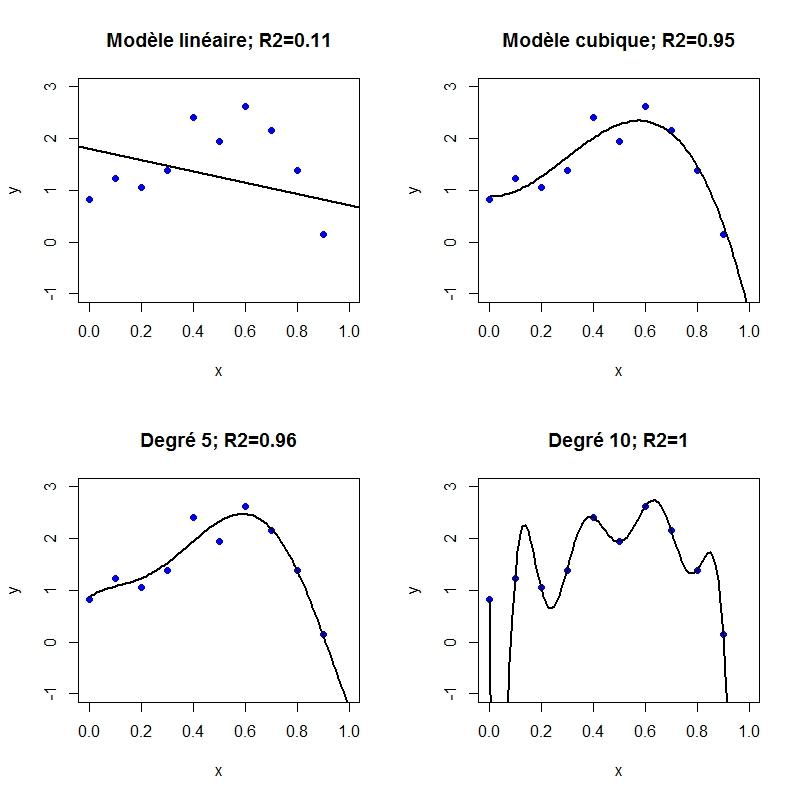
Les coefficients de détermination qui mesurent la qualité de l'ajustement sont successivement : (degré 1) , (degré 3), (degré 5), (degré 10 ou interpolation exacte des points).
Clairement, la qualité de l'ajustement du modèle croît avec le et donc avec la complexité, le nombre de paramètres ou le degré du polynôme. Intuitivement, le nuage de points a la forme d'un modèle relativement simple mais dont les observations sont entachées d'erreurs. Vouloir ajuster au mieux ces observations conduit à interpoler la composante d'erreur ou de bruit au détriment de la régularité du modèle.
La conséquence directe en est la construction de prévisions qui prendront des valeurs absolues beaucoup trop importantes par rapport à celles généralement observées. La variance des erreurs de prévision prend alors une très grande valeur qui conduit à l'explosion du RMSE. En revanche, accepter un modèle, éventuellement plus simple ou biaisé que le supposé vrai modèle, évite d'ajuster le modèle aux erreurs de mesure et réduit la variance. C'est le principe de la recherche d'un meilleur compromis biais / variance ; compromis qui dépend de la variance du bruit par rapport à celle des observations (rapport signal / bruit).
La stratégie de choix de modèle consiste donc à la recherche d'un modèle parcimonieux (sparse) au sens où sa complexité optimise le compromis entre biais et variance. C'est facilement illustré dans le cas de la régression mais ce principe se retrouve dans presque tous les algorithmes d'apprentissage dont il faut contrôler la complexité et donc la flexibilité de l'ajustement aux données. En fonction du type d'algorithme, ce peut être le nombre de variables, de feuilles, de voisins, de neurones ou un coefficient de pénalisation : Ridge, Lasso (least absolute shrinkage and selection operator)... qui règle la flexibilité ou complexité du modèle.
Sélection par pénalisation
Il existe de très nombreuses stratégies (descendante, ascendante, pas-à-pas, par pénalisation Ridge ou Lasso...) de sélection de modèle en régression, stratégies basées sur une grande variété de critères : test de Fisher, critère d'Akaïke, critère bayésien (BIC), de Mallows. La stratégie actuellement la plus utilisée est celle proposée par Tibshirani (1996) basée sur une pénalisation Lasso dite encore en norme de la somme des valeurs absolues des paramètres. Ce qui s'écrit encore :
qui est équivalent à minimiser les moindres carrés (MSE) sous une contrainte :
avec
La régression Ridge satisfait à la même formule :
avec
en remplaçant la norme par la norme , c'est-à-dire la somme des valeurs absolues par la somme des carrés des coefficients. La régression Ridge suit le même principe que la régularisation de Tikhonov pour résoudre un problème inverse indéterminé.
Le graphique ci-dessous propose une interprétation géométrique des pénalisations Ridge et Lasso, afin d'expliquer en quoi cette dernière opère automatiquement une sélection de variables par annulation des paramètres les moins significatifs.
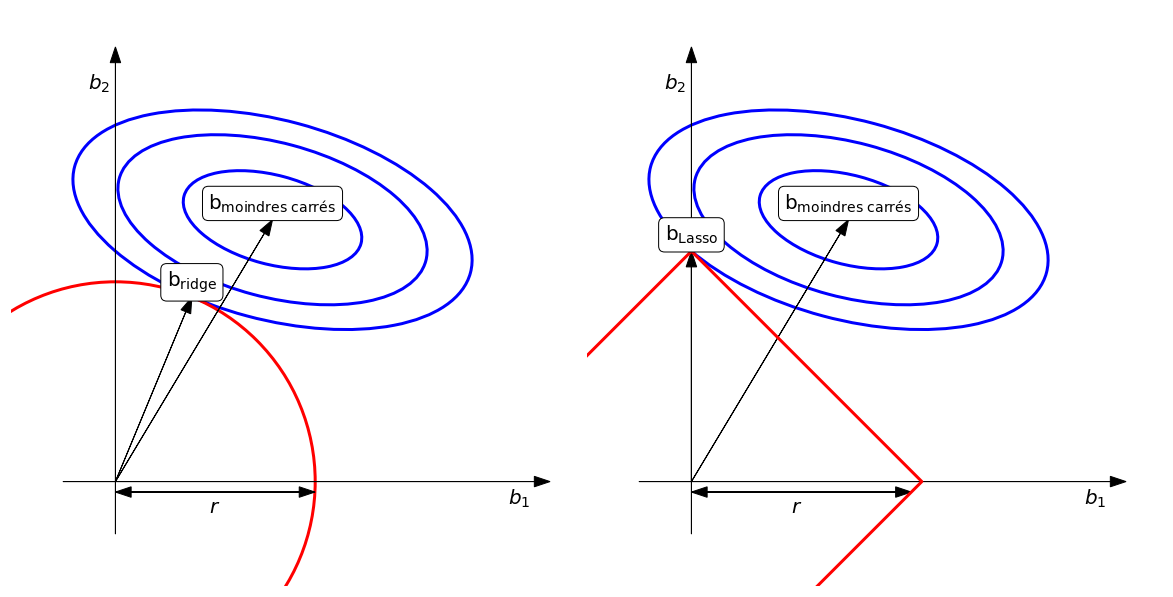
Dans les deux graphiques, les ellipses représentent les valeurs du critère des moindres carrés. Lorsque la pénalisation est nulle ( ), les paramètres prennent les valeurs des moindres carrés minimaux. En norme , la contrainte est visualisée par une hypersphère, un cercle en dimension 2, de rayon . La régression Ridge conduit alors à un rétrécissement (shrinkage) à la rencontre de l'ellipse des moindres carrés et de la sphère de la contrainte.
La pénalisation Lasso remplace l'hypersphère par un hypercube, un carré en dimension 2. Dans ce cas, l'ellipse à toutes les chances de rencontrer un coin en dimension 2 ou un hyperplan de dimension correspondant à l'annulation de certains paramètres, ici .
Cette stratégie de sélection de modèles peut paraître complexe mais elle est largement utilisée, notamment dans la librairie Scikit-learn de Python. Seule insuffisance de cette librairie, la difficulté, voire l'impossibilité, de pouvoir prendre en compte simplement des interactions entre les variables, alors que la syntaxe de R le permet aisément.
Le graphe ci-dessous représente le chemin de régularisation en pénalisation Lasso lors de la recherche d'un modèle optimal.

Il montre comment les paramètres décroissent et certains s'annulent lorsque la pénalisation croît de droite à gauche des abscisses associées aux valeurs d'un paramètre qui joue un rôle similaire à .
Un troisième type de sélection de modèle dit elastic net consiste à associer pénalisations Ridge et Lasso mais nécessite le réglage de deux paramètres.
Optimisation par validation croisée - couches
La question alors soulevée est de savoir comment optimiser la valeur de ce paramètre de pénalisation. La stratégie unanimement employée consiste à minimiser un risque estimé par une procédure de validation croisée. L'idée est d'itérer l'estimation sans biais de l'erreur sur plusieurs échantillons dits de validation n'ayant pas été utilisés pour l'estimation du modèle ou l'entraînement de l'algorithme, puis d'en calculer la moyenne.
Plus précisément, l'échantillon d'apprentissage est découpé aléatoirement en groupes (par défaut 5 ou 10) de tailles similaires qui jouent à tour de rôle celui de validation. Le groupe étant mis de côté, les autres groupes constituent l'échantillon d'apprentissage servant à estimer le modèle. L'erreur de prévision ou risque est estimée sur le groupe. Les erreurs ainsi obtenues sont moyennées pour calculer , l'estimation par validation croisée -couches du risque ou erreur de prévision.
Minimiser le risque estimé par validation croisée est une approche largement utilisée pour optimiser le choix d'un modèle au sein d'une famille paramétrée par où est le nombre de variables, de neurones, de feuilles, une pénalisation... Dans ce cas, est défini par
Le graphe ci-dessous illustre l'optimisation du paramètre de pénalisation Lasso par validation croisée 5-couches.
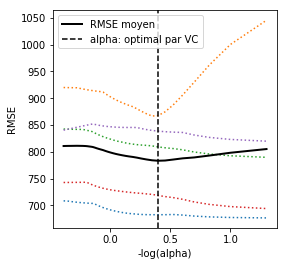
Chaque ligne colorée représente l'évolution de l'erreur de prévision calculée sur l'un des échantillons de validation en fonction d'une pénalisation , le paramètre de la librairie . La ligne pleine est la moyenne qui admet un minimum auquel est associée la valeur optimale du paramètre de pénalisation.
