Create a Recursive Solution Using Fork/Join
Recursively Averaging Planetary Temperatures
Did you notice how the CompletableFuture implementation depended on always taking the output from the last step and then calling thenCombine()? We looped through each file and repeatedly did the same thing over and over, always updating the last result. The concurrency package's fork/join framework is made for just this sort of work.
First of all, you need to understand what fork and join mean. To better understand this, imagine supervising an intern. You might both start counting your company's stock of USB sticks together. It's easier and faster if you both take a pile of USB sticks each concurrently.
When the intern leaves you to count their pile of the USB sticks, then you can count yours. It is called a fork step, as the intern and yourself separate as though you've followed two forks on the road.
Once you've both counted your stockpiles, the intern can join you again, like a winding path rejoining two forks. You meet up again and can combine your results into a single answer. We call this step join. That's just what the framework does. It lets you divvy up bits of the same task and farm them out to interns. Usually, the interns also have their own interns. That is a forked task might fork itself. It's a great way to break down a task that can be farmed out to many.
Once that work is done, the results are joined back into your thread and can be combined into a single output. Java provides a highly efficient thread pool called the ForkJoinPool that processes special types of tasks, which are not futures. The tasks are all subclasses of the java.util.concurrent.ForkJoinTask class; that provides three core methods:
compute() - This is an abstract method that you have to override. It is responsible for taking any properties you've provided in your constructor and computing a return value for them. For instance, our Planet Analyzer might receive a list of planets and return the total sum of temperatures for all planets.
fork() - This receives an instance of a ForkJoinTask that you must create. It is normal to create a task that has a constructor into which one task can farm out some of its work. It's like the interns who farm out work to their own interns. It calls compute() asynchronously in a new thread.
join() - This method blocks the calling thread until the ForkJoinTask has completed and returned a result. It is just like Future::get(), in that respect. It returns the value returned by that previously asynchronous call to compute().
Rather than extending ForkJoinTask directly, developers tend to subclass one of its abstract subclasses instead. We're going to focus on RecursiveTasks; the most common class to extend when you want to run a task that provides you with a result, as would a Callable or future.
RecursiveActions also exist as an analog to Runnables, as they don't return a result directly. Have a look at the Javadoc to learn more.
Forking to Breakdown Tasks
As you hand out work to interns and other collaborators, you're generally breaking down the amount of information or data with which you have to work. When you want new tasks to run asynchronously and calculate a result, you call fork(). When you want to recombine the work, you call join().
Imagine you had a lot of data. You might create two RecursiveTask, each of which processes 50% of that data. In turn, those tasks would create two RecursiveTasks that do the same, and so forth, continuing until you have no more data to break down, or just enough data to provide a result.
The fork() arrows show you how to deconstruct the problem into tasks that focus on more and more specific parts of your data, running asynchronously. The join() arrow demonstrates how results bubble up from the finest grained-tasks to the top-most task. This is where you come up with a final solution in the compute() method.
Updating Our Planet Analyzer to Use ForkJoinTasks: Practice!
ForkJoinTasks are not FunctionalInterfaces, so you can't easily replace them with lambdas. This makes it hard to show you how they behave in JShell. Instead, let's dive straight into modifying our planet analyzer to use RecursiveTasks.
Let's break this down!
Step 1: Create a new POJO (plain old Java class) called AveragingComponents, which contains both the sample size and the sum, as well as getters and setters.
public class AveragingComponents {
private Double sampleSize = 0.0;
private Double sampleSum = 0.0;
...
}Step 2: Create a ForkJoinTask called TemperatureSummingTask by extending a RecursiveTask of type AveragingComponents.
public class TemperatureSummingTask extends RecursiveTask<AveragingComponents> {
}
Step 3: To implement this interface, @Override the compute() method:
public class TemperatureSummingTask extends RecursiveTask<AveragingComponents> {
...
@Override
protected AveragingComponents compute() {
...
}
}Step 4: Since the class requires planets to work on, add a field and constructor to receive a list that we can fork() out to child tasks. We also need a fileAnalyzer to work out our averages, so let's create one:
public class TemperatureSummingTask extends RecursiveTask<AveragingComponents> {
private List<Path> files;
// TODO: Make this injectable (decouple)
private ThreadBasedPlanetFileAnalyzer fileAnalyzer = new ThreadBasedPlanetFileAnalyzer();
public TemperatureSummingTask(List<Path> files) {
this.files = files;
}
}Line 3: Create a files field to remember the files we're going to work with.
Line 6: Create another field to hold onto an instance of the ThreadBasedPlanetFileAnalyzer.
Line 9 to 10: Create a constructor to pass our list of files and store these in the files field.
Step 5: The bulk of the logic lives in the compute() method, so let's start building this up. We created a compute() method, which returns an instance of AveragingComponents, containing the sample size and sum of temperatures. Let's look at its main scaffold:
@Override
protected AveragingComponents compute() {
AveragingComponents averagingComponents;
// 1. Base Case
if (files.size() == 1) {
...
} else {
// 2. General Case
...
}
return averagingComponents;
}Line 3 and Line 11: Declare an AveragingComponent, within which we'll return a sum and sample size for the files provided to this particular instance. Some of that work will be farmed out to other tasks to solve.
Line 5 to 8: As in the diagram above, RecursiveTask passes-down the responsibility of creating
AveragingComponentsfrom small parts of the files list. Since each RecursiveTask needs to know if that list of files can no longer be broken down, always check to see if there is a list with nothing left to pass down. Check whether there's only one file; if so, do some work here and read a temperature.Line 6 to 10: Continue to farm out parts of the list to other RecursiveTasks until the files can't be broken down further.
Step 6: Let's implement the general case, which breaks down the list and farms out work to other tasks. The tasks revisit this block of code with the smaller lists they have to work on, in turn slicing those lists even smaller and creating new tasks.
protected AveragingComponents compute() {
AveragingComponents averagingComponents;
// 1. Base Case
if (files.size() == 1) {
...
} else {
// 2. General Case
int midPoint = files.size()/2;
TemperatureSummingTask left =
new TemperatureSummingTask(
files.subList(0, midPoint));
TemperatureSummingTask right =
new TemperatureSummingTask(
files.subList(midPoint, files.size()));
}
return averagingComponents;
}Line: 8: Calculate the
midPointof a list by dividing it by two. As we're using an integer type, this always points at an index of the list.Line 9 to 11: Create a new
TemperatureSummingTaskto sum and count temperatures for every file to the left of the list, with an index less thanmidPoint. The result is assigned into a variable calledleft.
Line 13 to 15: Repeat the process for everything to the right of the list's midPoint. This time, assign the returned task into a variable called
right.
Step 7: Combine the return values of the left and right tasks, but let them work concurrently and adding their return values.
@Override
protected AveragingComponents compute() {
// 1. Base Case
if (files.size() == 1)
...
} else {
// 2. General Case
...
TemperatureSummingTask left = ...
TemperatureSummingTask right = ...
// asynchronously work out the left side
left.fork();
// Work out the right hand side in this thread.
AveragingComponents rightResult = right.compute();
// Get back the left side when it's ready
AveragingComponents leftResult = left.join();
// Calculate our combined result
averagingComponents = new AveragingComponents(
rightResult.getSampleSize() + leftResult.getSampleSize(),
rightResult.getSampleSum() + leftResult.getSampleSum()
);
}Line 13: Calling
left.fork()kicks off a concurrent task which, after possibly creating other tasks, returns the sum of temperatures and sample size for half the files in that instance's list.Line 16: Calling
right.compute()synchronously invokes that call in the current thread, which happens to be running this code. Assign the returned totals to a new instance of AveragingComponents.Line 19: Calling
left.join()blocks until the task left has completed and returned a result.join()returns that result, which we assign into an instance of AveragingComponents.Line 22 to 26: Now
rightandleftAveragingComponents must be combined. Create a new AveragingComponents instance by adding together their sums and sample sizes.
Step 8: As you've seen, each TemperatureSummingTask creates other TemperatureSummingTasks. Since you don't want an uncontained explosion, you need to stop this at some point. Do this in the base case.
@Override
protected AveragingComponents compute() {
AveragingComponents averagingComponents;
// 1. Base Case
if (files.size() == 1) {
...
averagingComponents = fileAnalyzer.averagingComponents(files.get(0));
else {
...
}
return averagingComponents;
}All you do is call the fileAnalyzer on a single file and return its result. It gets bubbled up to another task's general case. That return value is used as either a left or right value, as you saw above. That, in turn, gets bubbled up to other tasks and combined further.
Finally, you have a single AveragingComponents instance with the sum of all sample sizes and temperatures.
Running the Benchmark!
Measure its performance:
1) Checkout the branch p2-c5-forkjoin of the repository we've been working with:
git checkout p2-c5-forkjoin
2) Run the benchmarks using the runBenchmarks Gradle task:
./gradlew runBenchmarks
How did it perform for you? It should be relatively fast.
Stealing Work With ForkJoinPools
Did you notice that the faster implementations include parallel streams, CompletableFutures, and now the ForkJoinPool? The reason for this is that they all use a ForkJoinPool under the hood by default. ForkJoinPool is designed to maximize its use of your CPUs by always running threads!
What makes ForkJoinPool so fast?
ForkJoinPool is designed to be highly efficient by minimizing the time spent blocking or not doing anything between solving parts of your problem on threads.
It was also designed to keep a thread pool constantly busy, to maximize the time spent solving a problem concurrently. It is achieved internally by using a special algorithm known as a work-stealing algorithm, which allows threads to steal from the backlog of work of another thread. Think of it as Robin Hood-like stealing, in that it is done for the greater good to help that thread out.
A ForkJoinPool lines up work for each thread in its pool. When a task is complete, a thread can jump to run the next task concurrently. If there is no next task for that thread, it can steal work, or a ForkJoinTask in this case, from the waiting list of another thread. You can see this below:
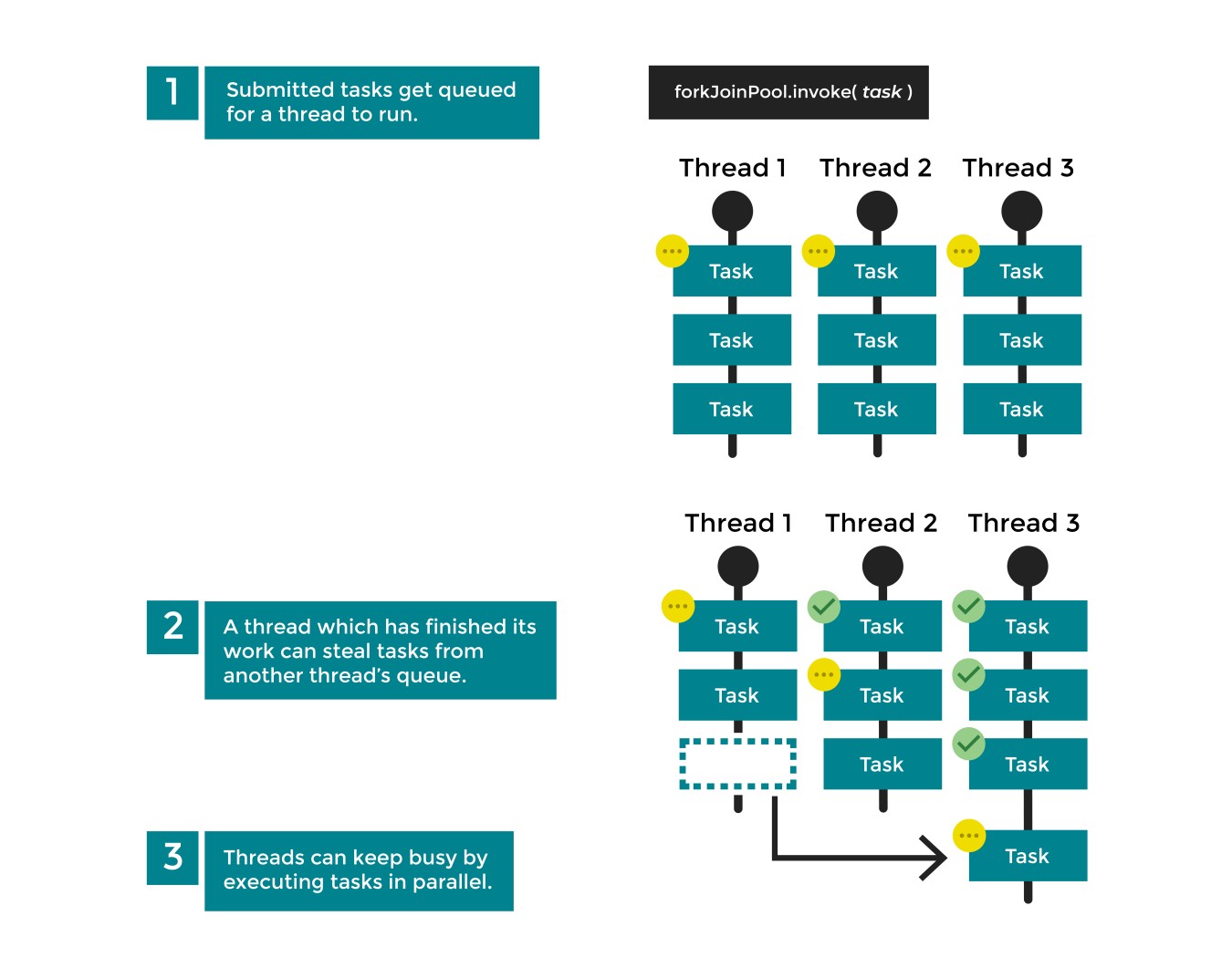
Let's break this down:
Step 1: First, invoke tasks on a thread. The tasks are lined up fairly for each thread.
Step 2: If a thread has completed all the tasks on its list, it takes a task from the waiting list of another thread. Each thread keeps busy working on the deconstructed tasks until they are all done.
As all the tasks are always executing continuously together at the same time, they are running in parallel as well as concurrently!
You've seen how ForkJoinPools and ForkJoinTasks can maximize your use of CPU resources while also simplifying your problem into a simple algorithm that can be repeatedly applied to your data.
Let's Recap!
ForkJoinPool is a highly efficient thread pool that allows threads to perform work-stealing in order to chip in and help one another complete any outstanding work. Since it keeps executing tasks, you can expect to see parallel levels of CPU utilization.
RecursiveTask is an abstract class for a ForkJoinTask that allows you to efficiently solve your problem with smaller tasks using a ForkJoinPool.
You should implement your solution by extending RecusiveTask and implementing its compute() method.
Your compute() method should structure solutions to break large tasks into smaller parts. It should be solvable using the same methods and code as the complete solution. The only difference is that they are applied to subsets of the complete dataset.
You can create smaller tasks by using the fork() method of your RecusiveTask and passing it a new instance of your task but with a subset of your task's dataset. By doing this over and over, you repeatedly break down your problem. The task is run on the ForkJoinPool.
By calling join() on a task, you block until that task is ready to return its result. You can then combine it with other results.
Now, test what you know about concurrency safeguards in the end-of-part quiz!
