L'objectif du cours est de :
comprendre les problématiques liées au traitement de données à large échelle,
se familiariser en particulier avec la complexité en temps et la complexité mémoire des algorithmes que nous avons vu dans ce cours,
apprendre à mettre en œuvre les méthodes de type gradient stochastique et leurs variantes pour casser la complexité algorithmique.
Analysez la complexité algorithmique
Nous avons vu dans les chapitres précédents des méthodes d'apprentissage statistique pour :
la réduction de dimension (ACP),
le clustering (K-Means),
la régression linéaire (avec ou sans régularisation),
la classification (régression logistique et SVM).
Ces méthodes requièrent de résoudre des problèmes d'optimisation qui dépendent du nombre et la dimension des données. La problématique de l'apprentissage à large échelle apparaît lorsque ce nombre d'observations est très grand et/ou la dimension augmente. Le tableau 1 illustre la volumétrie de quelques bases de données publiques liées à l'IOT.
Données | Nombre de points | Dimension |
7.062.606 | 115 | |
919.438 | 11 | |
43.930.257 | 16 |
Tableau 1 : Exemples de données IOT
Pour appréhender la problématique, nous allons rappeler le principe des algorithmes étudiés dans les précédents chapitres et analysez leur complexité.
Analyse en composantes principales
Elle vise à projeter linéairement des données centrées en des points de dimension en utilisant la matrice de projection . Les colonnes de sont les vecteurs propres de la matrice de covariance
La complexité de l'ACP se décompose comme suit :
Ressources mémoire : pour stocker la matrice ,
Complexité en temps : le calcul de requiert opérations et celui de nécessite opérations.
K-Means
Cette méthode itérative de catégorisation des données en clusters, comprend à chaque itération deux étapes : (i) une étape d'affectation des points à un cluster, et (ii) une mise à jour des centres. Sa complexité est de deux ordres :
Complexité mémoire :
pour les données augmenté de pour le stockage des centres, soit principalement le coût de stockage des données ;
Complexité en temps : (i) affectation des points aux clusters : et (ii) mise à jour des centres :
La complexité calculatoire globale est de l'ordre de où est le nombre total d'itérations.
Régression linéaire
Elle consiste à apprendre le modèle linéaire à partir de données . Les paramètres sont estimés par minimisation du critère des moindres carrés Nous avons établi que la solution est
où et sont respectivement la matrice des entrées et le vecteur de sortie. Cela engendre :
une compléxité mémoire de pour stocker la matrice et pour le vecteur ;
opérations pour le calcul de et opérations pour calculer . Le calcul de coûte opérations.
Cette complexité est similaire si l'on considère la régression ridge.
Régression logistique linéaire
Dans le cadre d'un problème de classification binaire de données , les paramètres du modèle de régression logistique linéaire se déterminent par résolution du problème
Nous avons vu qu'on pouvait utiliser la méthode de descente de gradient pour calculer itérativement les paramètres Le calcul du gradient nécessite environ opérations ; nous déduisons, si on effectue itérations, une complexité en temps de l'ordre de .
SVM
Nous avons montré dans le chapitre précédent que l'apprentissage d'un modèle SVM linéaire nécessite de résoudre le dual, qui est un problème de programmation quadratique. Une implémentation directe (et un peu naïve) du problème dual nécessite une complexité en temps de et une complexité en mémoire de pour stocker la matrice de noyau avec .
Adaptez ces algorithmes à la large échelle
Comment faire tourner ces méthodes sur son ordinateur personnel si et sont grands
Nous pouvons exploiter la structure des problèmes d'optimisation liés à ces algorithmes. Considérons les modèles de régression linéaire, régression logistique ridge et SVM de la forme . Leur problème d'optimisation peut s'écrire sous la forme générale
avec et la fonction de perte (voir figure 1) :
pour la régression linéaire
pour la régression logistique,
pour le SVM.
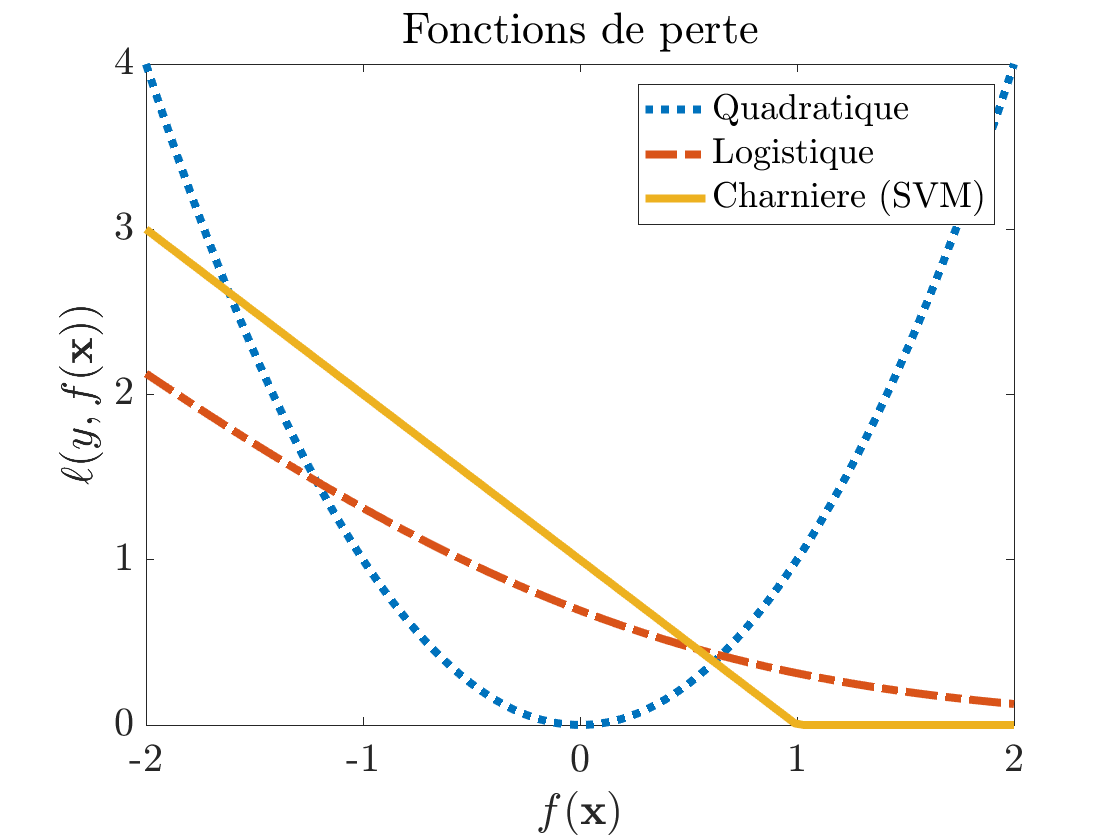
La premier terme de l'équation (3) mesure l'adéquation entre la prédiction et la vraie sortie (terme d'erreur) ; le second terme est la régularisation ridge. La remarque importante à faire, c'est que le critère J(\boldsymbol{\beta}) s'écrit comme la somme de éléments : c'est cette information que nous allons exploiter.
Au lieu d'utiliser simultanément toutes les données pour calculer les paramètres de ces modèles comme dans les équations (1) et (2), on cherche à casser la complexité en temps en sous-échantillonnant et en traitant les données par petits lots (le cas extrême est de les traiter une à une). Qu'est-ce que cela change ? Cela aboutit à considérer des algorithmes stochastiques de résolution dont certains sont présentés ci-dessous.
Approches de gradient stochastique
Nous allons nous concentrer dans cette partie sur les problèmes de régression linéaire ou de régression logistique pour la classification binaire pour illustrer le principe des approches stochastiques.
Gradient stochastique (Stochastic Gradient Descend, SGD)
Le principe de cette approche pour résoudre le problème (3) est résumé par les lignes suivantes :
Initialisez et
A chaque itération
tirez aléatoirement un point , des données d'apprentissage ;
calculez le gradient partiel ;
mettez à jour les paramètres par avec le pas ;
(Optionnel) moyennez les estimées .
Quels sont les avantages et les inconvénients du SGD ?
Chaque itération de la méthode du gradient (voir équation (2)) nécessite le calcul du gradient global , qui est la somme de gradients partiels. Il faut donc "visiter" tous les points d'apprentissage avant de faire la mise à jour des paramètres. A contrario, le gradient stochastique se contente d'un gradient partiel courant pour mettre à jour les paramètres.
La complexité par itération est donc :
pour la méthode du gradient, opérations,
pour la méthode du gradient stochastique, opérations.
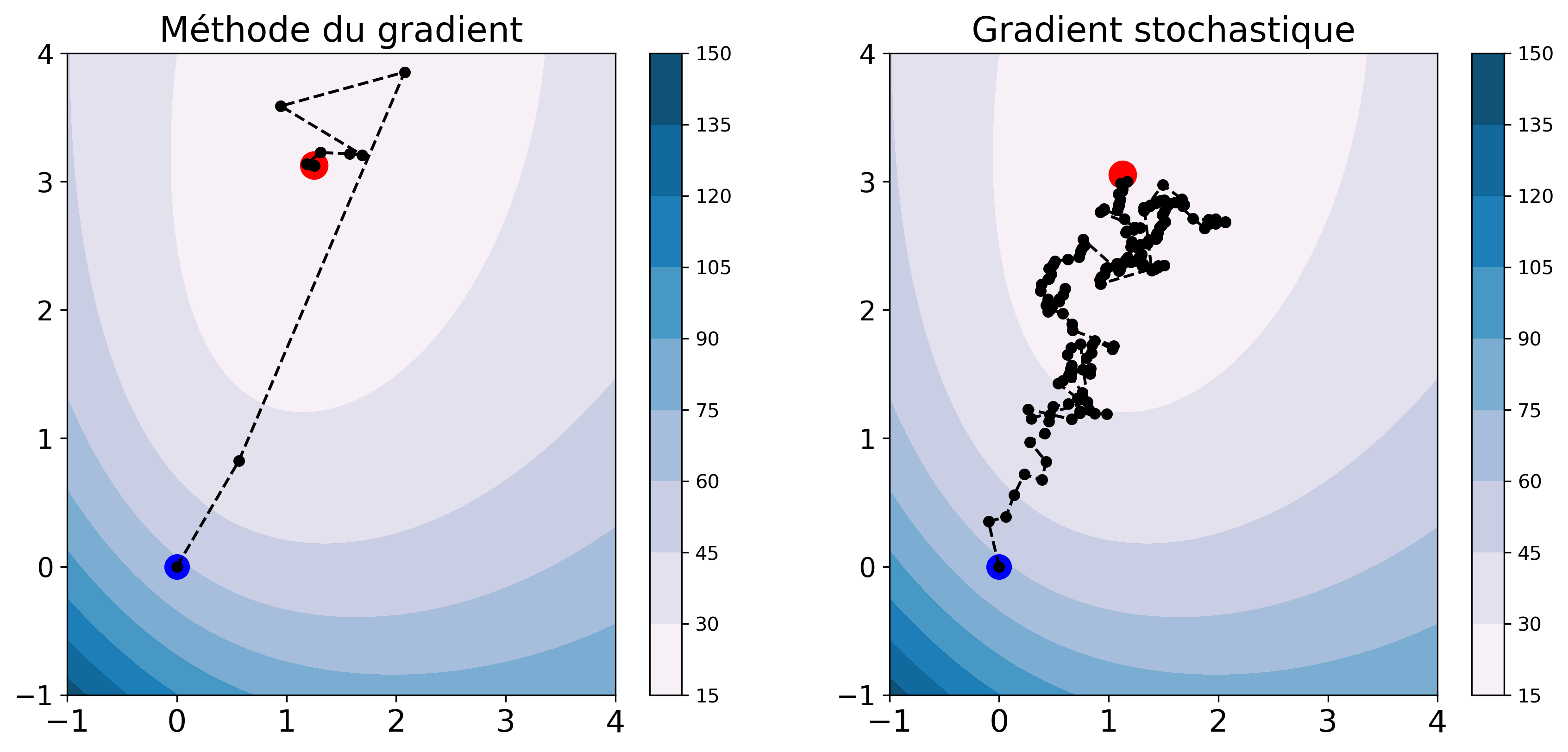
Nous comparons, sur la figure 2, l'évolution des paramètres au fil des itérations pour la méthode du gradient et du gradient stochastique. Sur chaque graphe, les points bleu et rouge représentent respectivement l'initialisation et la solution et les points noirs les solutions intermédiaires. Les lignes de niveau sont celles du critère d'entropie binaire.
Nous constatons que les estimations du SGD évoluent de façon un peu erratique sur les lignes de niveau. Chaque estimation ne conduit pas nécessairement à une diminution du critère à cause du gradient partiel, mais au final le SGD converge vers une solution proche de celle du GD.
SAG (Stochastic Average Gradient)
Cette technique vise à obtenir les avantages des deux méthodes : la complexité par itération du SGD et le nombre d'itérations (la vitesse de convergence) de la méthode du gradient. Son principe est de calculer une approximation du gradient meilleure que le gradient partiel du SGD. Il est illustré ci-dessous :
Initialisez , et les gradients partiels
À chaque itération
tirez aléatoirement un point , des données d'apprentissage,
calculez
calculez une approximation du gradient
mettez à jour le gradient partiel \tilde{\mathbf{g}}_i = a_t
mettez à jour les paramètres avec le pas.
Nous constatons donc que cette approche permet d'obtenir le meilleur des deux mondes : le coût par itérations du SGD et la vitesse de convergence du GD, moyennant des ressources mémoire supplémentaires pour stocker les gradients partiels. La figure 3 compare la vitesse de convergence de GD, SGD et SAG. On constate au début la décroissance plus rapide de pour le SGD, comparativement à GD suivi d'une stagnation. SAG fait décroître plus rapidement l'écart à l'optimum avec un taux de décroissance linéaire.
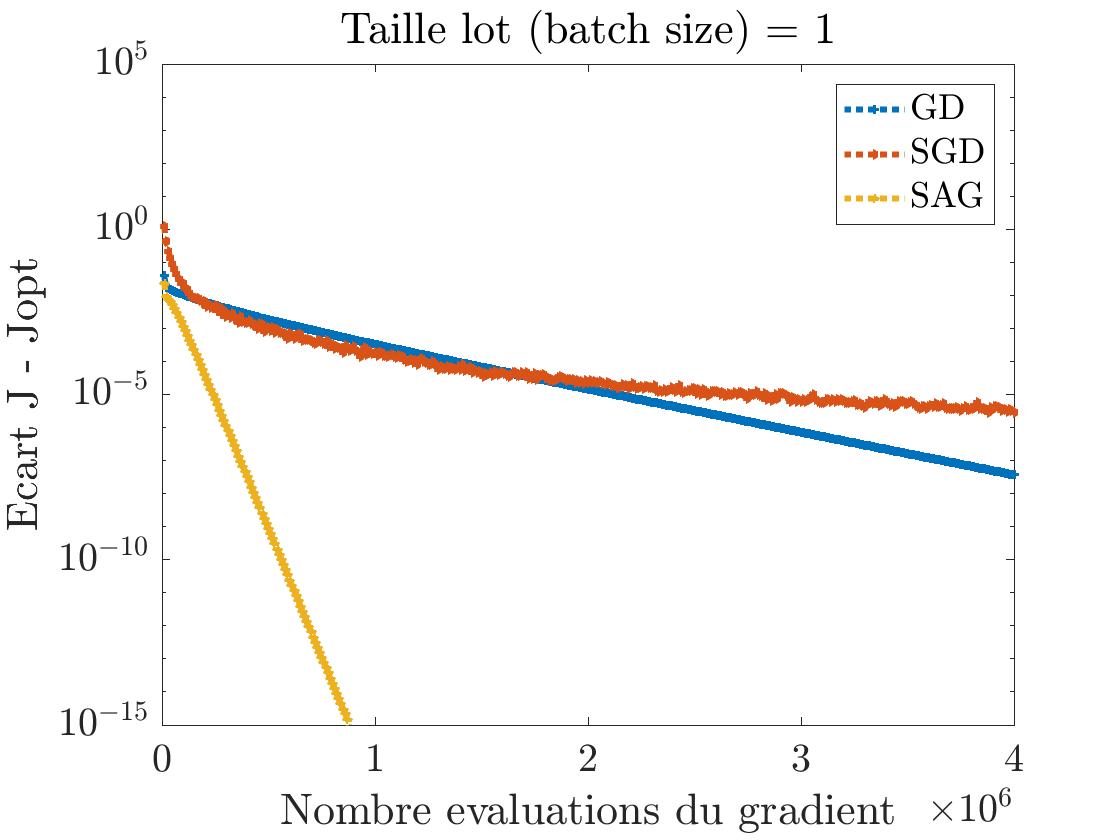
Notons qu'il existe d'autres approches stochastiques pour résoudre le problème (3) comme SAGA ou SVRG. Sous scikit learn, pour apprendre un modèle de régression logistique plusieurs solveurs, sont proposés comme solveurs : Newton-CG, L-BFGS (des méthodes d'optimisation de type 2e ordre), SAG ou SAGA. La régression linéaire ridge avec scikit learn peut également se résoudre avec des solveurs SAG ou SAGA. Il faut donc choisir le solveur le plus adapté à la volumétrie et à la dimensionalité des données d'apprentissage.
En résumé
Trouver un modèle de machine learning revient généralement à résoudre un problème d'optimisation défini à partir de données. Ce problème se formule souvent comme la somme de fonctions de perte sur les points d'apprentissage et d'un terme de régularisation du modèle. Ce chapitre a permis de comprendre :
les problématiques de complexité algorithmique liées à la résolution du problème d'optimisation pour des données à large échelle,
le principe des approches stochastiques utilisées pour casser la complexité algorithmique et obtenir des solutions raisonnables en temps raisonnable.
Ce sont ces stratégies qui sont utilisées dans l'apprentissage des réseaux de neurones (deep learning).
Nous n'avons pas abordé dans ce chapitre les approches distribuées pour gérer la large échelle. Ces approches consistent à paralléliser massivement les calculs sur plusieurs machines. Vous pouvez consulter le cours "Réalisez des calculs distribués sur des données massives" pour en savoir plus.
Vous êtes arrivés à la fin de ce cours, félicitations ! À présent, vous avez toutes les clés en main pour :
décrire la démarche et la méthodologie de l'apprentissage statistique ;
mettre en place un modèle d'apprentissage statistique adapté à son besoin ;
mettre en œuvre des modèles d'apprentissage statistiques.
N'oubliez pas de réaliser les exercices à la fin de chaque partie pour valider ces compétences. Ensuite, vous pouvez poursuivre votre apprentissage avec le cours "Initiez-vous au Deep Learning". Nous vous souhaitons une bonne continuation dans tous vos projets !
