A la fin de ce chapitre, vous serez capable de :
analyser un tableau de données,
projeter les données afin de les visualiser,
faire le clustering des données.
Initiez-vous à l'analyse en composantes principales
Dans cette partie, nous allons apprendre à résumer un tableau de données par l'analyse en composantes principales (ACP).
C'est quoi l'ACP ?
C'est une technique linéaire permettant de projeter des données de dimension en d'autres données de dimension . On parle de réduction de dimension. L'idée de l'ACP est de projeter les données sur des axes préservant la variance des données. Si on s'arrange pour que p=2 ou 3, on peut alors visualiser les données projetées.
Les données
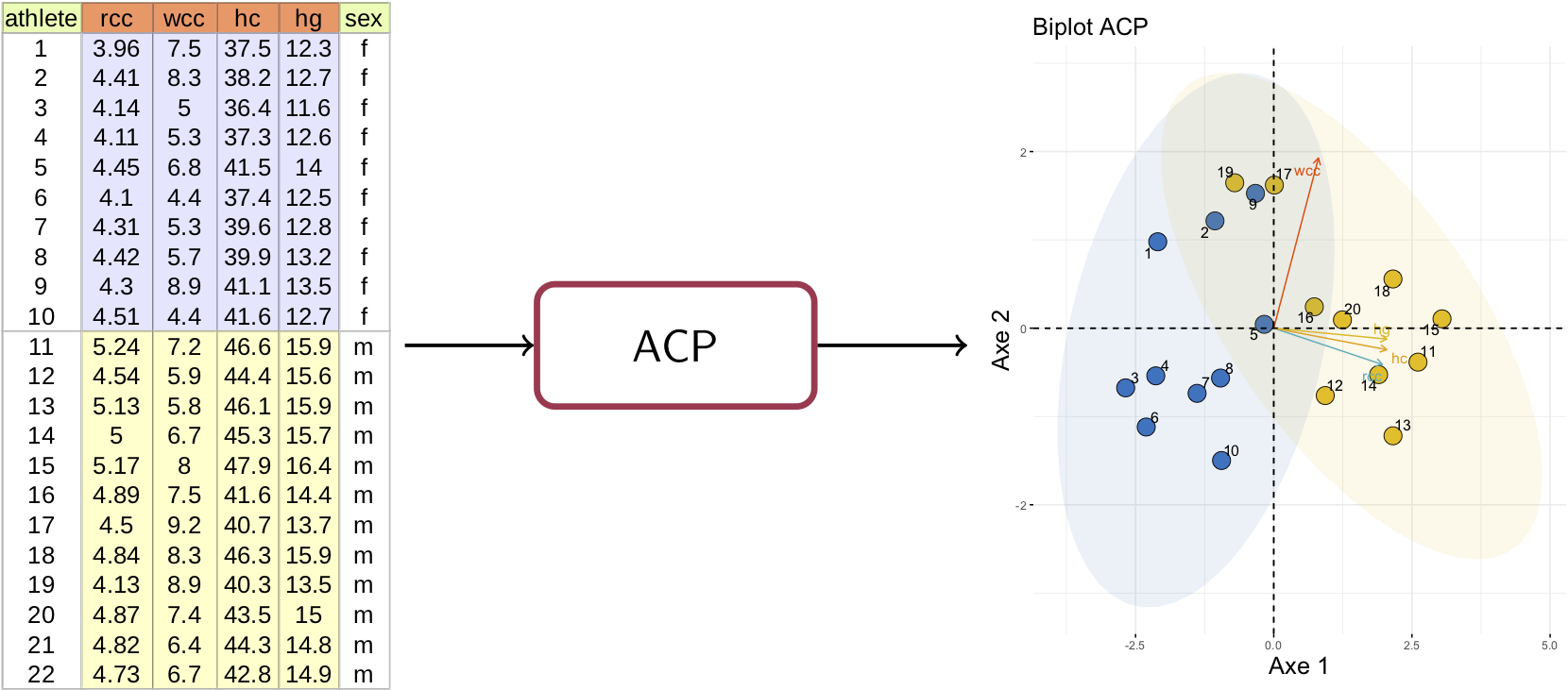
Le tableau suivant comporte des données biologiques mesurées sur plusieurs sportives et sportifs. Ces paramètres biologiques sont par exemple la concentration d'hémaglobine (hg), le taux d'hématocrite (hc), la quantité de ferritine (ferr), l'indice de masse corporelle (bmi) ou la taille (ht). La description complète de ces paramètres se trouve ici.
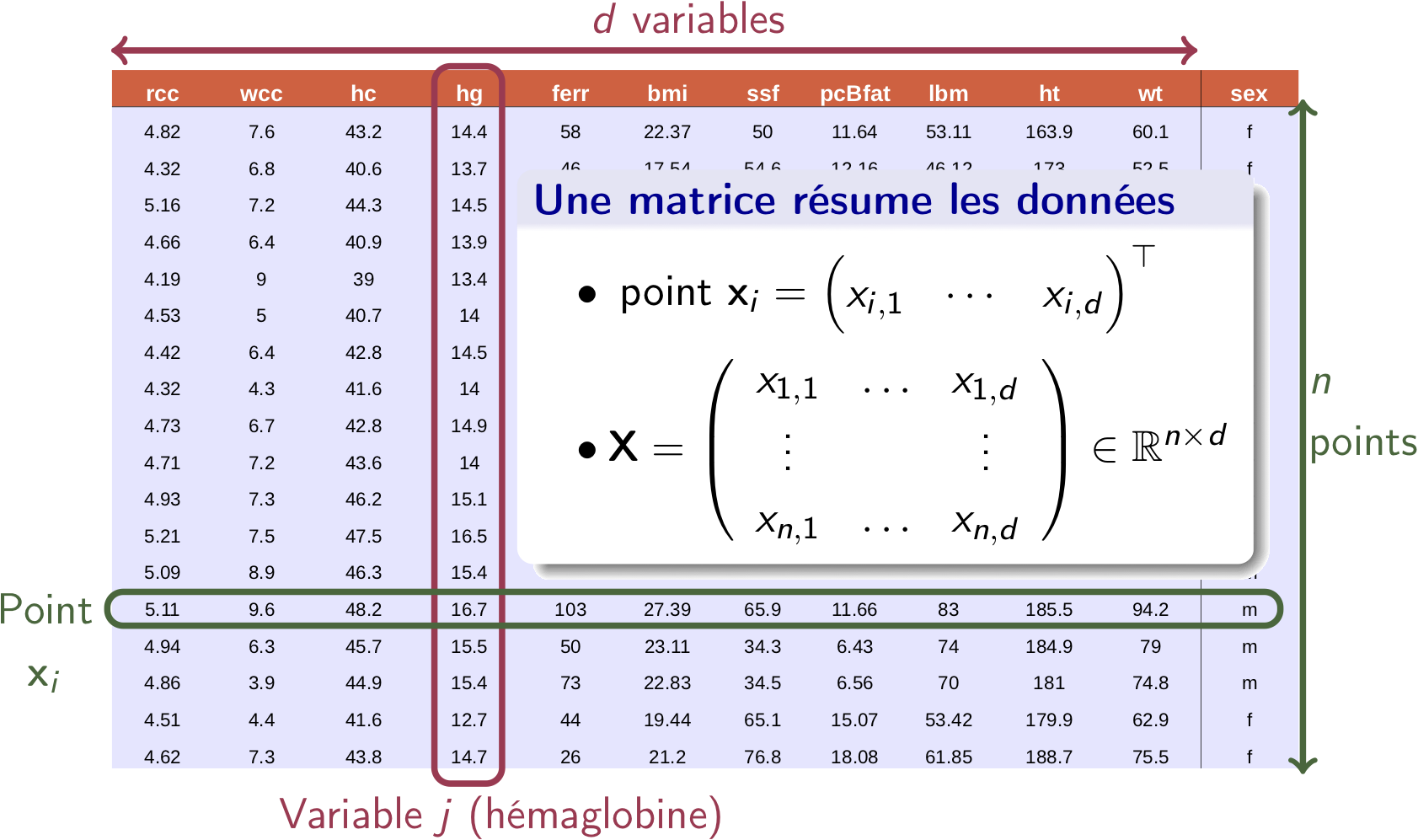
Chaque colonne du tableau représente une variable. L'hémoglobine (hg) est la 4e variable, le tableau en comportant (la dernière colonne servant juste à distinguer les sportives et les sportifs).
Une ligne du tableau représente un sportif qui est décrit par ses variables. La ième ligne est le point , un vecteur de dimension dont les éléments sont .
Pour sportifs, nous aurons vecteurs ; le tableau est simplement une matrice de dimension .
Analyse des données
On peut mener une première analyse statistique des données en traçant les boxplots (boîtes à moustache) des variables, comme sur la figure suivante.
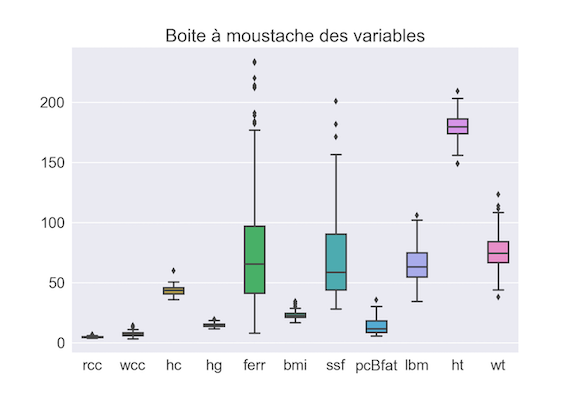
Nous pouvons faire quelques remarques :
Les variables n'ont pas les mêmes ordres de grandeur (rcc, wcc prennent de petites valeurs comparativement à ferr ou ssf).
Les variables ferr, ssf ont une grande variance alors que d'autres comme rcc ou hg varient peu en proportion.
ferr, ssf présentent quelques valeurs atypiques.
Cette anaylse est un peu limitée parce qu'elle ne permet pas de déterminer le lien entre différentes variables. (Quel est le lien entre la concentration d'hémaglobine hg et le taux d'hématocrite hc ?) Elle ne permet pas non plus de comparer en un coup d'oeil deux sportifs. Il faut donc un autre outil pour approfondir la compréhension des données : ce sera l'ACP.
L'analyse en composantes principales
Prenons l'exemple suivant : on a points en 3D (graphique de gauche) qu'on souhaite projeter en 2D.
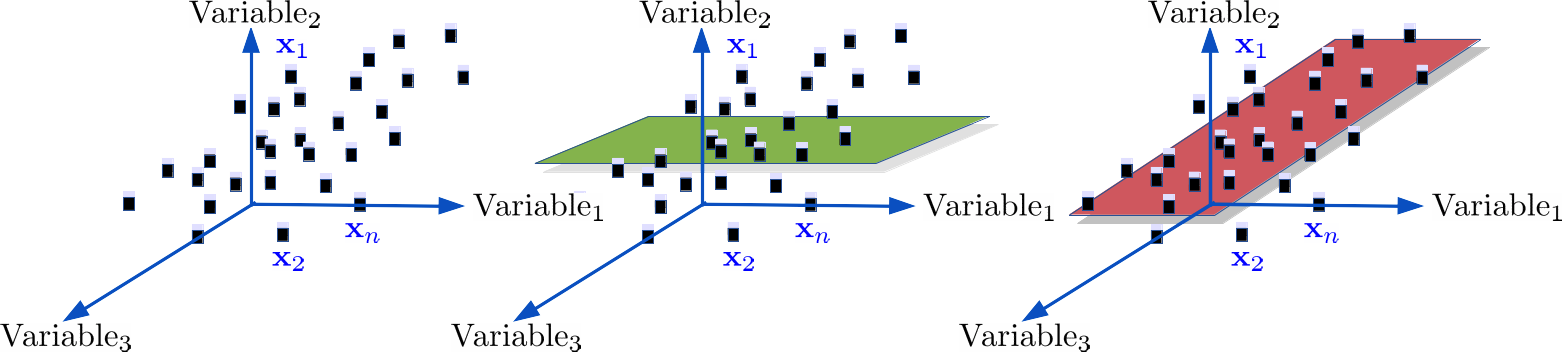
Si l'on projette sur le plan en vert (figure du milieu), les points seront confondus. A contrario, sur le plan en rouge (figure à droite), la dispersion des points sera préservée c'est-à-dire qu'on maximisera la variance des points après projection.
Comment trouver le bon espace de projection ?
On cherche à réaliser la projection
L'espace de projection sera construit de manière progressive :
D'abord, on va chercher le meilleur axe de projection (1D) .
Ensuite, on détermine le meilleur plan en trouvant le deuxième axe .
Et ainsi de suite jusqu'à obtenir .
Préalable
Il faut centrer et réduire les données (nous reviendrons dessus) :
avec et la moyenne et la variance de la variable .
Recherche de la première direction de projection
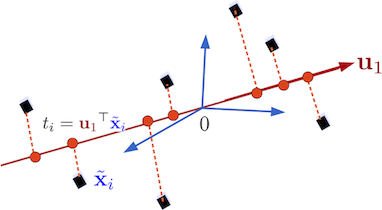
On veut :
un vecteur normé ,
la projection orthogonale des points sur soit de variance maximale.
Le problème de maximisation de la variance est alors :
En utilisant les astuces mathématiques on a :
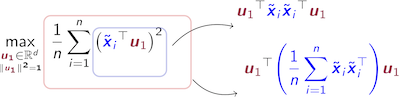
Ceci nous permet de reformuler le problème sous la forme suivante :
Recherche de la deuxième direction de projection
Comme précédemment, le deuxième vecteur doit :
être normé ,
maximiser la variances des projections sur ,
être orthogonal à pour former une base de (voir figure).
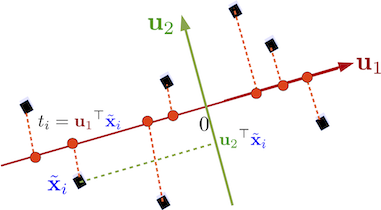
et ainsi de suite pour avoir des directions de projections supplémentaires.
Comment coder l'ACP soi-même ?
L'algorithme tient en quelques lignes :
Centrer et réduire les données :
Calculer
Trouver la décomposition en valeurs propres de :
Trier les valeurs propres par ordre décroissant et les vecteurs propres en conséquent
Construire la matrice de projection en dimension
Utilisation de l'ACP
Revenons aux données biologiques. Pour en faire l'ACP, on a besoin de la matrice de corrélation des variables. Commençons par tracer les données par paires de variables :

Nous constatons que certaines variables sont linéairement dépendantes (graphiques entourés en rouge). Nous pouvons quantifier ceci en examinant la matrice de corrélation .
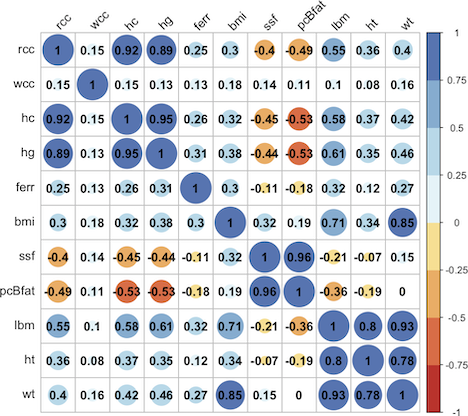
est symétrique, avec des 1 sur la diagonale (normal car une variable est forcément fortement correlée avec elle-même). On voit, par exemple, que les variables et ont un coefficient de corrélation de 0.95, et ont une corrélation de 0.92 ou et une corrélation de 0.96. Comment ces informations sont exploitées par l'ACP ? Voir la partie "Visualisation des données".
Projection des données
Une fois qu'on a calculé les moyennes et les écart-types des variables, puis la matrice la projection en dimension p d'un point quelconque en est résumée par le schéma suivant :
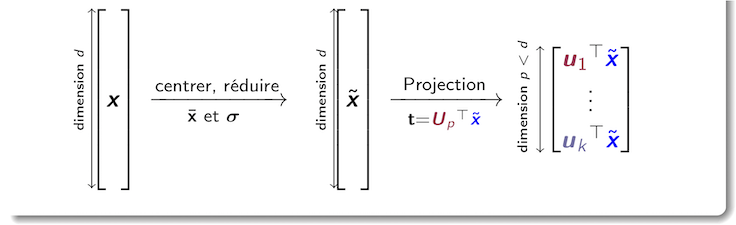
Visualisation des données
Prenons ; les données projetés sont en 2D et nous pouvons les visualiser.
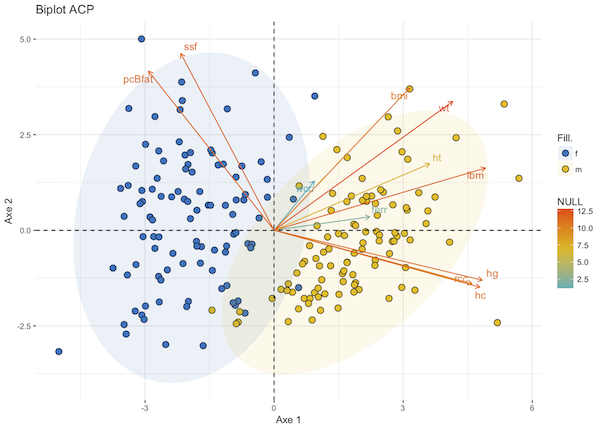
Comment analyser ce graphique ?
Chaque point représente un athlète. Si nous colorons les points en fonction du genre, on voit apparaître deux groupes homogènes. Nous pouvons donc visuellement comparer les sportifs entre eux.
L'axe est essentiellement déterminé par la combinaison linéaire des variables d'un côté et de l'autre. Nous pouvons voir, sur la matrice de corrélation, que ces variables ont des coefficients de corrélation linéaire plus forts entre elles qu'avec les autres variables.
L'axe est lui déterminé par les variables qui ont des corrélations négatives avec les variables liées à l'axe 1.
Le degré de contribution de chaque variable à l'axe de projection est lié à sa couleur et à la longueur de la flèche.
Les variables corrélées avec les axes 1 et 2 sont les plus importantes pour expliquer la variabilité (la variance) dans le jeu de données. Les autres variables apportent peu d'informations et peuvent être ignorées dans l'analyse des données.
Comment choisir le nombre d'axes ?
La réponse n'est pas simple. Comme l'ACP détermine l'espace de projection en maximisant la variance des données, nous pouvons visualiser la variance expliquée par chaque axe.
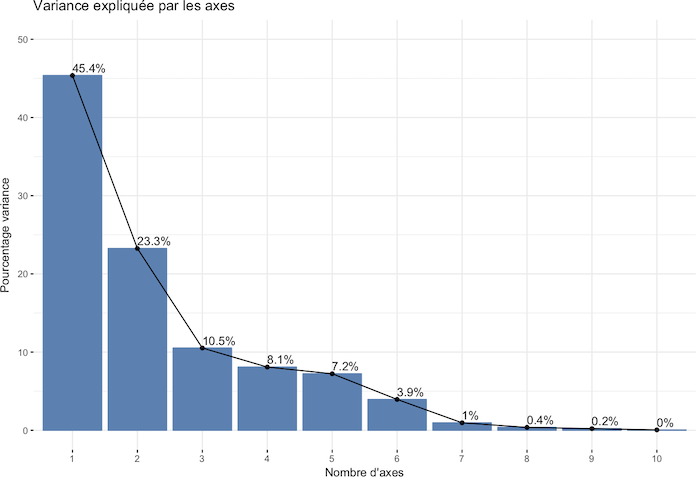
Les directions de projection avec les plus grandes variances sont les plus “importantes” (principales). La première direction explique 45% de la variance des données et les trois premières directions expliquent près de 80% de la variance. Les 4 dernières directions ont peu d'influence. Au vu du graphique, on peut retenir ou (oui, ce n'est pas simple).
En résumé
Pourquoi faire une ACP ?
Pour analyser les liens de corrélation linéaire entre les variables, représenter les points, réduire la dimension des données.
Comment faire l'ACP ?
Faire la décomposition en valeurs propres de la matrice de corrélation, projeter les données sur les p premiers vecteurs propres.
Deuxième partie : Comprenez l'algorithme K-Means pour le clustering
Dans la première partie du chapitre, nous avons vu comment résumer les données en réduisant leur dimension. Dans cette partie, nous allons voir comment résumer les données par regroupement en classes homogènes : c'est le clustering. Nous allons étudier pour cela la méthode des K-Means, aussi appelée méthode des centres mobiles.
Qu’est-ce que le clustering ?
Le clustering, que l’on appelle également partitionnement, est une technique d'exploration des données qui vise à déterminer les relations de similarité entre des points.
Étant donné un ensemble de points en dimension qu'on va noter , l'idée est de regrouper ces points en classes homogènes.
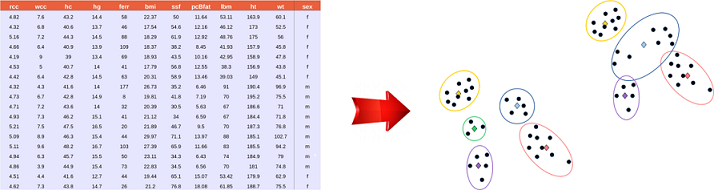
Comme le montre cette figure, le clustering permet d’obtenir des classes distinctes dans lesquelles les points seront les plus similaires possibles en se basant sur une notion de distance.
Le clustering s'utilise dans plusieurs domaines d'applications. Par exemple, il permet de réaliser la segmentation de la clientèle d'un magasin à partir des informations sur les clients et la liste de leurs achats :

On peut également appliquer le clustering pour réaliser la compression des couleurs d'une image de telle sorte que l'image compressée soit la plus proche de l'image réelle. Dans l’espace des couleurs, chaque pixel RGB est approché par le code le plus similaire :

Il existe plusieurs méthodes de clustering. La plus connue est la méthode de K-Means (que l’on appelle aussi K-Moyennes ou centres mobiles).
L'algorithme K-Means cherche à regrouper les points en classes. Chaque classe est caractérisée par son centre de gravité que nous appellerons . Afin de mieux comprendre son principe, prenons l’exemple suivant :
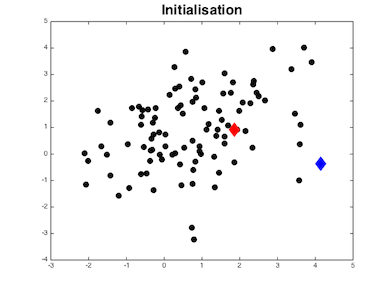
La figure représente les données (les points noirs) que nous souhaitons regrouper en deux classes. Commençons par initialiser les centres des classes : ce seront les losanges bleu et rouge, qui sont positionnés aléatoirement.
Connaissant ces centres initiaux, chaque point est affecté à la classe dont le centre est le plus proche. Ceci donne la figure suivante
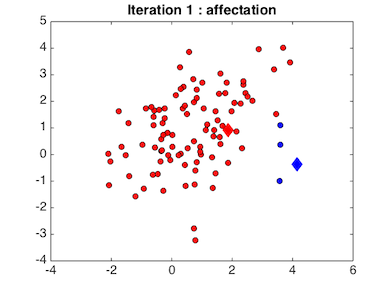
Connaissant les points associés à chaque classe, on met à jour leur centre qui est calculé comme le barycentre des points de la classe. Bien évidemment, le résultat obtenu à cette première étape ne sera pas satisfaisant puisqu'on a choisi aléatoirement les centres initiaux. On va donc ré-itérer la démarche afin d'améliorer le résultat.
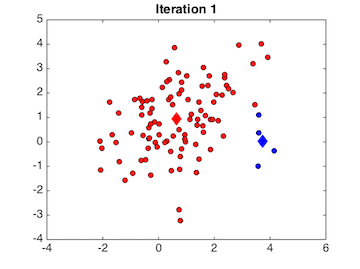
À la deuxième étape, nous modifions l'affectation des points aux deux classes en utilisant cette fois-ci les centres calculés à la première itération. Ceci donne la figure suivante, où l’on constate que d'autres points ont été intégrés à la classe bleue :
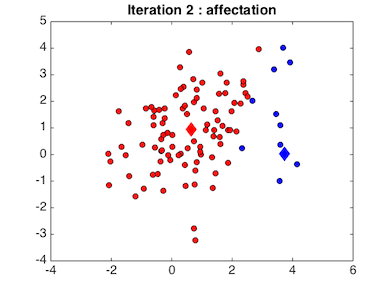
Partant de cette affectation, les nouveaux centres des clusters sont recalculés en fonction des points qui sont tombés dans les clusters :
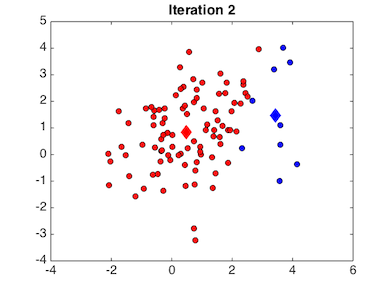
On alterne ainsi l’affectation des points aux classes et l’estimation de leurs centres jusqu’à convergence. L'animation ci-dessous illustre parfaitement notre exemple :

La convergence est atteinte quand les centres des clusters ne changent plus.
L'algorithme
L'idée de l'algorithme de K-Means est très simple et facile à mettre en œuvre. L'algorithme nécessite en entrée les données d'apprentissage et le nombre voulu de classes . Après initialisation des centres, on exécute itérativement jusqu'à convergence deux étapes :
Étape 1 : l'affectation des points aux classes :
Pour chaque point on calcule sa distance euclidienne à tous les centres ; le point sera attribué à la classe si sa distance à cette classe est la plus petite.
Étape 2 : la mise à jour du centre de chaque classe
est le nombre de points de la classe . Le centre est le barycentre des points de la classe .
On peut se demander quel problème mathématique résoud cet algorithme ?
Pour formaliser ce problème, on va associer à un point des coefficients scalaires qui vont indiquer si ce point est affecté à la classe k (auquel cas vaut 1 sinon il vaut 0) :
L'algorithme des K-Means cherche à minimiser la somme des distances des points aux centres des classes, avec la contrainte qu'un point ne peut appartenir qu'à une seule classe. Ceci donne le problème d’optimisation suivant :
Le critère va promouvoir le fait que les points d'une classe seront concentrés autour de son centre c'est-à-dire les points qui se ressemblent vont s'assembler.
À chacune des itérations, l’algorithme minimise alternativement par rapport aux coefficients (c'est l'étape 1), puis par rapport aux centres (c'est l'étape 2).
Pour l'étape 1, supposons qu'on connaît les centres ; la stratégie d'affectation d'un point quelconque à une classe peut se justifier mathématiquement. Pour cela, on ré-écrit le critère en isolant les termes qui ne dépendent que de .
Minimiser par rapport à équivaut à minimiser que le terme c'est-à-dire à résoudre
Dans l'autre sens, si on connaît les points de chaque cluster, c'est-à-dire les coefficients , et qu'on veut déterminer le centre , il suffit d'isoler tous les termes relatifs à dans
Minimiser par rapport à revient à minimiser le terme en bleu .
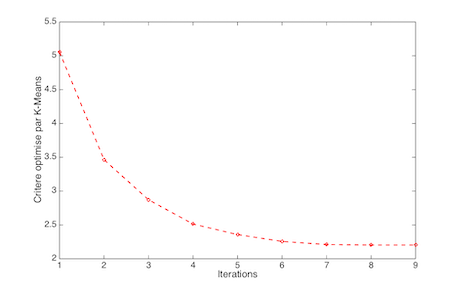
On constate que l'algorithme converge très rapidement, puisqu'au bout de 7 à 8 itérations le critère ne diminue plus.
En pratique est-ce que l'algorithme des K-Means marche ?
En pratique, cet algorithme est efficace. Néanmoins, il nécessite de faire quelques choix non-évidents. Par exemple, il faut déterminer le nombre de classes ou choisir les centres initiaux.
Prenons l’exemple ci-dessous dans lequel nous allons chercher à regrouper les points en 6 classes :
Nous allons choisir aléatoirement les centres initiaux et les représenter sous forme de carrés jaunes. Les 6 classes ainsi obtenues sont matérialisées par différentes couleurs. On trouve des formes géométriques correspondant aux lettres.
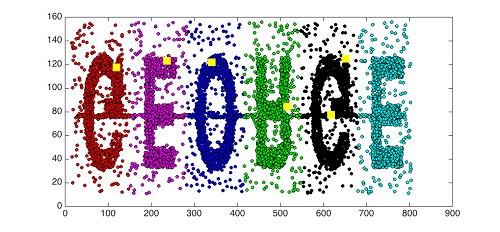
L'algorithme a été relancé en changeant l'initialisation :
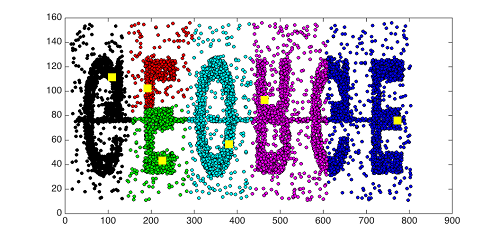
Comment choisir le nombre de classes ?
Le choix du nombre de classes est un problème difficile, car le clustering est un problème d’apprentissage non-supervisé.
Il n’existe donc pas de vérité terrain nous permettant d’évaluer la pertinence des classes trouvées. On peut être guidé par l'application (exemple : on veut segmenter les utilisateurs de Velib' en K catégories), on peut tester différentes valeurs de et retenir la meilleure solution. Retenez néanmoins qu’évaluer le résultat d'un clustering est subjectif.
Par exemple, les personnages sur cette image

peuvent être regroupés ainsi :

Source : Les Simpsons, d'après l'oeuvre de Matt Groening.
En résumé
Le clustering est une approche d’exploration statistique qui vise à déterminer les similarités entre les points en les regroupant en classes ou groupes homogènes.
L’algorithme des K-Means, qui permet de résoudre ce type de problèmes, a la particularité d’être conceptuellement simple et rapide à mettre en œuvre. Il est basé sur la minimisation de la distance des points d’apprentissage aux centres des classes. Pour juger de son résultat, il faut préférer des classes homogènes et distinctes.
Il existe des critères ad-hoc permettant d’évaluer la méthode du clustering.
Le résultat peut changer avec l’initialisation et son évaluation reste subjective.
Après ce chapitre consacré à l'apprentissage non-supervisé, vous abordez dans le cours suivant votre premier problème d'apprentissage supervisé, la régression linéaire.
