Appréhendez la régression linéaire
L'objectif de ce chapitre est de :
comprendre la régression linéaire,
savoir expliquer le résultat de la régression linéaire,
déterminer les variables explicatives les plus pertinentes.
Il fait beau, mes vélos seront-ils loués ?
Prenons les données quotidiennes de location de vélos dans une ville américaine (un extrait est sur la figure ci-dessous). Elles peuvent être téléchargées ici.
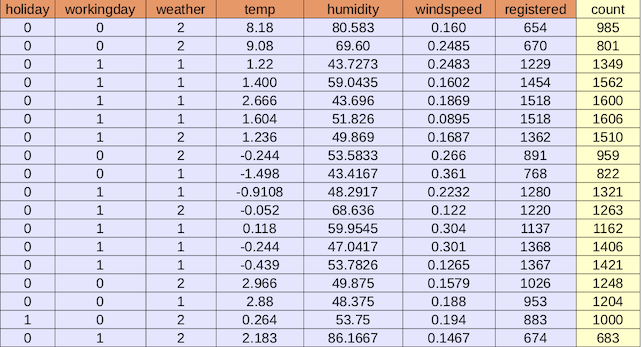
L'objectif est de prédire le nombre de locations (la colonne count) en utilisant les autres variables. La signification des variables est présentée dans le tableau 2.
Variable | holiday | workingday | weather | temp | humidity | windspeed | registered | count |
Signification | jour férié | jour ouvré | météo | température | humidité | vitesse du vent | nombre d'abonnés | nombre de locations |
Nature | binaire | binaire | catégorielle | continue | continue | continue | continue | continue |
Tableau 2 : signification et nature des variables
Comme dans le cours sur l'ACP, nous allons noter la matrice des données sans la colonne count. est le nombre de données et le nombre de variables.
Définissez un modèle de régression linéaire
Régression mono-variable
Prédisons les locations de vélos en fonction de la température :
représente l'écart entre la prédiction et la vraie valeur comme le montre la figure 1.
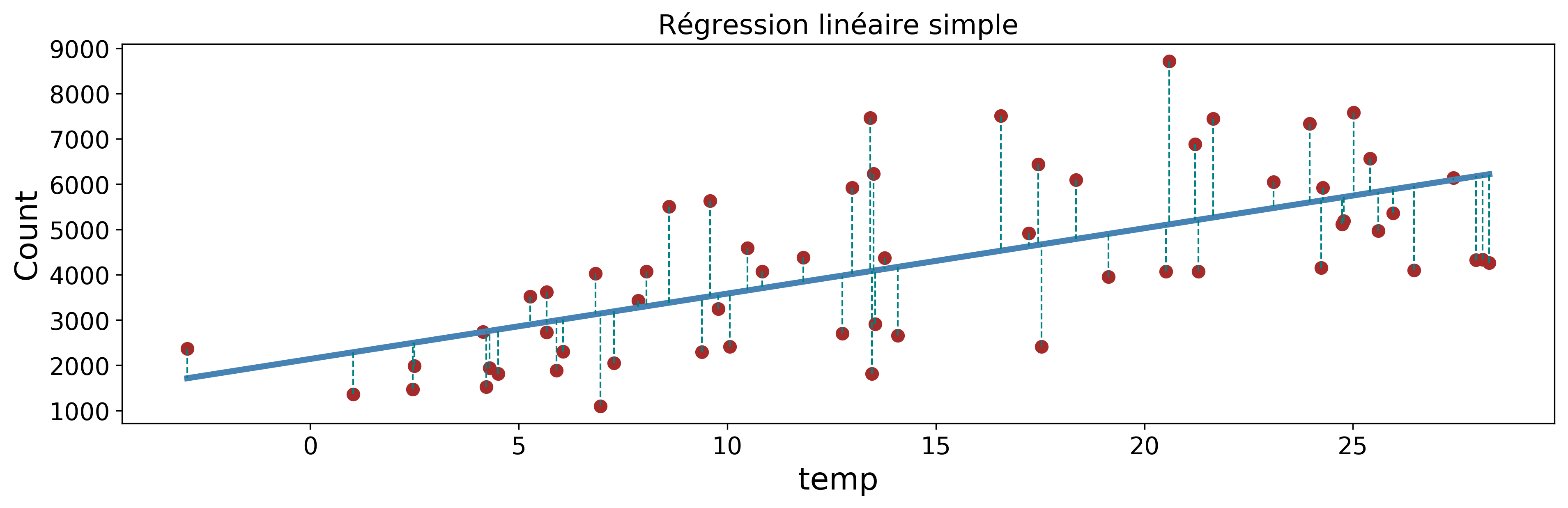
Les paramètres et sont déterminés de façon à minimiser ces erreurs.
Régression multiple
Pour la suite, utilisons la terminologie suivante :
count : sortie ou variable à prédire notée ,
holiday, ..., temp, ..., registered (nombre d'abonnés) : entrées ou variables prédictives. Notons le vecteur contenant ces variables.
Le modèle de régression est maintenant
avec l'ordonnée à l'origine et le vecteur de paramètres associé aux entrées.
Comment déterminer les paramètres du modèle ?
Par minimisation du critère des moindres carrés :
avec les définitions suivantes :
est le vecteur des sorties, est un vecteur de 1 et
est la matrice contenant les variables prédictives.
Comment juger de la qualité du modèle ?
Comparez visuellement les prédictions et les vraies observations (figure 2).
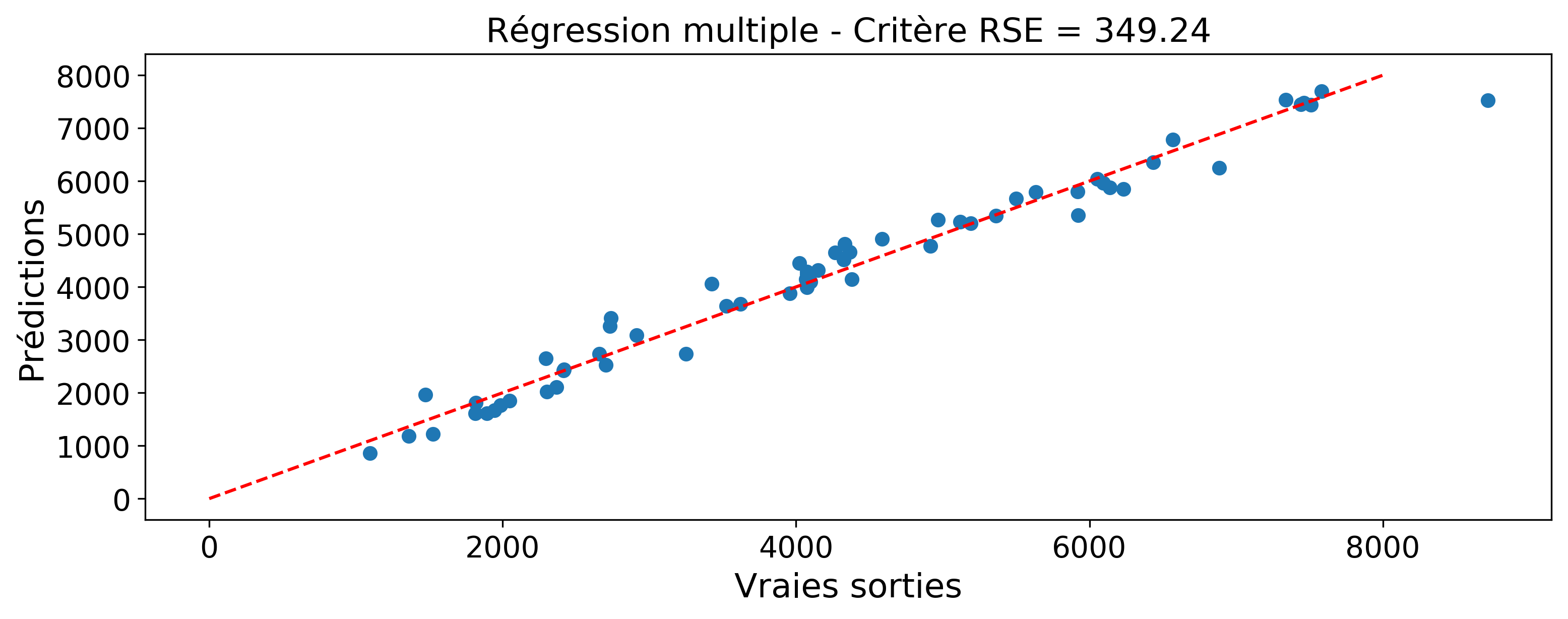
Évaluez l'erreur de prédiction :
Plus ce critère est petit, mieux c'est.
Sélectionnez les variables explicatives
A-t-on besoin de toutes les variables holiday, ..., temp, ..., registered ?
Pour sélectionner les variables pertinentes parmi les disponibles, plusieurs stratégies sont possibles :
Meilleur sous-ensemble : il faut tester tous les modèles linéaires possibles à 1 variable, puis 2 variables et ainsi de suite. Cela nécessite d'explorer possibilités. Cette méthode a une complexité exponentielle par rapport au nombre de variables .
Forward Selection : on inclue une à une les variables dans le modèle, soit possibilités.
Backward Selection : partant d'un modèle incluant toutes les variables, on retire à chaque étape une variable, soit aussi possibilités.
Pénaliser les paramètres : deux variantes sont la régression ridge et le lasso.
Régression linéaire pénalisée
Elle consiste à déterminer les paramètres par minimisation du critère des moindres carrés régularisé :
est le paramètre de régularisation (à choisir par l'utilisateur) et est le terme de régularisation.
L'idée ici est de pousser certains paramètres (ceux qui sont associés aux variables explicatives qui ne sont pas essentielles pour décrire la sortie ) en jouant sur la valeur de et la forme de . À l'extrême, lorsque :
on souhaite avoir c'est-à-dire (aucune variable n'est sélectionnée) ;
nous retrouvons la solution (2) de la régression linéaire (toutes les variables explicatives sont incluses dans le modèle).
Les choix appropriés de et permettront de déterminer un compromis entre ces deux situations extrêmes.
On remarquera que le paramètre (la coordonnée à l'origine) n'est pas pénalisée.
Influence de la régularisation
Pour mieux comprendre comment ces méthodes de régularisation agissent, considérons cet exemple simple. Supposons qu'on dispose d'une seule observation et qu'on cherche le modèle avec . Les deux fonctions de régularisation sont représentées sur la figure 3.
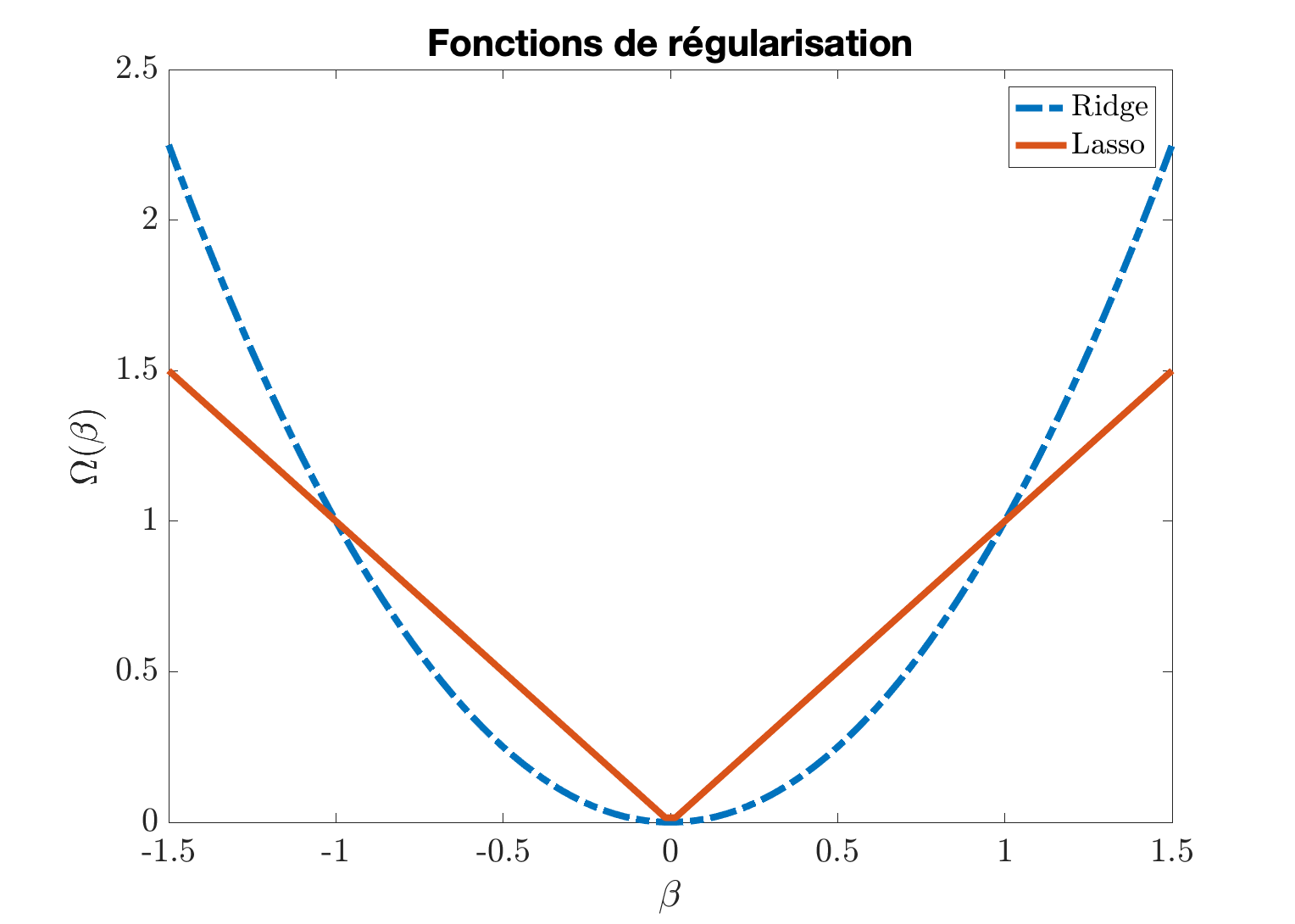
Pour la régression ridge, nous avons à résoudre
La condition d'optimalité (annulation du gradient) fournit la solution
Nous constatons que si .
Le problème du lasso s'écrit
La difficulté du lasso est la non-dérivabilité de la fonction en 0 (voir figure 3). Néanmoins on a :
pour la dérivée est ,
pour la dérivée est .
La condition d'optimalité s'écrit alors :
si on a ,
si on a et .
Nous en déduisons pour le problème (4) une solution analytique sous la forme :
La figure 4 montre l'influence des deux formes de régularisation.
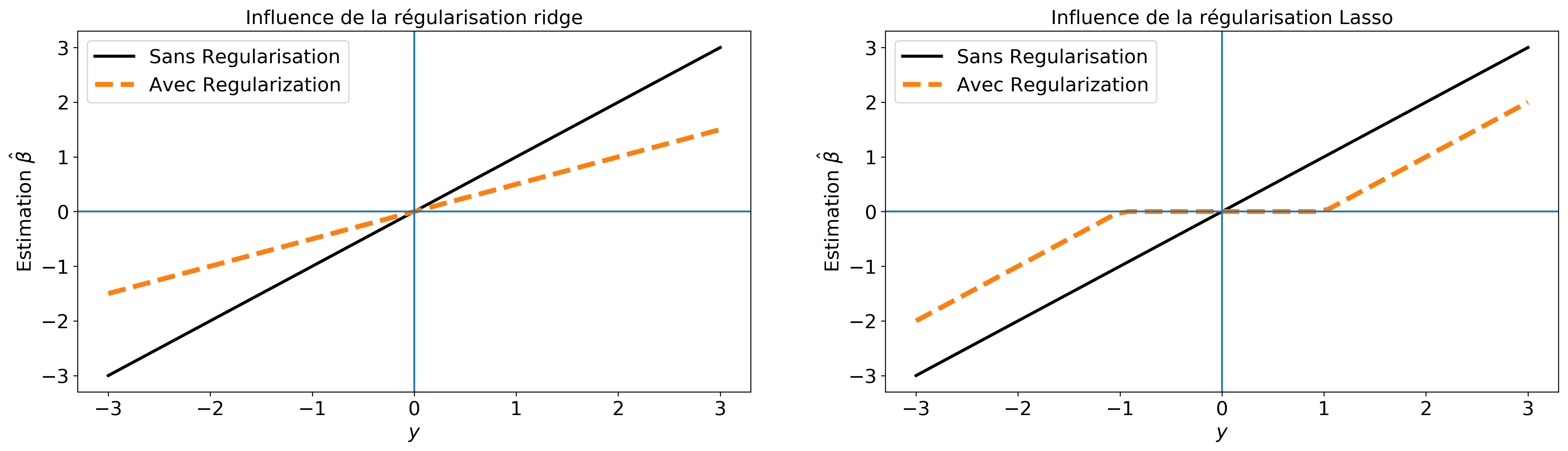
Solution de la régression linéaire pénalisée
Revenons maintenant à notre problème général (équation 3).
On peut montrer que le problème de régression ridge admet une solution analytique. En effet, si nous écrivons la condition d'optimalité respectivement par rapport à et nous obtenons
avec la moyenne des sorties, la moyenne des variables explicatives, la matrice des données centrées, le vecteur des sorties centrées et la matrice identité. L'expression de cette solution est presque similaire à celle de la régression linéaire (voir équation 2) au terme près.
Pour la régression lasso, la solution est la même que celle de la régression ridge. En revanche, n'admet pas de solution analytique et se détermine via des algorithmes d'optimisation itératifs. Un exemple d'algorithme de résolution du problème lasso est le suivant :
Initialisation
Répétez
Jusqu'à convergence
Calculez
Le principe est qu'à chaque itération, on fixe tous les paramètres sauf un, dont on optimise la valeur en résolvant un problème de lasso simplifié comme à l'équation (4). Sa solution s'obtient par une opération de seuillage doux. Cette procédure est répétée jusqu'à la convergence des paramètres .
Notez qu'il existe des boîtes à outils comme sklearn ou CVX qui implémentent la solution de la régression lasso.
Réglage du paramètre de régularisation
Comment sélectionner le bon paramètre de régularisation ?
Les figures 5 et 6 montrent l'effet de la régularisation en fonction de .
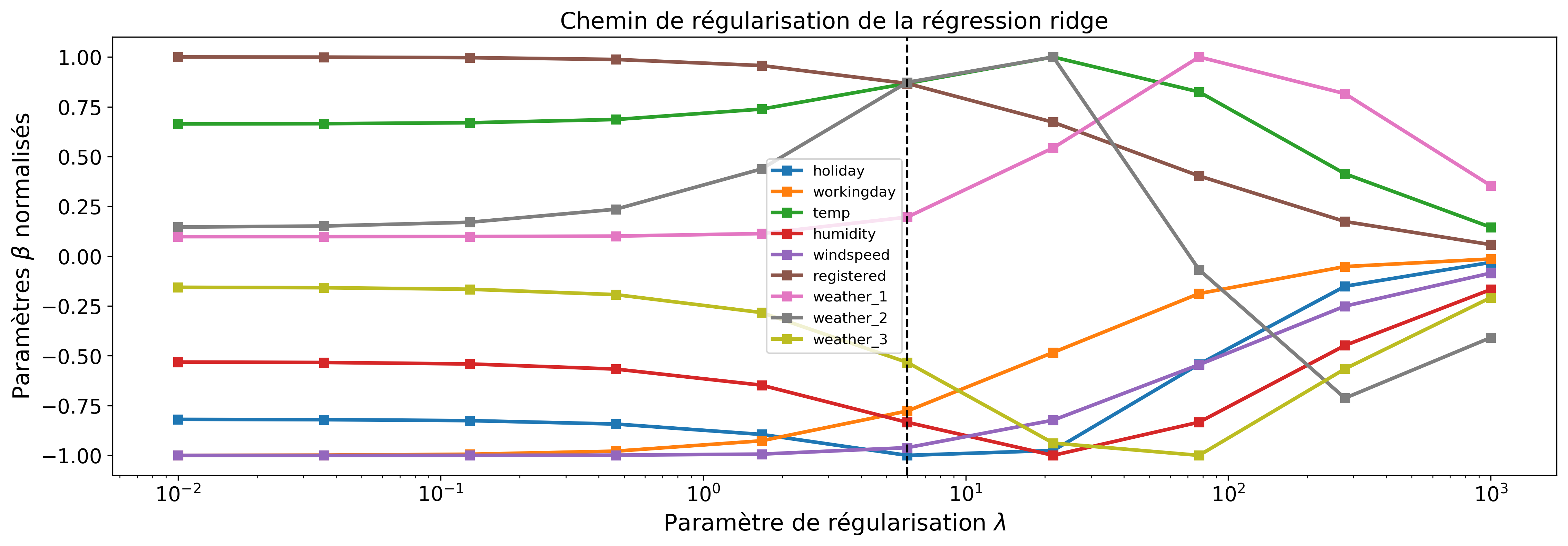
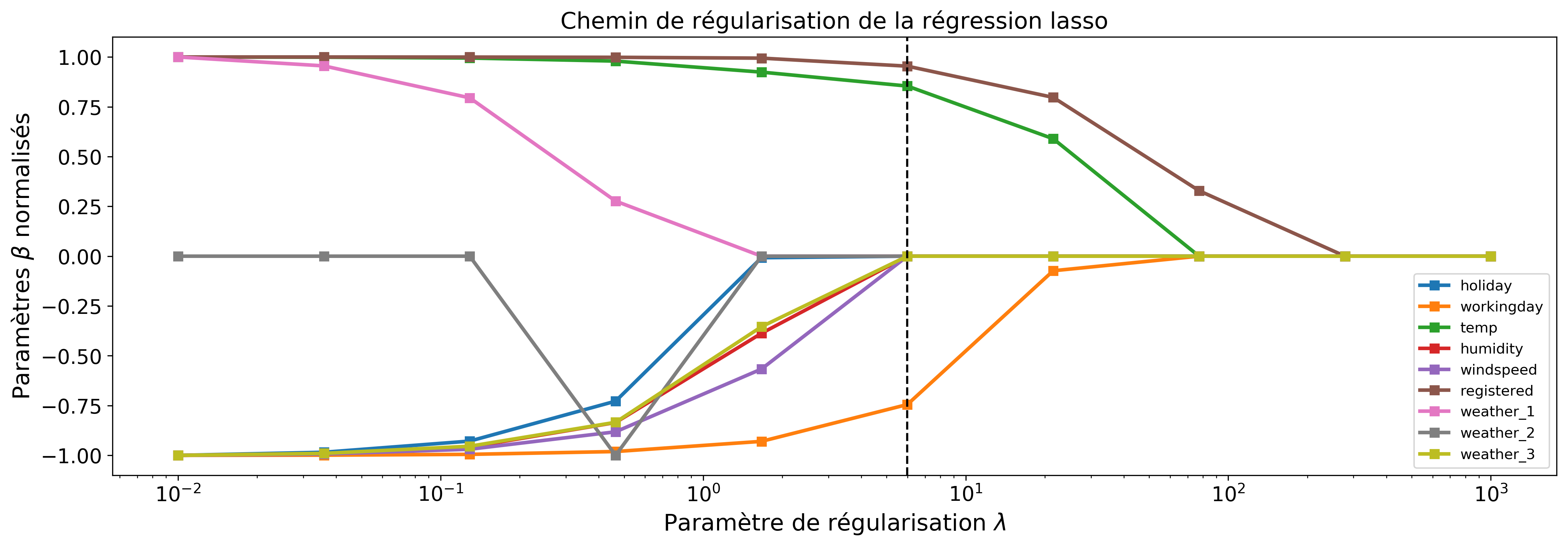
En pratique, on teste différentes valeurs de (souvent prises sur une échelle logarithmique) et on évalue à chaque fois le modèle obtenu. Nous pouvons nous servir du critère RSE calculé sur les données de validation (toujours cette notion de généralisation du modèle) pour sélectionner alors le "optimal". Le graphique de la figure 7 montre la courbe de validation pour le lasso.
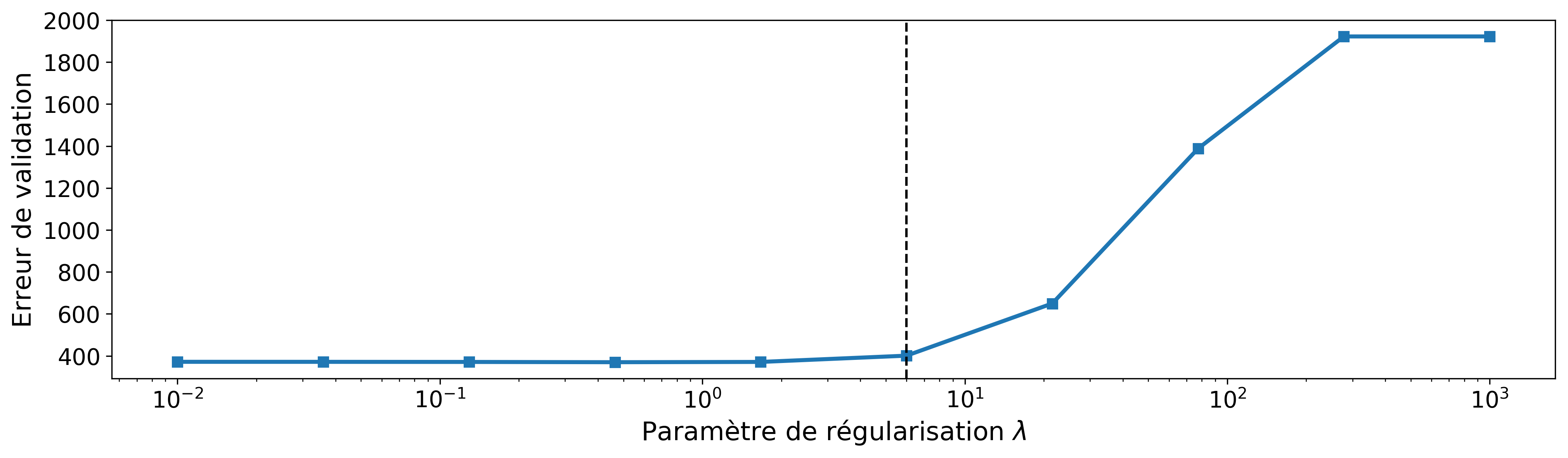
En se reportant au graphique du chemin de régularisation, nous constatons que pour la valeur de retenue, seules les variables "workingday", "temp" et "registered" sont sélectionnées. (Ceci signifie que les locations journalières de vélos peuvent s'expliquer par la température, le nombre d'abonnés au service de location et au fait que la journée soit ouvrée ou non.)
En résumé
Dans ce chapitre, vous avez appris :
comment construire un modèle de régression linéaire,
comment qualifier ses performances,
comment sélectionner les variables pertinentes en utilisant notamment le lasso.
Dans le prochain chapitre, nous verrons comment passer de la régression linéaire à la régression logistique.
