Dans la leçon précédente, nous avons parcouru, à travers des exemples, la notion de données pour l'apprentissage. Nous allons maintenant explorer un deuxième point fondamental en apprentissage : le type de problème à traiter et voir les fonctions coût associées. Mais avant, nous allons commencer par préciser la notion d'apprentissage automatique.
Définissons l'apprentissage automatique comme un entraînement
Est-ce qu'une machine apprend comme un enfant ou un humain apprend ?
Un enfant met un an à apprendre à marcher, deux ans pour apprendre à parler et passe le reste de sa vie à continuer à apprendre pour acquérir des connaissances. Apprendre c’est développer de nouvelles compétences, attitudes et connaissances. La manière la plus efficace de le faire est avec un professeur qui vous explique (ou avec un livre). Le professeur, qui connaît les nouvelles compétences à acquérir et le niveau de l'apprenant, développe des stratégies qui facilitent l'apprentissage en utilisant les connaissances déjà acquises par l'apprenant.
L'automatisation de ce processus n'est pas d'actualité car les machines capables d'apprendre aujourd'hui sont loin de pouvoir réaliser de telles performances. Ce qu'elles arrivent à faire c'est apprendre, à partir de très nombreux exemples, à réaliser des tâches spécifiques, comme la reconnaissance d'objets ou celles que nous avons vue au chapitre précédent. Ce que l'on sait automatiser, c'est l'apprentissage vu comme un entraînement, la capacité à inférer à partir de nombreux exemples d'un problème spécifique un modèle capable de généraliser.
Les différents principes d'apprentissage
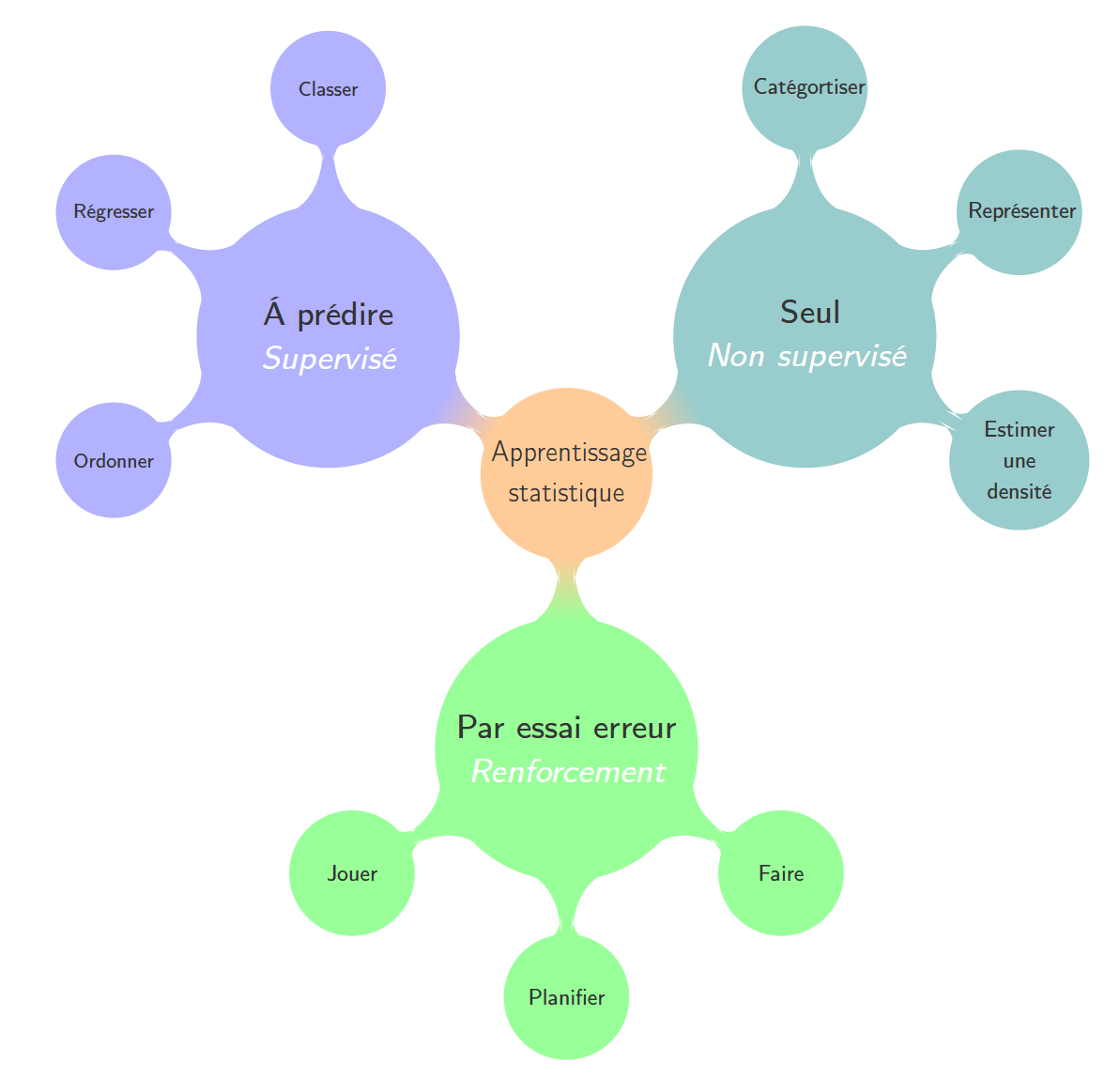
Deux distinctions en apprentissage
Comment classer les différents modes d'apprentissage ?
Dans le domaine de l'apprentissage statistique, les principaux types d'apprentissage peuvent être distingués selon qu'ils utilisent ou non un professeur et selon qu'ils sont passifs ou actifs. On parle d'apprentissage passif lorsque l'apprenti n'interagit pas avec son environnement.
Le type d'apprentissage le plus répandu est l'apprentissage à partir d’exemples couplés au résultat de la tâche à apprendre. C'est par exemple apprendre à reconnaître si un personnage est ou n'est pas Charlie à partir d'exemples d'images de personnages étiquetés Charlie ou non. Ces étiquettes jouent le rôle d'un professeur qui se contente, pour une situation donnée, de montrer la réponse souhaitée. Dans ce cas, on apprend passivement une compétence spécifique : comment prédire une caractéristique. On parle d'apprentissage supervisé.
Enfin on peut aussi chercher à apprendre seul (sans professeur), pour découvrir le sens d'un ensemble de données. C'est le cas quand on cherche à classer des photos. Ce type d'apprentissage passif est connu sous le nom d'apprentissage non supervisé.
On peut aussi apprendre par essai erreur. Dans ce cas, on explore de manière active son environnement en attendant qu'un « professeur » nous indique si on a bien fait. C'est comme ça que l'on apprend à jouer. On parle alors d'apprentissage par renforcement.
Pour terminer, on peut imaginer un mode d'apprentissage actif par exploration et sans récompense explicite, donc sans professeur. C'est un mode plus complexe qui commence juste à faire l'objet de recherches et dont l'étude dépasse le cadre de ce cours. Nous allons nous concentrer sur les trois modes les plus courants : l'apprentissage supervisé, l'apprentissage non supervisé et l'apprentissage par renforcement.

La notion de supervision, en apprentissage, fait référence au fait que les exemples disponibles sont annotés avec le résultat escompté. On parle d'apprentissage non supervisé quand les exemples disponibles ne sont pas annotés. Dans le cas de l'apprentissage par renforcement, on parle d'apprentissage faiblement supervisé.
Ce ne sont plus tous les exemples qui sont annotés, mais ceux qui, dans le cadre d'une séquence d'états, permettent d'évaluer la qualité des actions entreprises. Typiquement, à la fin d'un jeu si l'on a gagné, c'est que nos actions étaient appropriées et si l'on a perdu, c'est qu'il faut apprendre comment les modifier pour faire mieux la prochaine fois.
Trois modes d'apprentissage
Nous allons maintenant détailler, pour les trois principaux types d'apprentissage, les principales classes de problèmes associés.
Apprendre à prédire : l'apprentissage supervisé
Dans le cadre de l'apprentissage supervisé, il est classique de décrire les données disponibles comme des couples d’entrées associées à des sorties . Les entrées représentent les informations disponibles — comme des images, des sons ou des mesures — et les les variables à prédire. L'apprentissage consiste à inférer, à partir de ces exemples, les corrélations existantes entre des entrées observées et les sorties désirées. On peut différencier les méthodes d'apprentissage supervisées selon la nature des .
Si les sont des variables binaires on parle de discrimination (ou classification) bi-classe, comme dans l'exemple de classification des imagettes en Charlie ou non Charlie. Si les sont des variables entières finies, on parle de classification multiple comme quand on cherche à reconnaître un objet dans une image parmi une liste connue.
Quand est un réel ou un vecteur de réel (ou une fonction), on parle de régression. C'est le cas par exemple quand on cherche à prévoir une température, une consommation ou une concentration d'ozone.
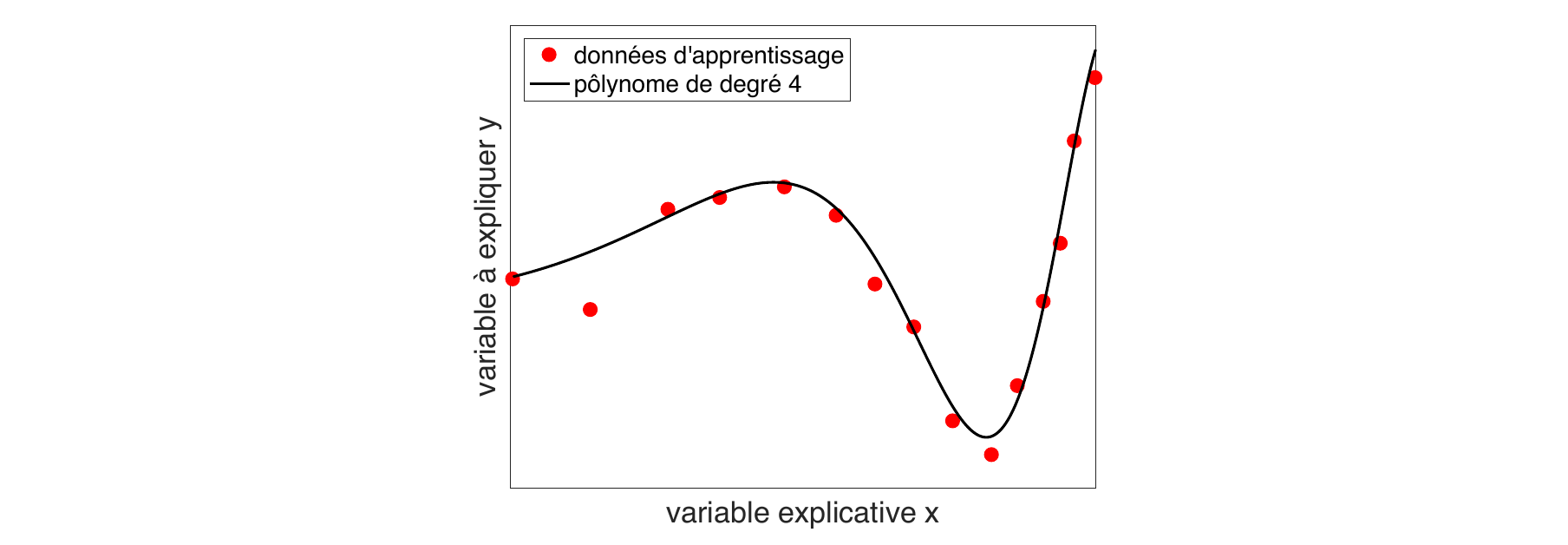
Si la variable est une variable ordinale, on parle de régression ordinale. C'est le cas par exemple quand est une variable indiquant une préférence comme un nombre d'étoile associée à une prestation.
La variable à prédire peut aussi avoir une structure plus complexe, comme un arbre ou un graphe. Par exemple, construire l'arbre syntaxique associé à une phrase en langage naturel peut être considéré comme un problème de prédiction structurée dans lequel le domaine de sortie structuré est l'ensemble de tous les arbres d'analyse possibles. On parle alors du problème de prédiction (ou de régression) structurée.
Apprendre à résumer : apprentissage non supervisé
Dans le cas où les données disponibles ne sont pas étiquetées, on dispose uniquement d'entrée x et pas de sorties y, on parle d'apprentissage non supervisé. Là aussi, il existe différentes manières de voir cet apprentissage non supervisé.
On peut vouloir créer des catégories d'objets analogues. On parle alors de classification non supervisée ou clustering en anglais. L'objectif est de créer une partition des données en regroupant les données similaires, appliquant l'adage selon lequel "qui se ressemble s’assemble". C'est le cas, par exemple, quand on dispose d'un ensemble de documents que l'on cherche à classer en regroupant ceux qui sont comparables.

Cliquez ici pour afficher en plein écran l'image des deux classifications.
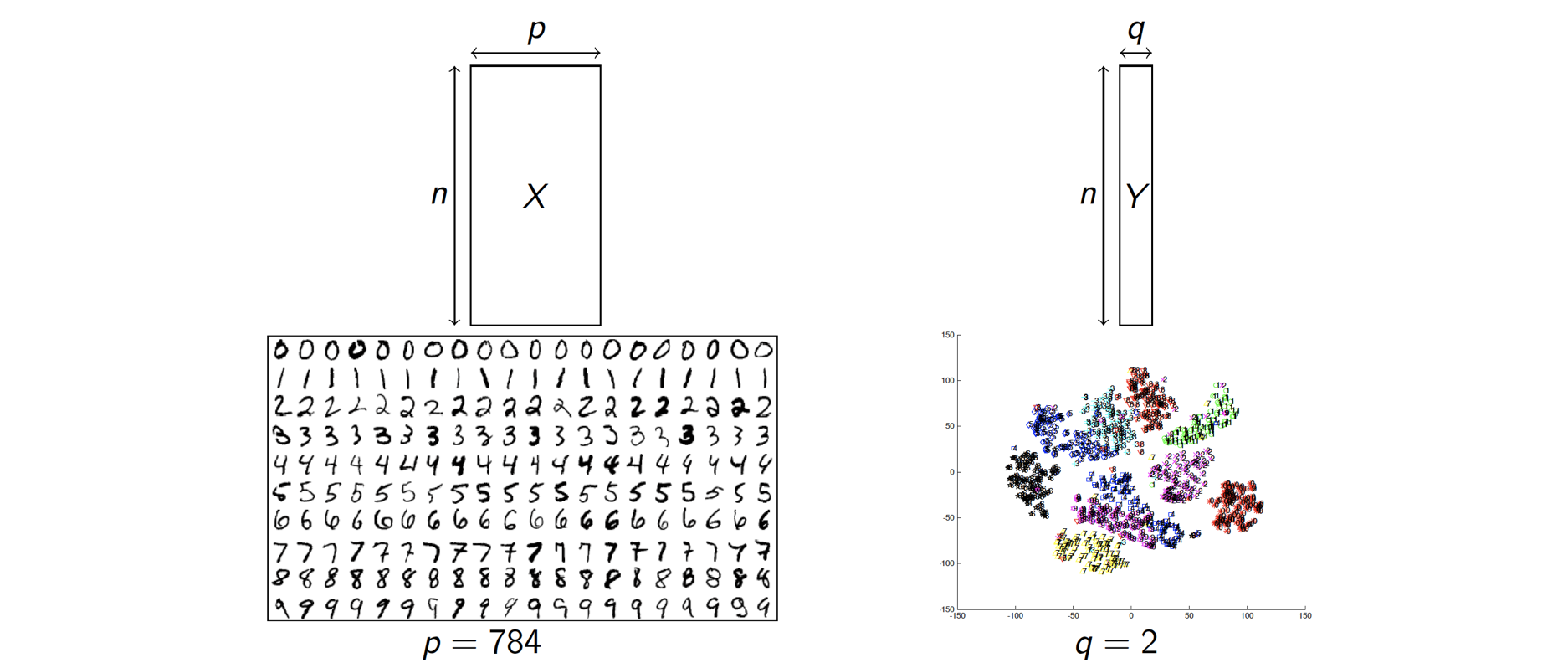
La réduction de la dimensionnalité est une autre tâche associée à l'apprentissage non supervisé. L'objectif dans ce cas est de trouver une représentation de faible dimension permettant de bien représenter les données. Typiquement, si , le problème de représentation peut être formalisé comme la recherche d'une fonction d'encodage de
L'idée est de résumer les données en éliminant du bruit et en faisant apparaître variables cachées pertinentes. Lorsque ou 3, le problème de représentation devient un problème de visualisation avec pour objectif la détection de points aberrants, la validation d'un encodage ou la recherche de groupes de données homogènes. Il est parfois utile d'associer à la fonction d'encodage une fonction de décodage, permettant de reconstruire une entrée à partir de sa représentation. On parle alors d'auto-encodage.
Apprendre par essai erreur : apprentissage par renforcement
L’apprentissage par renforcement est la technique utilisée pour apprendre à jouer automatiquement. C'est un domaine de l’apprentissage automatique qui s'intéresse à la façon dont un agent (le programme qui joue) doit agir dans un environnement donné (le jeu) afin de maximiser des récompenses (gagner à tous les coups).
Le cadre général est différent de celui des apprentissages supervisé et non supervisé. Il suppose l'existence d'un environnement avec lequel l'agent interagit temporellement et qui peut lui envoyer des récompenses. L'objectif est alors de trouver un équilibre entre le besoin d'explorer l'environnement inconnu (tester de nouveaux coups) et la tentation d'exploiter les connaissances acquises pour en tirer des récompenses. C'est le dilemme exploration/exploitation.
Au-delà des principes
Il existe d'autres manières de présenter les problèmes, par exemple en fonction de leur taille ou de leur domaine d'application et de la nature des données à traiter (image, son, vidéo, langage naturel, séquences...).
Dans un problème concret, il est souvent nécessaire de combiner plusieurs approches. Typiquement on commence par une méthode de réduction de dimension, suivie d'une méthode de discrimination. L'apprentissage automatique (AutoML pour Automated machine learning) consiste à chercher une approche globale permettant d'automatiser de bout en bout l'application de ces méthodes d'apprentissage automatique à des problèmes concrets. Des logiciels comme scikit-learn offrent cette fonctionnalité.
En résumé
L'apprentissage statistique relève plus de l'entraînement que de la création de connaissance. Dans ce cadre, les trois principaux types de problèmes d'apprentissage statistique sont :
l'apprentissage supervisé, quand chaque observation est associée à une étiquette ;
l'apprentissage par renforcement, quand chaque séquence d'action est associée à une récompense ;
l'apprentissage non supervisé, quand on ne dispose pas d'étiquette.
Nous allons maintenant voir des exemples de modèles utilisés en apprentissage statistique.

{kind=link}