Combat Shared-Mutability Using Atomic Variables
Understanding the Problem With Shared Mutability
Sharing can be hard. The same is true for data. Imagine getting a text from a friend telling you that they are in the same mall, standing by the crepe stand. You might text back saying that you're by the coffee shop. You both may pass one another while trying to find the other.

Without coordination, your shared plan might suffer because you both keep changing it. At some point, you need to coordinate so one of you can reach the other. Fortunately, you can solve this quickly by communicating better. The same is true for code.
Instances of threads can share static variables and encapsulated fields in a class, which they both have access to. For instance, if multiple threads are adding to some subtotal, both may read from it and add their own value to that subtotal. There are three operations involved in doing this:
Reading from the last value of a shared subtotal.
Adding a new value to the last value.
Assigning this back to the shared subtotal.
In code, this might look like:
public class Adder extends Thread {
static Integer SHARED_SUB_TOTAL=0;
private Integer valueToAdd;
public Adder(Integer value) {
valueToAdd=value;
}
@Override
public void run() {
Integer previousTotal = SHARED_SUB_TOTAL;
Integer newTotal = previousTotal + valueToAdd;
SHARED_SUB_TOTAL=newTotal;
}
}
Adder thread1 = new Adder(10);
Adder thread2 = new Adder(4);
thread1.start();
thread2.start();Now, what would happen if two threads both read the same initial value of the subtotal? Say it was set to 0. Imagine that both Thread 1 and Thread 2 read this value of subtotal. They then independently continue.
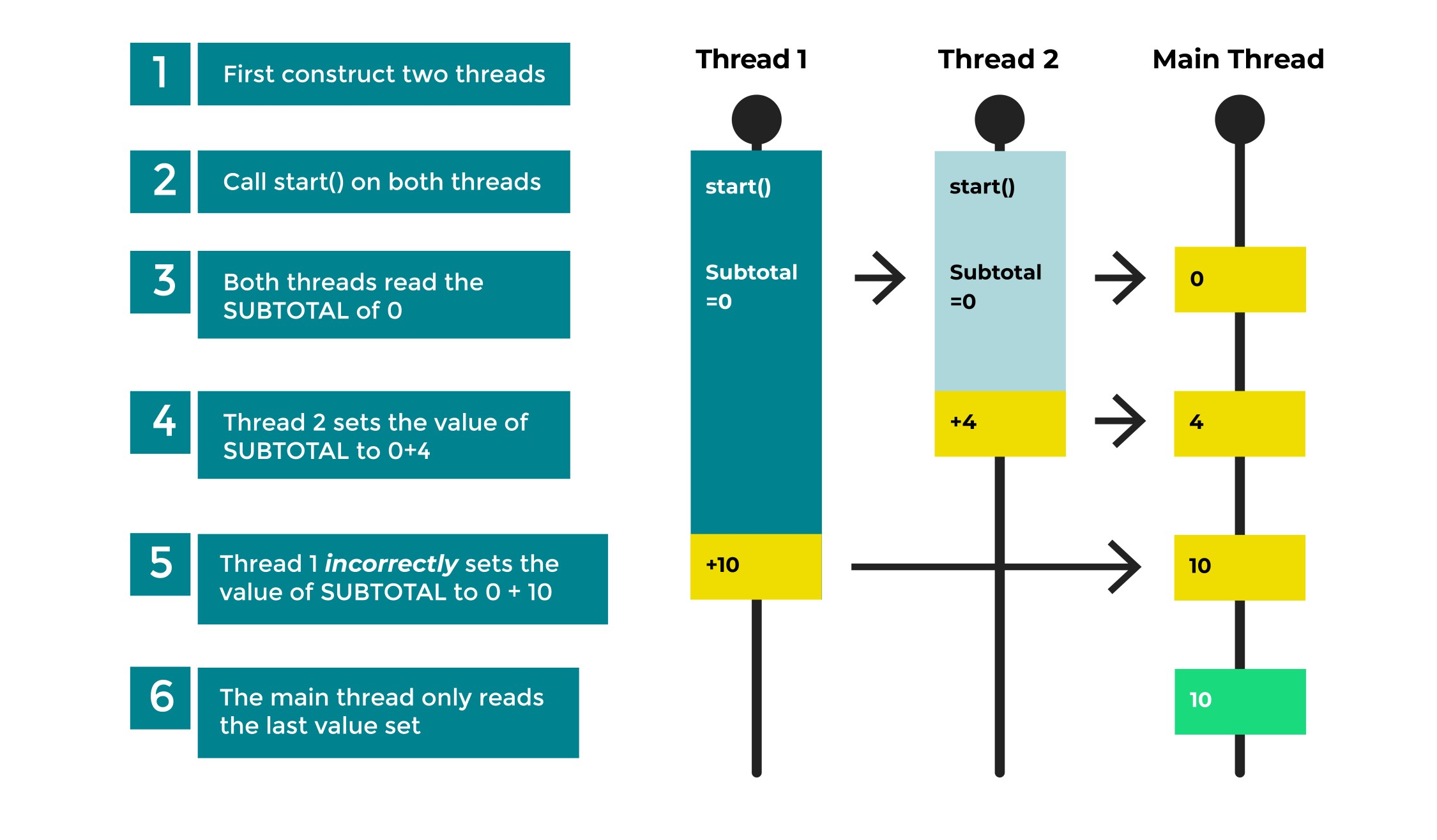
Steps 1-3: Start with a SUBTOTAL of 0, which both threads read.
Step 4: Thread 2 sets the SUBTOTAL value to 4 after adding its contribution.
Step 5: Thread 1, unaware of Thread 2's change, writes back the value of 10 after adding its contribution to the original value of zero. It loses the change made by Thread 2.
Step 6: SUBTOTAL is now set to 10 and is wrong! There should now be a subtotal of 14.
We call this a data race condition as the order in which you read and write threads affects the correctness of your code. For instance, if Thread 1 had read the value of SUBTOTAL a little later, it might have picked up the change made by Thread 2.
Obviously, code should be predictable. Therefore, find ways to avoid such race conditions.
How do we do that? 🤔
Even though there are three statements involved, all three should be performed as a single operation. That is, if you go back to the code above, you need to ensure that each thread gets to work with valid data from Line 13 to 15, which is not modified by another thread.
Those three lines need to be completed as a single operation in one thread before the other thread can even attempt to execute these steps. It's a little like Bob, waiting for Alice before heading off to find her.
Designing to Use Immutable Objects
As you saw, one of the problems is that you can keep changing the value of a shared variable and in so doing, any of the following may happen:
Another thread might have modified the variable since a particular thread read it. It's called a dirty read as the value, a thread it's working with, is no longer correct.
The value we wrote back to a thread may overwrite a more accurate value written by another thread shortly before.
Once you create threads that can start working together, the JVM provides no guarantees about the order in which they do things. To build concurrent software that can safely share variables, avoid changing the value of a shared variable in the first place.
Java provides the final field modifier, which you can prefix a variable with, to force a compile or runtime exception if a variable is ever set with a new value.
Since you can't change an object declared final, variables such as these are known as immutable, meaning that you can't change them. While this sounds like a panacea, using immutables requires you to redesign your application so that it can avoid a variable, or anything else, being shared across more than one thread.
Doing so involves deconstructing your problem, so each thread has just the data it needs to solve its part of the problem. If any method needs to modify a previous value, it instead returns a new value.
For instance, consider the following code, which calculates an average across a set of 50 samples, totaling up to 525:
{
ExecutorService es = Executors.newCachedThreadPool();
// Create a future and get a result
final double firstAverage = es.submit(()->200.0/50.0).get();
// Create a future and get a second result
final double secondAverage = es.submit(()->firstAverage + (225.0/50.0)).get();
final double thirdAverage = es.submit(()->secondAverage + (100.0/50.0)).get();
System.out.println(thirdAverage);
}Rather than share a common subtotal, each thread invocation returns its contribution, which in turn gets assigned to different final variables.
As you can see, each thread returns a result that is used by the next stage of the calculation to create a brand new variable with the updated average. In so doing, you keep creating a new immutable variable for each intermediate result.
When you stop changing variables and create a new one each time, your programs suddenly become a lot more predictable. You eliminate the risk of an important variable, such as a subtotal, getting changed to the wrong value by an undesirable order of execution across your threads.
Should I always break my code down to use immutable variables?
Although using immutables adds some predictability to an application, as you've seen above, it can also complicate your code. By having to create a new variable every time you want to change a value, you are given more complex code. The example only had three samples; however, this adds a lot more complexity as you have workers contributing intermediate results.
It's a good idea to use immutables wherever you can, but consciously so you don't lose the advantages of concurrency. There are some subjective questions you should ask yourself when you look at your code. If you choose to use immutable variables, ask yourself at least the following:
Is this new logic that makes my software too complex to maintain?
Does using immutable variables and recombining them into a solution negatively impact the performance so that it is undesirable?
Is there going to be any part of my solution that may attempt to modify the immutable?
There may be other questions, but in general, marking variables as final should be your default behavior. It doesn't just apply to parallel code, but also other parts of your application. Why mark something as being able to change, unless it needs to?
Using Atomic Types
The limitations you saw with using immutable variables were that:
The calling thread had to wait for a Future to complete.
Multiple Futures could not simultaneously modify a variable; even if it was required for the simplest and safest design.
Both of these points relate to behaviors that force you to choose between writing secure concurrent software, speed of execution, and complexity of your code. There is a solution!
Java's Atomic package provides you with a first glimpse into the concurrency framework's thread-safe data structure, or in other words, Java types that just work safely. That is, you can use or modify them in concurrent situations without the risk of the sort of read/write data race conditions you saw earlier.
Atomic variable types from Java's java.util.concurrent.atomic package can offer an easy fix. They provide companions to several standard Java types, such as AtomicIntegers and AtomicBooleans. These companions are guaranteed to be safe to mutate by threads. The atomic types do this by giving exclusivity to a particular thread on methods that combine accessing, modifying, and updating them.
A combined group of operations in code guaranteed to happen together is called an atomic operation. It ensures that only one thread at a time can execute an atomic operation, and any other thread has to wait.
Creating a Thread-Safe Counter
Start JShell and follow along:
Step 1: First, import one of the AtomicTypes. In this case, AtomicInteger.
jshell> import java.util.concurrent.atomic.AtomicIntegerStep 2: Create a thread-safe class. Use this to keep track of a value which multiple threads will update.
Consider the following block of code that creates a thread that has a static subtotal:
jshell> public class SafeThread extends Thread {
...> static final AtomicInteger subTotal = new AtomicInteger(0);
...> public void run() {
...> int currentValue = subTotal.addAndGet(2);
...> System.out.println( "Updated subtotal to " + currentValue );
...> }
...> }
| created class SafeThread
Let's break it down.
Line 1: Create a thread called SafeThread, by subclassing Thread.
Line 2: Override the run() method.
Line 3: Call the addAndGet(2) method on AtomicInteger ensuring that only one thread at a time can query the previous value and add a new one. In this case, it adds 2 to the previous value and returns the new one.
Line 4: For the sake of illustration, print out the new value which you just got back.
Step 3: It's time to create some threads and run this!
jshell> SafeThread t1 = new SafeThread();
t1 ==> Thread[Thread-0,5,main]
jshell> SafeThread t2 = new SafeThread();
t2 ==> Thread[Thread-2,5,main]
jshell> t1.start(); t2.start();
Updated subtotal to 2
Updated subtotal to 4
As you can see, there are new threads on Lines 2 and 5. Start them both at Line 7.
Both threads update in turn and never overwrite one another's values.
If our code is now predictable, what are the ways in which it might run?
There are generally two possible executions of this:
Thread 1 could potentially set a value of subtotal first.
If Thread 1 executes
addAndGet(2)first, it is guaranteed thatThread 2's invocation will be after this invocation has returned and modified the atomic.
Thread 2 will not interrupt this execution of
addAndGet().
There is also another possible execution, which does the same thing but allows Thread 2 to run first. Thanks to the AtomicInteger, both the read and the write of the atomic variable will happen together, without interruption from other threads.
As you can see in this execution, the threads always wait on one another
when modifying an atomic variable.
Are there other atomic types?
The java.util.concurrent.Atomic package provides several AtomicTypes. Some of the more commonly used are:
Class | Description |
This provides atomic operations allowing threads to share and mutate a boolean. | |
This provides atomic operations allowing threads to share and mutate an integer. | |
This provides atomic operations allowing threads to share and mutate a long. | |
This provides atomic operations allowing threads to share and mutate any referenced Java object. You can use this to turn other Java types, such as doubles or custom objects, into atomics. |
Modify Our Planet File Analyzer to Use Atomic Types: Practice!
Let's add it to the program and use it to ensure that we can have multiple futures concurrently and safely calculating a single average.
Let's break down the atomic type code:
Step 1: First, define two atomic variables:
public class AtomicBasedFileAnalyzer {
// Our atomics
private AtomicInteger sampleSize = new AtomicInteger(0);
private AtomicReference<Double> temperatureSum = new AtomicReference<>(0.0);
...Line 4: Create an AtomicInteger initialized with 0, which is used for counting the sample size.
Line 5: Use an AtomicReference of type double to sum the temperatures. This is created by passing the double value of 0.0 to the AtomicReference.
Step 2: When a file is passed to the processFile (Path path) method, update two variables for each temperature in the file.
public void processFile(Path path) {
...
getDoublesFromFile(path)
.forEach(temperature -> {
// atomically increment the sample size
sampleSize.incrementAndGet();
// atomically update the counter
temperatureSum.updateAndGet((current -> {
return current + temperature;
}));
});
..
}Line 4: Iterate through each temperature in the file.
Line 6: Atomically increment the sample size. Each thread takes its turn.
incrementAndGet()also returns the current value after incrementing, so assign and use this if you want to.Line 9: Call updateAndGet() and pass it a lambda which is used to update the double guarded by the AtomicReference.
Line 10: Within the lambda, add a new temperature to the previous sum of temperatures. This is part of the operation that started at Line 9. Other threads won't be able to update the temperatureSum until the lambda has completed.
The process method is called from the main method, which creates a separate Future for each file being processed:
Future futureOfFileOne = executorService.submit(() -> fileAnalyzer.processFile(fileOnePath));
Future futureOfFileTwo = executorService.submit(() -> fileAnalyzer.processFile(fileTwoPath));
Running the Benchmark
I'll run it first:
Your turn! I've updated the benchmark to measure the impact of this change.
Check out the repository and see how it performs.git checkout p1-c5-shared-atomic-mutableYou can run the benchmark the same way you did previously, by running the runBenchmarks task.
./gradlew runBenchmarksFor me, the benchmark shows:
Benchmark Mode Cnt Score Error Units BenchmarkRunner.benchmarkAtomicsWithFutures thrpt 30 21.619 ± 5.918 ops/s BenchmarkRunner.benchmarkFuturesWithExecutorService thrpt 30 45.676 ± 2.020 ops/s BenchmarkRunner.benchmarkMultiProcess thrpt 30 1.611 ± 0.071 ops/s BenchmarkRunner.benchmarkParallelStream thrpt 30 55.090 ± 5.112 ops/s BenchmarkRunner.benchmarkRawThreadsWithFutureTasks thrpt 30 41.045 ± 1.018 ops/s BenchmarkRunner.benchmarkSingleProcess thrpt 30 18.593 ± 0.870 ops/sUsing atomics in this way only has a throughput of 21 runs per second, which makes it almost twice as slow as the raw thread implementation.
Why is this slower, if we're adding as we go?
Every time we add temperature or increment the sample counter, we lock access to our atomic. The scheduler suspends all other threads trying to interact with the atomic variables. That extra time adds up. Another option is to block the addition of just one value for each file, rather than making a chance for each row.
It can be tempting to employ atomic variables all over the place, but as you've seen, this can result in slower code, albeit extremely safe since only one thread at a time can utilize it. Using an atomic is like making every other car on the road stop, while one car inspects and changes lanes. It's likely to result in massive delays.
But aren't atomic variables safer?
Using a lot of atomic variables is exceptionally safe and slow. Similarly, using them to represent values that are frequently changed by many threads can offset the advantages of concurrency. It locks down your atomic variable so that only one thread can use it and pause every other thread which tries to access it.
You may be using concurrency, but each thread is now waiting on a single thread to complete. When locking data structures or blocking access to code happens more than is desirable, it's called overlocking.
By measuring a realistic frequency of updates to a shared atomic, you can
decide on whether the impact of using one negatively impacts your application's performance.
Let's Recap!
Shared mutables are variables or other resources that may be modified by different threads. Since the order of execution between individual threads is not predictable, you need to be careful that threads don't overwrite one another's changes or read stale data.
Atomic operations are operations that are always executed sequentially without interruption from other threads.
AtomicReferences, AtomicIntegers, and other atomic types allow you to read and modify their value in one atomic operation.
Avoid overlocking or overblocking as stopping threads too much may slow down your application.
Now, get ready to check what you've learned about Java concurrency in the end-of-part quiz!
