Historique
L'intelligence artificielle, initialement branche de l'informatique fondamentale, s'est développée avec pour objectif la simulation des comportements du cerveau humain. Les premières tentatives de modélisation du cerveau sont anciennes et précèdent même l'ère informatique. C'est en 1943 que Mc Culloch (neurophysiologiste) et Pitts (logicien) ont proposé les premières notions de neurone formel.
Ce concept fut ensuite mis en réseau avec une couche d'entrée et une de sortie par Rosenblatt en 1957, pour simuler le fonctionnement rétinien et tâcher de reconnaître des formes. C'est l'origine du perceptron. Cette approche dite connexioniste a atteint ses limites technologiques, compte tenu de la puissance de calcul de l'époque, mais aussi théoriques au début des années 70.
L'approche connexionniste à connaissance répartie a alors été supplantée par une approche symbolique qui promouvait les systèmes experts à connaissance localisée, dont l'objectif était d'automatiser le principe de l'expertise humaine en associant trois concepts :
une base de connaissance dans laquelle sont regroupées les connaissances d'experts humains sous forme de propositions logiques élémentaires ou plus élaborées, en utilisant des quantificateurs (logique du premier ordre) ;
une base de faits contenant les observations du cas à traiter comme, par exemple, des résultats d'examens, d'analyses de sang, de salive pour des applications biomédicales de choix d'un antibiotique ;
un moteur d'inférence chargé d'appliquer les règles expertes sur la base de faits afin d'en déduire de nouveaux faits, jusqu'à la réalisation d'un objectif comme le choix du traitement d'une infection bactérienne.
Face aux difficultés rencontrées lors de la modélisation des connaissances d'un expert humain, au volume considérable des bases qui en découlaient et au caractère exponentiel de la complexité des algorithmes d'inférence mis en jeu, cette approche s'est éteinte avec les années 80. Il a été montré que les systèmes basés sur le calcul des prédicats du premier ordre conduisaient à des problèmes complets.
L'essor technologique et quelques avancées théoriques :
estimation du gradient par rétro-propagation du gradient proposé par Hopkins en 1982 ;
analogie de la phase d'apprentissage avec les modèles markoviens de systèmes de particules de la mécanique statistique (verres de spin) résolu par Hopfield en 1982 ;
ont permis au début des années 80 de relancer l'approche connexioniste. Celle-ci a connu jusqu'au début des années 90 un développement considérable, si l'on considère le nombre de publications et de congrès qui lui ont été consacrés, mais aussi les domaines d'application très divers où elle apparaît. La motivation initiale de simulation du cortex cérébral a été rapidement abandonnée, alors que les méthodes qui en découlaient ont trouvé leur propre intérêt de développement méthodologique et leurs champs d'application.
Remis en veilleuse depuis le milieu des années 90 au profit d'autres algorithmes d'apprentissage machine ou plutôt statistiques : boosting, support vector machine..., les réseaux de neurones connaissent un regain d'intérêt et même un énorme battage médiatique sous l'appellation d'apprentissage profond (deep learning).
Neurone formel
De façon très réductrice, un neurone biologique est une cellule qui se caractérise par :
des synapses, les points de connexion avec les autres neurones, fibres nerveuses ou musculaires ;
des dentrites ou entrées du neurones ;
les axones, ou sorties du neurone vers d'autres neurones ou fibres musculaires ;
le noyau qui active les sorties en fonction des stimulations en entrée.
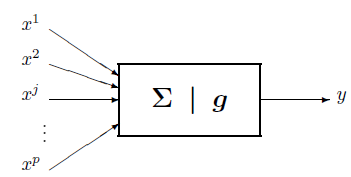
Par analogie, le neurone formel est un modèle qui se caractérise par un état interne , des signaux d'entrée et une fonction d'activation
La fonction d'activation opère une transformation d'une combinaison affine des signaux d'entrée, , terme constant, étant appelé le biais du neurone. Cette combinaison affine est déterminée par un vecteur de poids associé à chaque neurone et dont les valeurs sont estimées dans la phase d'apprentissage. Ces poids constituent la mémoire ou connaissance répartie du réseau.
Les différents types de neurones se distinguent par la nature de leur fonction d'activation. Les principaux types sont :
linéaire , la fonction identité ;
seuil ;
sigmoïde ;
ReLU (rectified linear unit) ;
radiale ;
Les modèles linéaires, sigmoïdaux, ReLU, sont bien adaptés aux algorithmes d'apprentissage impliquant (cf. ci-dessous) une rétropropagation du gradient, car leur fonction d'activation est différentiable ; ce sont les plus utilisés. Le modèle à seuil est sans doute plus conforme à la réalité biologique, mais pose des problèmes d'apprentissage.
Réseaux de neurones élémentaires (perceptron)
Un réseau neuronal est l'association, en un graphe plus ou moins complexe, d'objets élémentaires, les neurones formels. Les principaux réseaux se distinguent par l'organisation du graphe (en couches, complets ), c'est-à-dire son architecture, son niveau de complexité (le nombre de neurones, présence ou non de boucles de rétroaction dans le réseau), par le type des neurones (leurs fonctions de transition ou d'activation) et enfin par l'objectif visé : apprentissage supervisé ou non, optimisation, systèmes dynamiques...
Nous ne nous intéresserons dans ce cours qu'à une structure élémentaire de réseau, celle dite statique ne présentant pas de boucle de rétroaction et dans un but d'apprentissage supervisé. Les systèmes dynamiques avec boucle de rétroaction, ainsi que les cartes de Kohonen ou cartes autoorganisatrices pour la classification non supervisée, ne sont pas abordés.

Le perceptron multicouche (PMC) est un réseau composé de couches successives. Une couche est un ensemble de neurones n'ayant pas de connexion entre eux. Une couche d'entrée lit les signaux entrants, un neurone par entrée , une couche en sortie fournit la réponse du système. Selon les auteurs, la couche d'entrée qui n'introduit aucune modification n'est pas comptabilisée. Une ou plusieurs couches cachées participent au transfert.
Dans un perceptron, un neurone d'une couche cachée est connecté en entrée à chacun des neurones de la couche précédente et en sortie à chaque neurone de la couche suivante.
