Solve Problems Faster Using Lambdas and Parallelized Streams
You saw parallel processing in the previous chapter, and now you're ready to code with Java concurrency's Stream API. The Stream API is a straightforward way of doing concurrent code, and one you'll often see in the workplace.
Awesome...but what's a stream? 😅
A stream is continuous, ordered flow of information. Think of it as a stream of data.
How is a stream different from sequential data? 🤔
A stream comes with built-in mechanisms or operations that you can use to transform your data. With the Stream API, these operations are specially constructed to filter, map, and reduce data without you having to write extra code. All you need to do is indicate when to use them and where allowing you to process any amount of data efficiently. Additionally, instead of sticking with a finite amount of data, streams can continuously pull and add more at the source during processing. With the Stream API, you can even add ways of manipulating your data in any order you want. Overall, this provides a much more adaptable way of working with data in concurrent programming.
Let's look at how to use streams before learning how to speed them up!
Using Lambdas as Units of Parallel Execution
In addition to providing the Stream API, Java also supports transforming streams by using class-less methods called lambdas. Lambdas allow you to state or declare what values go into them and how to compute the values that come out.
You can pass a lambada value to another lambada, which is called a higher-order function. These methods can also be referred to as pure anonymous functions as they don't need to belong to a class explicitly. They can be defined inline by the caller before kicking off a concurrent operation, which makes your life easier. You pass a function you've just created to a Java API responsible for running it concurrently. 😎
Since you will use Java's lambdas extensively when writing concurrent code, let's recap what makes them so awesome!
Lambdas make code terser and easier to follow, by removing the boilerplate of having to write a new class with methods. A lambda is an inline class with one method, created using a straightforward declaration of the form:
(parameterGoingIn -> parameterGoingIn+1)On the left, you can see an input argument,
parameterGoingIn; I do not need to specify its type as it is implicitly defined. This can be any argument, or even several arguments, which you'd represent as a comma-separated list in brackets. Eg.,(arg1, arg2, arg3) -> ...In the middle, the arrow operator,->, declares a mapping from arguments (left) to a transformation (right).
On the right, parameterGoingIn+1 represents something you do to the input value, to get an output value. It is a standard Java statement. If you enclosed this in a {block} with a return statement, you could even have several lines of code in there. For example:
(year, month, day) -> {
int luckyNumber = year + month;
return luckyNumber + day;
};If it wasn't for lambdas, that would be a new class with a method.
So how can I execute a lambda then?
Any Java interface with a single unimplemented method can be implemented or replaced with a lambda. You could implement the following interface with a lambda containing one method, called doSomething(Double someValue).
@FunctionalInterface
interface ExampleDoubleFunction {
Double doSomething(Double someValue);
}Line 1: The @Functionalnterface annotation ensures this interface only ever has one abstract method at compile time. That way, no one can accidentally break an interface intended to be implemented using lambdas.
Line 2 defines an interface as usual.
Line 3 defines a method that receives a double and returns a double. The signature of the method (its return type and arguments) can be set to anything you like. All that is required to implement this abstract method with a lambda is that the interface only declares one method.
This means you can implement an ExampleDoubleFunction using a lambda. Do this like so:
ExampleDoubleFunction anonymousFunction = (inputValue -> inputValue+1)It creates a variable of type ExampleDoubleFunction and assigns it with an object which overrides its single method with the lambda expression (inputValue -> inputValue+1). This expression takes the argument inputValue and returns the result of adding one to it.
To use this, call the doSomething method on the anonymousFunction. Here's how you'd add one to 2.1:
Double result = anonymousFunction.doSomething(2.1); // This should be solved by our lambdaSo, are lambdas actually functions?
Your safest bet when working with Java is to call them lambdas or functions, as the JDK has unique function interfaces to help you represent your lambdas.
Using Lambdas to Process Streams
Now you're ready to use streams. Since concurrency can come with surprises and lack of predictability, a good approach to take when processing parallel streams is:
First, get your stream and its lambda operations working in serial.
When you're confident, then test your lambdas with a parallel stream.
This means you should start with sequential streams before moving on to parallel ones - which we'll do!
Show me! How do I do use lambdas with a stream?
The processing of a stream consists of several steps:
First, construct a stream.
There are various methods for this. One of the simplest is by calling the.stream()method on an existing collection, such as a list. In the previous chapter, we used Java's Files API to return a stream of all rows in a file, by calling Files.lines().Next, invoke intermediate operations.
These are steps you go through using lambdas and parts of the Stream API to filter, transform, and manipulate items in your stream.Finally, invoke a terminal operation.
This method takes the output from your stream (or streams) and reduces them into a single result or behavior. There are several types of terminal operations you can read about in more detail, but we'll focus oncollect().
Let's look at a simple stream that opens a file with a single column of planet masses and calculates an average from it:
double averageEarthMasses =
Stream.of("1.2","1.3", "1.5").
filter(row -> ! row.equals("")).
map(Double::parseDouble).
collect(Collectors.averagingDouble(n->n))
Line 2: Using Stream.of, create a stream with three real numbers as strings.
Line 3: An intermediate operation using the Stream.filter() method of the Stream API to return all non-empty rows; that is, those where
!row.equals("")is true.Line 4: An intermediate operation using the map method of the Stream API to convert a value to a double. As we're using an existing method rather than writing a lambda, pass it a symbol to the static method, Double.parseDouble, from Java's double class. To pass it in place of lambda, reference the class as usual, but place a "::" symbol before the method name.
Line 5: A terminal operation using Stream.collect to reduce the stream of doubles into a result. Use the java.util.streams.Collectors class to reduce the result with its
averagingDouble()method, which takes a lambda.
Pass it a lambda, which returns the argument given to it. This particular lambda, (n->n), is also known as an identity function since it returns the argument given to it.
How can I decide whether to write a big lambda or break it into more steps?
Following the single responsibility principle, it's better to have many functions, where each does one thing clearly than it is to have one function, which does many things confusingly. For instance, we could have removed the map in Line 4 and incorporated it into the collect() function.
If your steps are starting to look or feel confusing, consider breaking them up. Software engineering, in practice, is as much an art as it is a science.
Let's run this code in Java's REPL, JShell, which you'll find with the JDK distribution.
| Welcome to JShell -- Version 11.0.3
| For an introduction type: /help intro
jshell> import java.util.stream.Collectors
jshell> List<String> masses = List.of("1.2", "1.3", "1.5");
jshell> double averageEarthMasses = masses.stream().filter(row -> ! row.equals("")).map(Double::parseDouble).collect(Collectors.averagingDouble(n->n))
averageEarthMasses ==> 1.3333333333333333
As you can see in Line 8, it works! Make sure that you try it out for yourself! Once you're done, to quit JShell, simply type /exit.
You've done some great work on a simplified example of the temperature averaging program. Let's go back to the original and see how easy it is to parallelize the stream!
Scaling Up Your Code by Parallelizing Streams
By default, streams are serial, meaning that each stage of a process is executed one after the other, one piece of data at a time. However, they are designed to be easily parallelizable.
Now, how does the Stream API parallel process? There are three main steps:
Step 1: Create a Stream

There are two operators you can use for this:
Collection.parallelStream()
If you are creating a stream from a collection such as a list, you can useparallelStream()(rather thanstream()) to publish a stream of the items in that collection. This method will attempt to parallelize the pipeline that follows it if possible.
Stream.parallel()
If you already have a stream and wish to parallelize it, you can call.parallel()on the stream to ensure that subsequent processing occurs in parallel.
Step 2: Process Intermediate Operations
Remember specially constructed operations that filter, map, and reduce data, all without having to write a bunch of extra code from the beginning of the chapter? That's what intermediate operations are - steps with custom logic. You tell the Stream API when and where to put them.
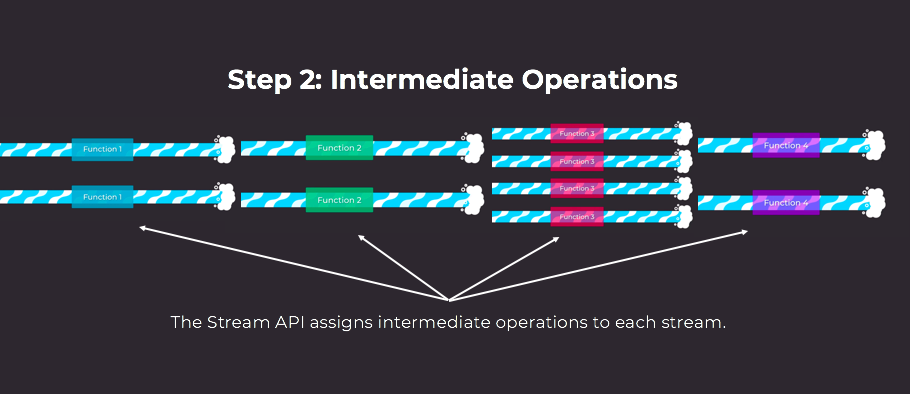
The Stream API takes care of making sure that each concurrent stream is given all the lambdas and functions representing the steps of the intermediate operations.
Step 3: Check the Terminal Operation
A terminal operation is a final operation that's responsible for producing a single result or behavior.
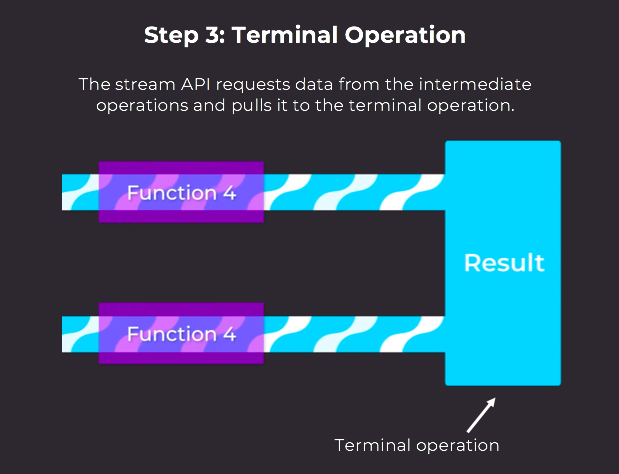
As long there are still data items in the stream to be pulled by your terminal operation, the Stream API will continue to coordinate requesting these from intermediate operations.
Parallelizing Our Mean Planet Temperature Analyzer: Practice!
Are you ready to see how to modify our meanTemperature example? First, let's try parallelizing a stream in JShell.
See if you can parallelize the last JShell example by adding eight characters:
Start JShell.
Copy the import and example we previously tried in JShell.
Now make it parallel!
Did you manage? The change is from stream() to parallelStream()
It should now be:
jshell> List<String> masses = List.of("1.2", "1.3", "1.5");
jshell> double averageEarthMasses = masses.parallelStream().filter(row -> ! row.equals("")).map(Double::parseDouble).collect(Collectors.averagingDouble(n->n))
averageEarthMasses ==> 1.3333333333333333You can also add parallel() to the point after you've created your stream. Let's do this together!
Modifying Our Planet Temperature Application
Let's update our previous ProcessBuilder implementation adding .parallel() to the stream.
That's it. Nothing else! This is what the code now looks like:
Double meanTemperature = Files.lines(path).
// Parallelise!
parallel().
// Ignore comments in the CSV
filter(line ->
! line.startsWith(KeplerCsvFields.COMMENT_CHARACTER)).
// Skip the header which is left after our comments
skip(1).
// Separate the columns using a comma
map(line -> line.split(",")).
filter(row -> row.length >= 3).
// Extract the planet's temperature in Kelvin
map(row -> row[KeplerCsvFields.EQUILIBRIUM_TEMPERATURE_COLUMN]).
// Convert the value to a double
map(temperatureStringValue -> Double.parseDouble(temperatureStringValue)).
// Filter against an upper bound
filter(kelvinTemperature -> kelvinTemperature <= maxTemperature).
// Update the average with a mutable reduction (calculate a running average)
collect(
Collectors.averagingDouble(num->num));Line 1: Read the file and publish a stream containing each line of the file. Then call
parallel()on it, to allow the subsequent steps to occur in parallel.
Line 5: Filter is a method from the Stream API which consumes, or receives, each line and uses a lambda to only pass through those lines that don't start with the
COMMENT_CHARACTER. That is, it publishes a stream with the comments removed.Line 8: Skips one row. Based on the layout of the file and comment, it is clear this is intended to skip a row in the file that contains headers, rather than values.
Line 10: Transforms every line, using the map operator of the Stream API, into an array by applying the string: split operator on it. This turns a row such as K00755.01, Kepler-664 b,1406.0 into a string array with each of those values.
Line 11: Removes all rows which do not have three columns by inspecting the length of each array created in the previous step.
Line 13: Throws away the row and only passes on the column with the planet's temperature value in Kelvin.
Line 15: Applies
map()on every temperature value converting it from a string to a double. We are now ready to use that double value towards calculating our average.Line 17: Eliminates any planets which are hotter than our provided cut-off,
maxTemperature.Line 20: This completion operation keeps a running average using a mutable collector and returns it when there is no more data.
Measures the performance.
Let's modify the benchmark so it also measures parallel streams. Simply add a new @Benchmark annotated method to the existing class. Follow along!
Let's break this down!
First, we added a new method to BenchmarkRunner called
benchmarkParallelStream().We then looked at the main class for our parallel stream implementation. This accepted an array with a file name.
We then called that main method from our benchmarked method, passing in the file with lots of planets.
Finally, we ran the benchmark by calling the runBenchmarks task.
Did you notice how the parallelStream implementation is 33+ times more performant than the parallelized implementation using ProcessBuilder? 💪
Here's the output from the benchmark. Compare the Score columns to get a feel for the differences in performance:
Benchmark Mode Cnt Score Error Units
BenchmarkRunner.benchmarkMultiProcess thrpt 25 0.979 ± 0.033 ops/s
BenchmarkRunner.benchmarkParallelStream thrpt 25 33.338 ± 1.045 ops/s
BenchmarkRunner.benchmarkSingleProcess thrpt 25 7.671 ± 0.401 ops/sParallelStreams execute concurrently, without the additional overhead of starting a new JVM each time. You've seen how easy it is to get a considerable performance improvement.
Running the Benchmark!
Clone the repository and look at the code. Try running the benchmark yourself.
git clone https://github.com/OpenClassrooms-Student-Center/ScaleUpYourCodeWithJavaConcurrencyA.git git checkout p1-c2-parallelstreams
Or use your IDE to clone the repository and check out the branch p1-c2-parallelstreams. You can now explore the implementation of our parallel stream and try running the tests with:
./gradlew runBenchmarks
Why do I see different benchmark results?
Don't worry. This is normal. Remember that the non-determinism of concurrency and parallelism means that you will get completely different results to the ones from the screencast.
Let's Recap!
Java's Stream API allows you to process a stream of data using intermediate operations and a terminal operation.
The operations on a stream can be implemented as lambda functions.
You can turn a serial stream into a parallel one by calling
.parallel()on it.You can retrieve a stream from a collection type by calling
.parallelStream()on it.
In the next chapter, we'll use Runnables and Callables to improve our program!
