Identify Redundancy in Your Modeling
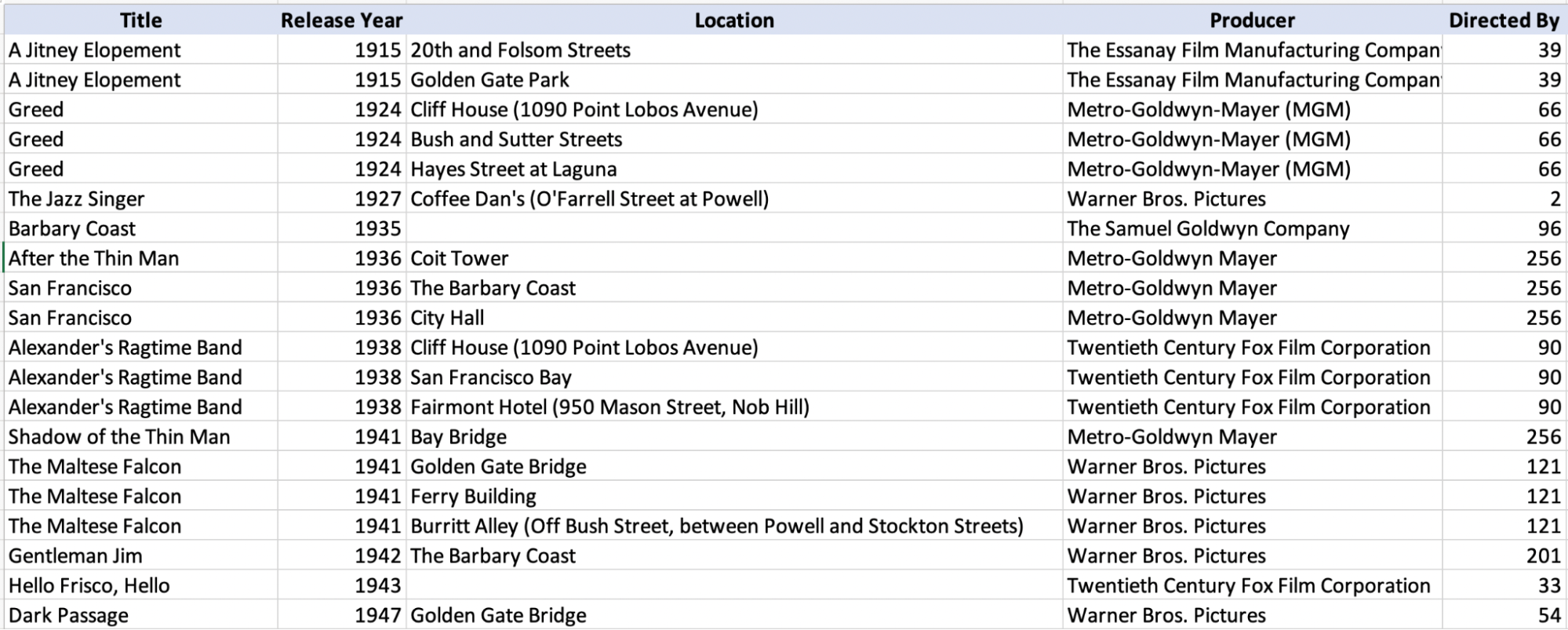
Let’s start with a little puzzle. There’s an inconsistency in one attribute value in the file, between row numbers 1266 and 1277:
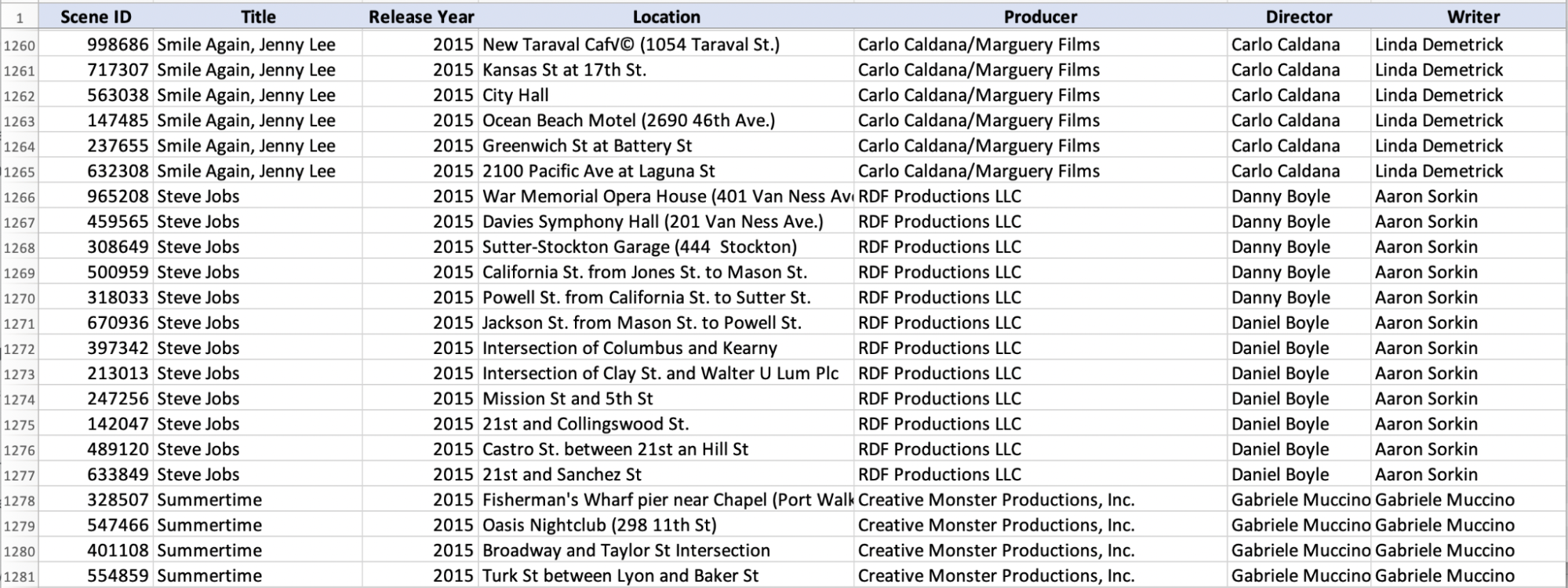
Have you found it?
The director of the Steve Jobs movie is spelled differently: “Danny Boyle” and “Daniel Boyle.”
But what's the problem?
The issue is that Danny Boyle’s information as the Steve Jobs movie director is in several places: row numbers 1266, 1267, etc.
This is called data redundancy.
Redundancy is problematic for a variety of reasons.
First, it can cause inconsistency within the data, as you’ve just seen in this example.
And then imagine if Danny Boyle changed his name. It would need to be changed in several places within the file, and it would be easy to miss a couple of rows, creating even more inconsistencies.
Now imagine that you decide to delete the Steve Jobs movie from the database. It would also delete information about Danny Boyle. But depending on how you're using it, you might want to have a director stored in the database even if they are not currently linked to a particular filming location. Similarly, you can’t currently add a director if they haven't filmed at least one scene because the file is based on filming locations and not directors.
So, what’s the solution?
You find out! Here’s a clue: we mentioned wanting a director in our database even if they haven’t shot a scene in a public place, meaning greater independence between filming locations and directors.
Have you worked it out?
You need a new table containing directors.
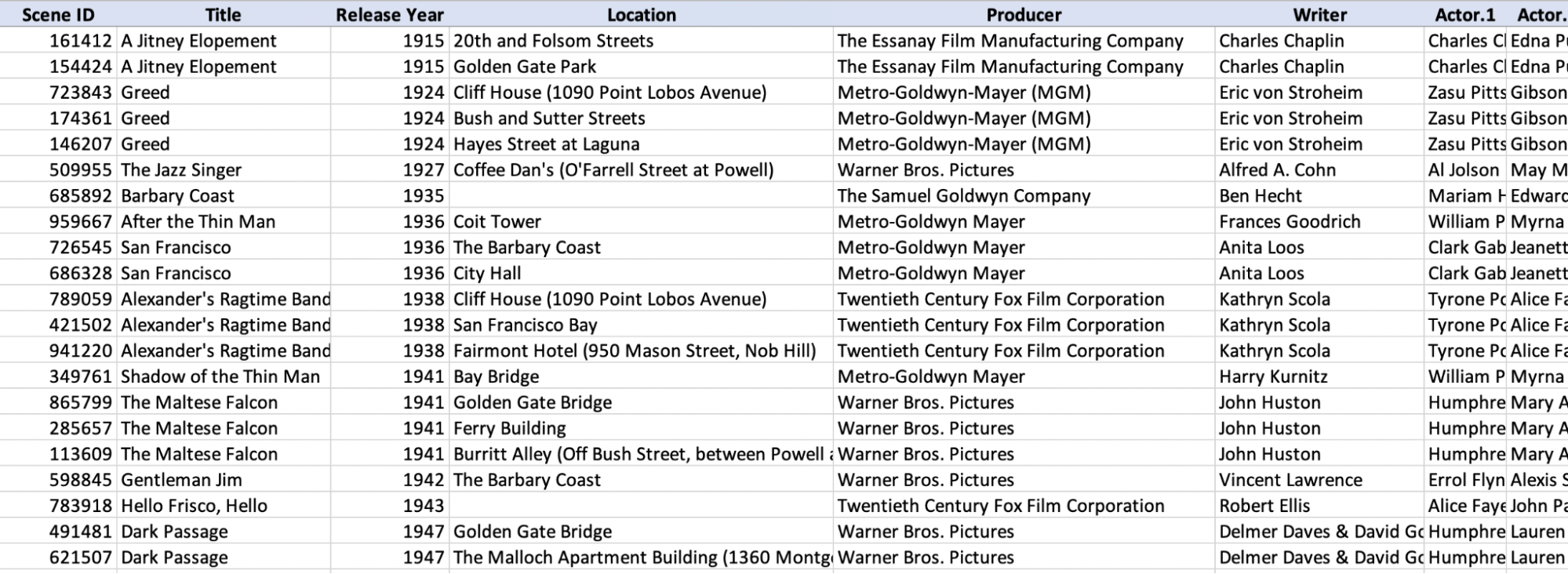
With this new table, the directors can exist independently from the scenes they've directed (or not), which is the first advantage.
But there is another important advantage. A single director is only present on a single row in this table. So, if you want to update some details about a director, you will only need to do it in one place. There will be no more inconsistencies due to data redundancy.
Hold on, though. We no longer know which director shot which film! The data is separated across two tables, with no link between them!
That’s an excellent observation! The solution is to use an identification system.
Assign each director an identifier (1, 2, 3, etc.), and add a column to hold the identifier for them in the movie scenes table. It allows the computer to link the two tables together quickly.
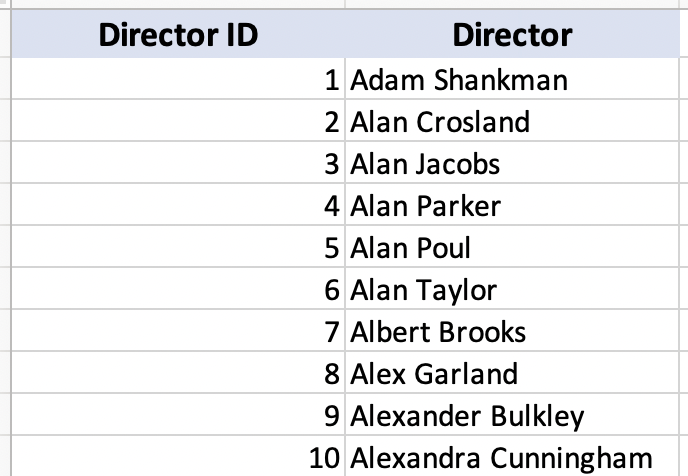
Have you ever asked yourself why? Well, it's because your ID allows the organization to link multiple tables within their database very easily.
This method belongs to the relational model (LDM). In database terminology:
The
director IDis the primary key of thedirector table.The column
Directedby in themovie_scenetable is a foreign key referring to the primary key of thedirectortable.
Let’s Recap!
Redundancy is when a piece of data is present in multiple places within a database.
Redundancy in a data table can lead to inconsistencies in the data.
The way to resolve redundancy in relational modeling is to separate the table into two and link them using a foreign key.
So there you have it! In this first part, you’ve learned about the different steps involved in modeling a database and the concept of redundancy, which you should avoid at all costs. Now it’s time to explore the first step of modeling in more detail: the CDM, which we’ll create using a UML class diagram.
