Collect Technical Information About the Application

In this chapter, we’ll learn how to identify the technical elements making up the target (server type and version, technical stack, etc.) and how to find these elements using the proxy.
Examine the Target and Look for Technical Information
Let’s return to our metaphor and carry on with our robbery!
So far, you haven’t done anything really wrong. You’ve done your research on the bank. Are there any premises with the bank’s name prominently displayed? What are the points of entry to the main building? It looks a bit suspicious, true, but it’s not necessarily wrong.
Let’s keep the momentum going!
As part of our penetration test, we’re now going to work on casing the technical environment behind our target. For example, we’ll see what brands of windows and doors we’ve identified that the bank uses for its main door, in the basement, and for maintenance access.
This will tell us whether there are any default options we can use, such as a default password, that would be equivalent to a master key for a lock. It could also reveal any underlying technical vulnerabilities or weaknesses that our vulnerability scanner may not have detected. (Remember, this is always possible, as tools are not infallible.)
During a penetration test, the more you know about your target, the more likely you are to understand where the vulnerabilities are and what the target needs to function properly. Most of the feedback I've received suggests that a detailed understanding of the application is necessary, sometimes even surpassing that of the developers themselves.
Knowing your target will enable you to:
fine-tune the lists you’ll use for your reconnaissance.
narrow down the types of vulnerabilities you’ll be looking for in the application.
identify the CVEs you want to exploit.
check whether any default configurations exist.
find out whether there are any default passwords.
search for blog articles discussing the security of the target technologies.
Collect Technical Information About the Application
How do you go about collecting technical information?
There are a number of ways to collect information on the type and version of technology used, both on the client side (JavaScript, CSS) and on the server side.
The easiest way is to look at the page’s source code, particularly the JavaScript/CSS files. You’ll be able to tell from the name alone which technology is being used, and sometimes even which version.
Secondly, information can sometimes come from error pages, such as those displaying “Page not found” or “This page does not exist” messages, which I’m sure you’ve seen before:
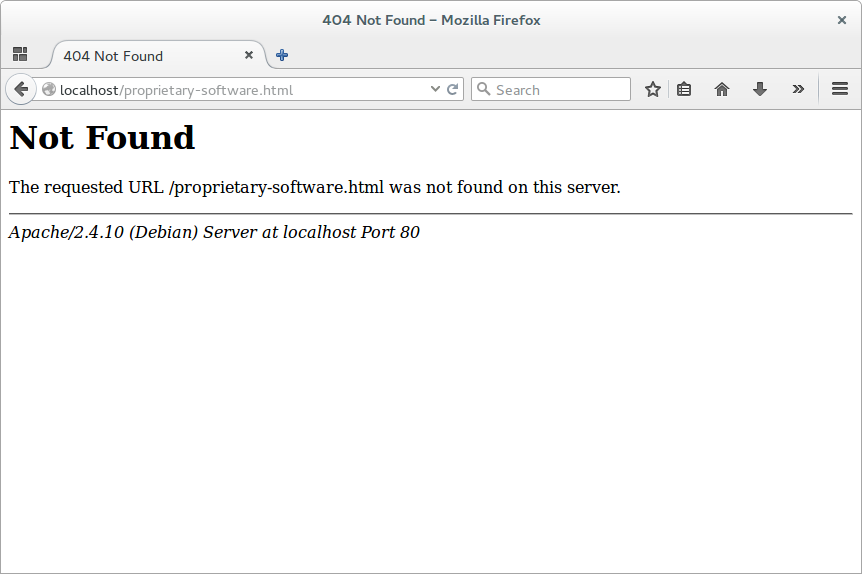
For example, this page shows the type and version of the web server used: Apache 2.4.10.
The default HTTP Server header also provides similar information, including the server type and sometimes its version:
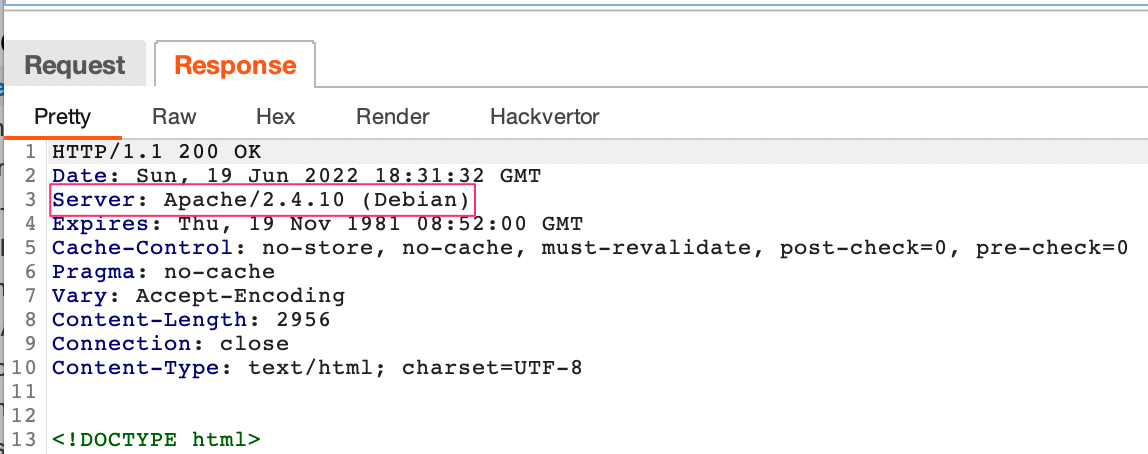
Lastly, you can detect the type and version of all or part of the technical stack used by calculating the hash of files or the presence of specific files.
Collecting all this information manually can be a bit tedious. As is often the case, there are various tools available to speed up this reconnaissance process. These tools can be:
either integrated into Burp, such as the Software Version Reporter extension (Professional version required).
or installed as browser extensions, such as Wappalyzer or WhatRuns.
Let’s Recap!
Understanding which technologies are behind the infrastructure and the application helps us to improve our knowledge of the target.
A thorough knowledge of our target helps us to narrow down our choice of lists, exploits, and related research. We can collect information on the underlying environment in a number of ways, including from HTTP headers, error pages, source code, and specific files.
There are powerful tools available for retrieving this information at the click of a button!
In the next chapter, we’re going to start looking for “hidden” pages, at least for standard users.
