Amazon Simple Storage Service (abrégé S3) est un service de stockage de données. En fait, il s'agit tout bêtement d'un moyen de stocker des fichiers sur Internet, qui est devenu très populaire. Si populaire que l'on pourrait même dire qu'il s'agit du service le plus célèbre d'AWS avec EC2.
Démystifions Amazon S3
Le concept de S3 est tellement simple que je me suis au début posé des questions. Du genre :
C'est un peu comme un hébergeur donc ?
Oui, mais pas un hébergeur de sites web. Il faut plutôt le voir comme un gros hébergeur de fichiers.
(En fait, on peut héberger des pages HTML basiques, mais pas de scripts PHP, Ruby...).
C'est un FTP ?
Non. S3 n'est pas accessible en FTP (qui est d'ailleurs un vieux protocole), mais vous verrez que cela y ressemble par bien des aspects. Vous pouvez y déposer des fichiers et les lire.
C'est payant ?
Il y a un usage gratuit qui vous suffira probablement au début (5 Go de stockage).
En temps normal, vous payez pour l'espace nécessaire, mais aussi pour le nombre d'envois et de téléchargements de fichiers, ainsi que pour la bande passante utilisée. Bref, cela a un coût, mais raisonnable si vous n'en avez pas un très gros usage.
Et concrètement, les gens s'en servent pour quoi ?
Pour stocker toutes sortes de fichiers sur Internet. Par exemple :
Netflix s'en sert pour stocker les fichiers vidéo de ses films et séries ;
Airbnb s'en sert pour stocker les images de ses utilisateurs ;
OpenClassrooms s'en sert pour stocker les images de ses cours, mais aussi les exemples et les vidéos à télécharger, ainsi que les travaux réalisés par les apprenants dans les activités et projets ;
beaucoup s'en servent aussi pour stocker des backups de leurs bases de données.
Identifiez les avantages de Amazon S3
En résumé, S3 est une sorte de gros hébergeur FTP... mais qui n'utilise pas FTP. "Okay", vous dites-vous. Mais qu'est-ce qu'on y gagne ? On pourrait très bien héberger les fichiers sur notre serveur web EC2, après tout !
Voici une petite liste d'avantages que S3 vous apporte :
Vous pouvez configurer facilement les droits d'accès pour chaque fichier. Qui peut lire, modifier et supprimer chaque fichier.
Vous pouvez chiffrer toute une partie du contenu sur S3 si vous le souhaitez pour des raisons de sécurité.
Vos fichiers peuvent être versionnés : vous pouvez revenir à une version précédente à tout moment !
Vos fichiers peuvent avoir une date d'expiration et être supprimés automatiquement au bout d'un moment.
Vos fichiers peuvent être répliqués automatiquement sur plusieurs datacenters AWS. Ainsi, vous diminuez le risque de perdre des données importantes.
Il n'y a pas de limite de place. Vous ne risquez pas d'être bloqué par un disque dur rempli (cela m'est déjà arrivé sur un serveur, et je peux vous dire que c'est une galère : le serveur devient fou 🤪).
Enfin, le stockage sur S3 peut coûter jusqu’à 4 fois moins cher que sur des disques EBS.
Découvrez la structure d'Amazon S3
Amazon S3 propose de stocker des données dans des buckets (littéralement, des... seaux). Ce sont des sortes de gros conteneurs qui peuvent stocker autant de fichiers que l'on veut (répartis dans des dossiers à l'intérieur, s'il le faut).
À l'intérieur de chaque bucket, vous pouvez déposer des fichiers (on parle d'objets) et y associer des métadonnées. Vous pouvez indiquer ce que vous voulez dans ces métadonnées (l'auteur du fichier, par exemple).
C'est relativement simple, et cela tombe bien puisque ça s'appelle Simple Storage Service.
S3 a tellement gagné en popularité qu’il est fréquent pour les grandes entreprises de stocker des centaines voire des milliers de To sur S3, sauf que tous les fichiers ne sont pas nécessairement récupérés avec la même fréquence.
Les images d’un site web sont chargées à chaque visite d’un utilisateur. Par contre, un backup de base de données n’est récupéré qu’une fois par an... et encore ! C’est dommage de payer le même prix de stockage pour ces deux types de fichiers.
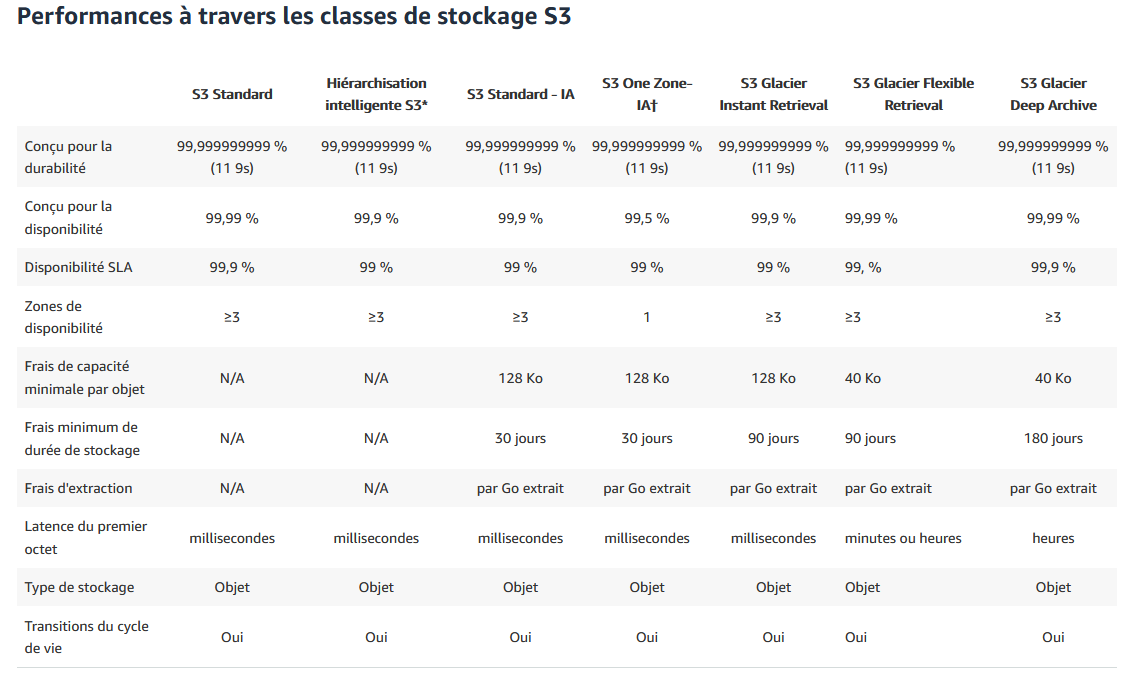
Ne vous inquiétez pas, AWS a prévu le coup ! Il a introduit différentes classes de stockage sur S3. Le principe est relativement simple. Moins un fichier est fréquemment utilisé, moins vous payez de frais de stockage.
Par exemple, un objet d’1 Go stocké en classe Standard coûte $0.023 par mois, et peut être récupéré en quelques millisecondes. Le même fichier stocké en classe “S3 Glacier Deep Archive” fait baisser le coût à $0.00099, soit 23 fois moins cher, mais nécessite d’attendre quelques heures avant de récupérer son fichier.
Vous pouvez consulter l’ensemble des classes de stockage sur le lien suivant. Elles présentent toutes des variations différentes de ce compromis prix/temps d’accès.
En résumé
Amazon S3 est un service AWS de stockage non structuré de fichiers bruts, appelés aussi objets.
Le prix de stockage sur S3 le rend attractif pour y déposer des sauvegardes volumineuses, des images de site web, etc.
Les données sur Amazon S3 sont stockées dans des compartiments (buckets). Chaque compartiment peut contenir plusieurs répertoires et fichiers.
Un fichier sur Amazon S3 peut appartenir à différentes classes de stockage selon le niveau d'accès requis. La classe de stockage S3 Glacier Deep Archive coûte 23 moins cher que la classe "Standard", mais nécessite d'attendre quelques heures avant de récupérer le fichier.
Voilà pour l’introduction à Amazon S3. Allez, si on l'utilisait dans le chapitre suivant ?
