Implement a Producer-Consumer Pattern Using a BlockingQueue
In all of the concurrency examples, you've seen how we deconstructed problems by farming out tasks to multiple workers to produce intermediary results. The code would then consume these intermediary results and then recombine them in some way.
You see this all the time in the real world. A farmer working on a coffee plantation, who is hopefully fairly rewarded, produces coffee to sell to a local exporter. The exporter consumes many plantations' coffee, providing it with enough to produce deliveries for overseas consumers. Those consumers are importers and coffee roasters, who, in turn, produce the packaged shipments for your local coffee shop. Finally, you are the consumer at the end of this long chain of production and consumption.
This pattern is used all the time in concurrent code. As engineers, it's referred to it as the producer-consumer pattern.
Understanding the Producer-Consumer Pattern
Let's break down the producer-consumer pattern and understand its intent, value, and how to implement it.
In the producer-consumer pattern, each stage in the process is identified as either consuming or producing data. Each bit of code is written to handle one stage in a pipeline of steps. It generally follows this pattern:
Create a communication channel for a producer to talk to a consumer. Queues are often used, which I'll tell you more about soon. 😉
Create a producer that does some work and keeps sends its resulting data through that communication channel.
Create a consumer that keeps reading from that communication channel and processes any data passed to it.
Why should I use the consumer-producer pattern?
The benefits of separating your consumers from your producers (decoupling these two responsibilities) are:
You can tweak either of these (consumers or producers) independently to cope of with unexpected changes in data volume or the speed of earlier steps in data processing.
Your code becomes more modular.
What happens if I don't do that?
It's easy to build applications that do to much in one place. They'll work for years - until suddenly the business grows. At that point, you can often find that the performance of the application can't keep up with the amount of data it has to process creating multiple consequences, including:
Applications suffering from unacceptably low completion times..
Unexpected memory growth.
Errors such as time outs.
What happens if the application crashes? You often have to rerun the whole thing. How do you make it faster? You have to refactor the whole application!
By starting with code that is well-separated and only passes data from independent consumers to producers, you can easily modify the numbers of producers and consumers in your system. If your consuming threads are overwhelmed by the output of producing threads, you can add more consumers to help in processing that data.
We call this horizontally scaling an application. It's a lot cheaper and predictable than trying to make your consumer faster, often by adding more hardware. That's called vertical scaling.
Structuring the Producer-Consumer Pattern in Your Application
To benefit most from producers and consumers, you need to design your application so that the producers and consumers don't need to coordinate (are independent) to produce their output continuously. To achieve this, implement a queue between a producer and a consumer or some other data structure. Let's check out each of these - queue, producer, and consumer- in more detail.
Queue
A queue is really similar to waiting in line at the grocery store:
You line up the data which is ready to be consumed in a queue (like people lining up at the check-out).
The data at the front of the queue gets consumed first (like the first person in line is served first).
This is why a queue is called a FIFO (first-in-first-out) data structure. Having a queue allows producers and consumers to work at their own pace; specifically, it lets a consumer fetch its own work when it's ready to do so.
Queues are responsible for providing data from producers to consumers and hold onto any data put onto it until consumed. Consumers remove the oldest piece of data from the head of the queue. Producers can put new data onto the tail (or back) of the queue, as long it still has space. Queues may be of a fixed-sized (bounded queue) or of infinite size (unbounded queue).
Producer
Producers are responsible for producing some output that may be placed onto the head of a queue. Others consume this output (spoiler: consumers consume it!). A producer doesn't need to know or care about its consumers. But if there is no space in the queue, it won't be able to share what it has produced.
Consumer
Consumers, well, consume data from queues to complete a task. If consumers cannot remove data from a queue fast enough, the queue might fill up. This causes producers to fail. You don't want your queue filling up, and we'll explore unique interfaces to ensure that doesn't happen.
I've understood the component parts, but how do I apply this to a program? How do I structure my work?
When implementing the consumer pattern in your code, you have to recognize the group of behaviors responsible for consuming data and also call out what it is they are consuming. By doing this, you know which modules you'll have to create.
Imagine that we were building inventory systems to track the end to end orders of coffee from farm to hipster. 😎 Let's walk backward through this process:
Hipsters consume coffee cups produced by the coffee houses.
Coffee exporters produce coffee crates, which are consumed by fine roasted coffee houses.
Farmers produced coffee beans from plants that are consumed by exporters.
Now, if you reverse-engineer this, you get something like the diagram below:
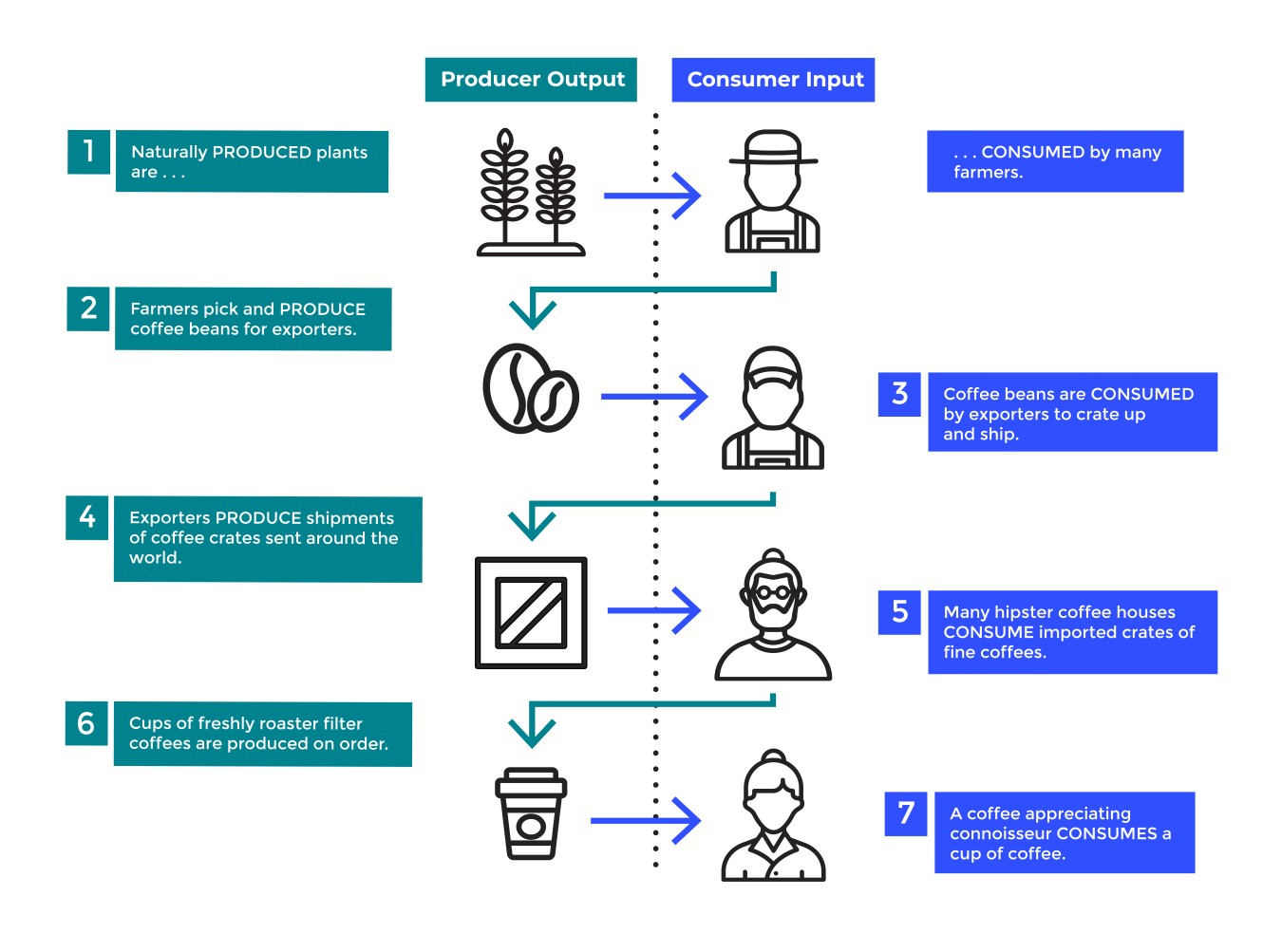
As you can see in the diagram above, you may have one or more instances for any worker dealing with these concerns. For example, if you were coding this, you might create multiple instances of some CoffeeBeanProducer class (the coffee farmers), which can then concurrently produce sufficient input so that a CoffeeBeanConsumer (the Coffee Exporter) meet the needs of its CoffeeExportProducer.
Should I always have the same number of producers as consumers?
There's no need to have the same number of each. Remember that consumers and producers do different things, so they both take different amounts of time to process the data passed to them. You need enough consumers to keep up with the output from your producers.
A consumer can only handle so much, and so a coffee shop only ever buys as many beans as it requires. Importers only import as many beans as they can sell. Coffee producers only use as much land as it's financially and practically viable for them to do. In a way, your coffee drinking habits affect the whole coffee chain. It's called backpressure. By using queues between each consumer and producer, each producer and consumer can operate at its own pace until your queues can no longer receive any more data.
Now that you've got the idea, let's dive into how you can implement a producer-concept using a Queue in Java.
Working With Unbounded Queues
Queues convey data from your producer to your consumer. Java's concurrency framework provides you with the implementations of two interfaces:
Queue
BlockingQueue
Queue implementations are not guaranteed to work concurrently. BlockingQueue, on the other hand, requires its implementations to be thread-safe and provides blocking methods that support this.
Therefore, we'll be using LinkedBlockingQueue, which implements both Queue and BlockingQueue. It allows you to create both bounded and unbounded queues. The core methods you need to be aware of from a LinkedBlockingQueue<T> are:
Method. | Behavior | Example |
| This Queue method adds an object of type T to the tail of the queue. This is synchronous and not thread-safe. | |
| This Queue method removes an object from the head of the queue. This is synchronous and not thread-safe. |
|
| Returns the current size, or depth, of the queue. |
|
| This BlockingQueue method puts an object of type T onto tail of the queue. It is guaranteed to be thread-safe and will block the calling thread if the queue is beyond some declared limit and cannot have more data added to it. |
|
| This BlockingQueue method takes an item off the head of the queue. If the queue is empty, this will block the calling thread until a producer has added an item which can be consumed. |
|
Let's use a LinkedBlockingQueue to connect multiple producers to consumers. This implementation is guaranteed to work safely across multiple threads, but is unbounded. That is, you can add content to the queue indefinitely.
It is up to you to make sure you use a design that doesn't allow your consumers to fall behind, or else the queue will build up.
Step 1: Start up JShell:
jshell
Step 2: Create a queue:
LinkedBlockingQueue<Integer> q = new LinkedBlockingQueue<Integer>();Step 3: Now create a thread that adds data to this 999 times:
Thread producer = new Thread( ()->IntStream.range(0,999).forEach(n -> q.add(n)))Step 4: Create a thread to consume from the queue more items from the queue than are present.
Thread consumer = new Thread( () -> IntStream.range(0,1000).forEach( (n) -> System.out.println("Got " + q.remove() ) )This should consume one more item from the queue than you've added.
Step 5: Startup the producer thread:
producer.start()Step 6: Check the queue size:
q.size()You should see the value of 999 returned.
Step 7: Now start up the consumer and see what happens:
consumer.start()You should see this consume every item from the queue, and then result in a NoSuchElementException. This is because we used the non-blocking remove method.
Step 8: Repeat Steps (3) and (5) again to fill up your queue.
Step 9: This time, create a consumer that calls the blocking take() and see how well it copes with getting called as many times.
Thread consumer = new Thread(
() -> IntStream.range(0,1000).forEach((value) -> {
try {
System.out.println( "Calling take() on queue.");
int item = q.take();
System.out.println("Got back " + item);
} catch (InterruptedException e) {
}
}));Line 3 to Line 7: Wrap the
q.take()call in a try-catch for a checked InterruptedException.Line 5: Call q.take() to consume from the queue. If the queue is empty, this will block until there is something for the consumer thread to fetch back.
Step 10: Try this out and call consumer.start(). This prints out many items.
Step 11: Call consumer.getState() and you should see that the thread is still active. It's blocked on that last q.take() call.
jshell> consumer.getState()
$61 ==> WAITINGStep 12: Now add one item to the queue and check the state again:
q.add(334)You should see the consumer consume this.
Step 13: Call consumer.getState() again and see what its state is now.
You'll find that it's terminated, after blocking until you send it some more data through your queue.
jshell> consumer.getState()
$84 ==> TERMINATEDWorking With Bounded Queues
What can you do if your application's producers produce more data than your consumers can keep up with? Perhaps the producers spit out 1,000 temperature samples every second, and two consumers each consume 500 temperatures samples every second. You might want to slow down your producers so that your queues don't grow indefinitely and never exceed a queue size of 500. It allows your consumers to catch up.
The examples of temperature averaging involved at least a stage that obtained some set of fields from a previous stage. The threads consumed values and produced their own results to be used in calculating an average. What happens if you suddenly have to process ten times as much data? Let's see how you can get your threads to say, "hold on, I'm bloated," and push back.
If you don't, they might not process your data fast enough and consume memory to store all of that work they haven't gotten around to yet. Doing so is easy with a BlockingQueue such as LinkedBlockingQueue. You pass the maximum size of your queue to the constructor:
jshell> LinkedBlockingQueue<String> q = new LinkedBlockingQueue<String>()
q ==> []If you want to ensure that you don't overwork your threads, you can make a decision for consumers to be spared some effort by slowing your producers down now and then. Do this by setting a bound on the queue in this way. That is a maximum size it can ever get to, also known as its maximum depth.
Any attempt to add() items beyond this limit result in an IllegalStateException, as you can see in this JShell session:
jshell> LinkedBlockingQueue<String> q = new LinkedBlockingQueue<String>(1)
q ==> []
jshell> q.add("a")
$87 ==> true
jshell> q.add("b")
| Exception java.lang.IllegalStateException: Queue full
| at AbstractQueue.add (AbstractQueue.java:98)
| at (#88:1)Line 1: Set the bounding size of the queue to 1, by passing it this value in the constructor.
Line 4: Add a letter to the queue.
Line 7: Attempt to add a second item to the queue. As you can see, this gets followed by an IllegalStateException pointing out the queue is full.
Do my threads have to catch IllegalStateExceptions when adding to bounded queues?
No. When writing multithreaded applications, it is better to use put() when adding to a queue.
put() blocks until it can add an item to the queue. This adds backpressure to your queue, slowing down producers as they attempt to add new data. It's like consumers screaming, "wait! I can't keep up!" The great thing is that consumers don't have to do anything. Your queue reaching its limit does this for them.
Producers won't be able to add this data until there is space on the queue. It's a great way to allow your consumers to keep up with your producers.
Using Blocking Queues With Our Planet Analyzer Application: Practice!
I've updated our PlanetAnalyzer application to include a BlockingQueue implementation. Here are the key features:
There is now data distributed across about 70 files instead of 23.
Each file is published to a blocking
fileQueue, which is your first producer.Up to 30 consumers take a file in turn and convert it to an AveragingComponents object.
Each AveragingComponents object is put on an
averagingQueue.A single consumer runs asynchronously in a CompletableFuture, taking each generated average off the queue.
A final average keeps getting built until you exhaust a CountDownlatch. The latch ensures that you have results for each file being processed.
Let's go over this particular implementation using BlockingQueues.
As you saw, we used many of the constructs I showed you in a more complex scenario. Essentially, all the producers called put() and all the consumers called take().
The CountDownLatches were required to ensure that each producer and consumer knew when to stop. A thread could run indefinitely; however, the application needs to process a bunch of inputs and then terminate. Knowing when there is no more input at any stage is hard to determine from within the units of a concurrent application. This is why each worker (thread) kept checking to see if we had exhausted the latches of our CountDownLatch; that is - reducing it to zero.
Running the Benchmark!
Now, try running the benchmarks!
Step 1: Checkout the branch p3-c1-blocking-queues:
git checkout p3-c1-blocking-queuesStep 2: Run the runBenchmarks Gradle task:
./gradlew runBenchmarks
How did your benchmark results compare with those I generated?
Let's Recap!
The producer-consumer pattern requires a producer to make data available, a communication channel to share that data to, and a consumer to receive and use that data.
You often use queues as communication channels between producers and consumers.
Queues are first-in-first-out (FIFO) data structures that queue up messages sent by a producer to a consumer.
BlockingQueue is a Java interface with several implementations that allow you to create either bounded or unbounded queues.
BlockingQueues can be bounded, which means that they can have a maximum size.
If producers add data to a bounded queue using the put() method, their threads are forced to wait until there is space in the queue. This puts pressure on publishers to slow down so that consumers can keep up. We call this backpressure.
In the next chapter, you'll find out how to simplify sharing maps!
