Recherchez une différence entre les sous-groupes

Découvrez la qualification des sous-groupes
Antoine, qui vous avait demandé de travailler sur la densité de population et les départements, revient vers vous pour savoir où vous en êtes.
Vous avouez être un peu perdu ; il vous explique donc que les variables qualitatives du jeu de données ont toutes un nombre fini de modalités, ce qui revient à partager les données sous forme de groupes.
Si certains groupes sont liés, par exemple un département n’a qu’un seul niveau de densité de population, ou le même chef-lieu, ce n’est pas le cas de tous.
Il peut donc y avoir la création d’intersections de groupes. Analyser le lien entre deux variables qualitatives, par exemple entre le niveau de densité de population et les départements, revient à se demander si au moins l’un des sous-groupes créés est différent des autres.
De quels sous-groupes parle-t-on ?
Prenons le cas des régions et de la densité de population :
Dans le blueprint, il vous est demandé de visualiser la densité de population à l’échelle de la région sélectionnée.
Il faut donc que vous calculiez la quantité de départements concernés pour les différents niveaux de population.
Il y aura donc pour chaque région, la possibilité de savoir combien de départements sont
peu peuplé,peuplé,très peupléetsurpeuplé.
Un des sous-groupes créés est doncBretagne etpeuplé .
Pour le dire autrement, les sous-groupes peuvent être visualisés grâce à un tableau à double entrée tel que celui-ci.
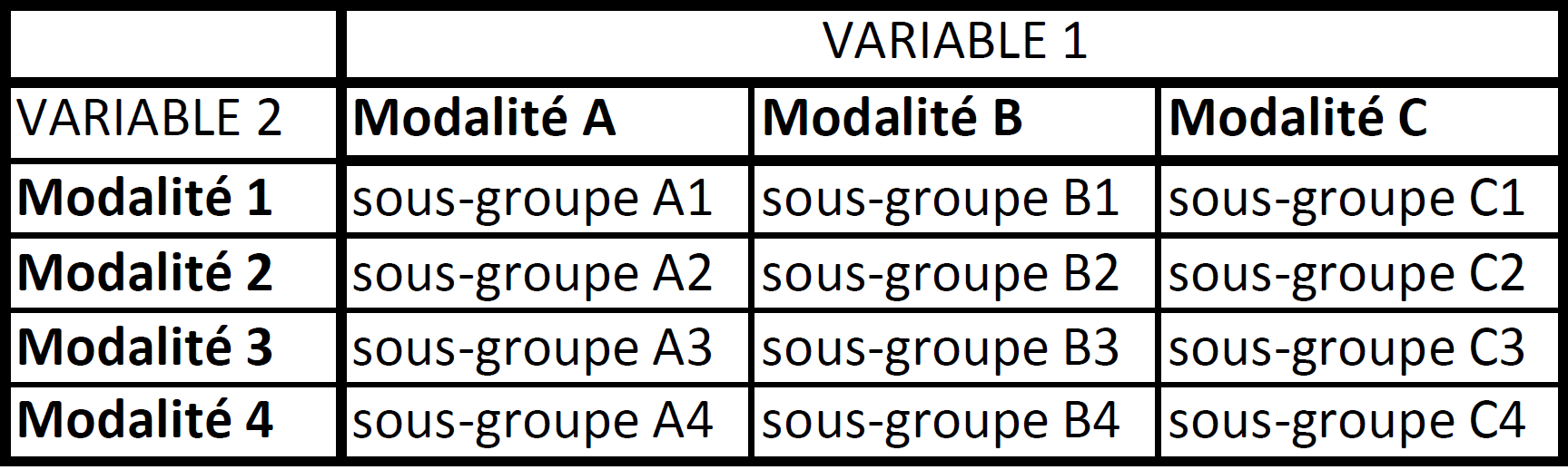
Le nombre de sous-groupes obtenus est donc le multiple du nombre de modalités des deux variables : 4 * 3 = 12 pour l’exemple ci-dessus, 13 * 4 = 52 pour le cas de la région avec le niveau de densité de population.
Il est important de connaître le nombre de modalités de chaque variable, car il permet de calculer le degré de liberté.
La définition est très obscure, donc passons par un exemple pour mieux la comprendre.
Nous lançons 60 fois un dé à 6 faces. Si nous savons que nous avons obtenu 11 fois la face
1, 9 fois la face2, 7 fois la face3, 10 fois la face4et 14 fois la face5, on peut déduire que la face6est sortie 9 fois ; le degré de liberté est donc 5 car il faut en connaître 5 pour déduire la dernière.D’un point de vue pratique, le nombre de degrés de liberté se calcule en retirant un au nombre de modalités pour une variable : ddl = n - 1 = 6- 1 = 5.
Dans le cas de deux variables, c’est le produit des degrés de liberté des deux variables : ddl = (n - 1) * (k - 1), soit (3 - 1) * (4 - 1) = 6 dans le cas du tableau présent et (13 - 1) * (4 - 1) = 36 dans le cas du jeu de données.
Donc le nombre de degrés de liberté varie en fonction de la forme du tableau à double entrée ?
Oui effectivement, le degré de liberté peut aussi se calculer ainsi : (nombre de lignes - 1) * (nombre de colonnes - 1).
Représentez ce lien
La façon la plus simple pour visualiser le lien entre les variables qualitatives est de construire un tableau de contingence.
En R, plusieurs fonctions permettent de représenter les tableaux de contingence :
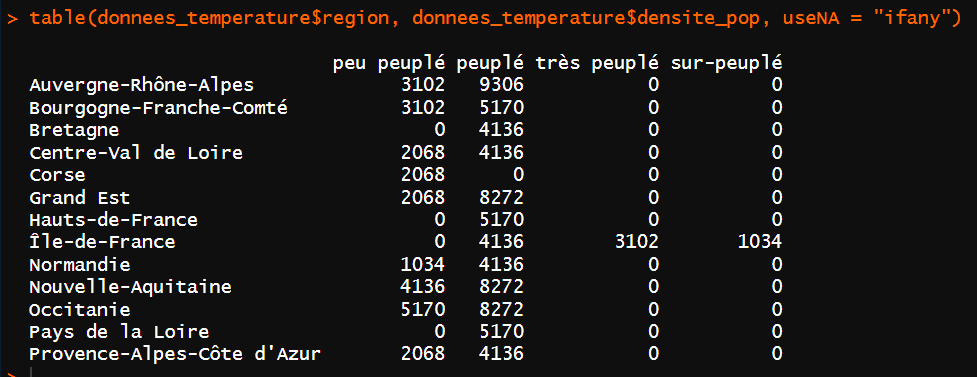
table()du package{base}qui met sous la forme d’un tableau à double entrée. Attention, les valeurs manquantes ne sont pas affichées par défaut, il faut utiliser l’argumentuseNA = "ifany"pour les afficher.
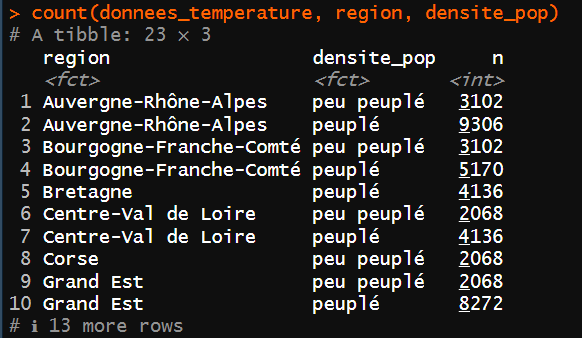
count()du package{dplyr}qui met les données sous la forme d’une liste mais n’affiche pas les couples manquants. Pour les afficher, il faut utiliser.drop = FALSE.
Si avoir un tableau est souvent très utile, il est difficile d’en tirer des conclusions d’un coup d'œil. Le mieux est donc d’utiliser une carte des points chauds (“heatmap”, en anglais) pour visualiser les croisements avec plus ou moins de données.
Avec le package {ggplot2} , la carte des points chauds se réalise grâce à la fonction geom_tile() à partir d’un tableau de contingence créé par la fonction count() du package {dplyr} .
donnees_temperature |>
count(region, densite_pop) |>
ggplot() +
aes(x = densite_pop, y = region, fill = n) +
geom_tile() +
theme_classic()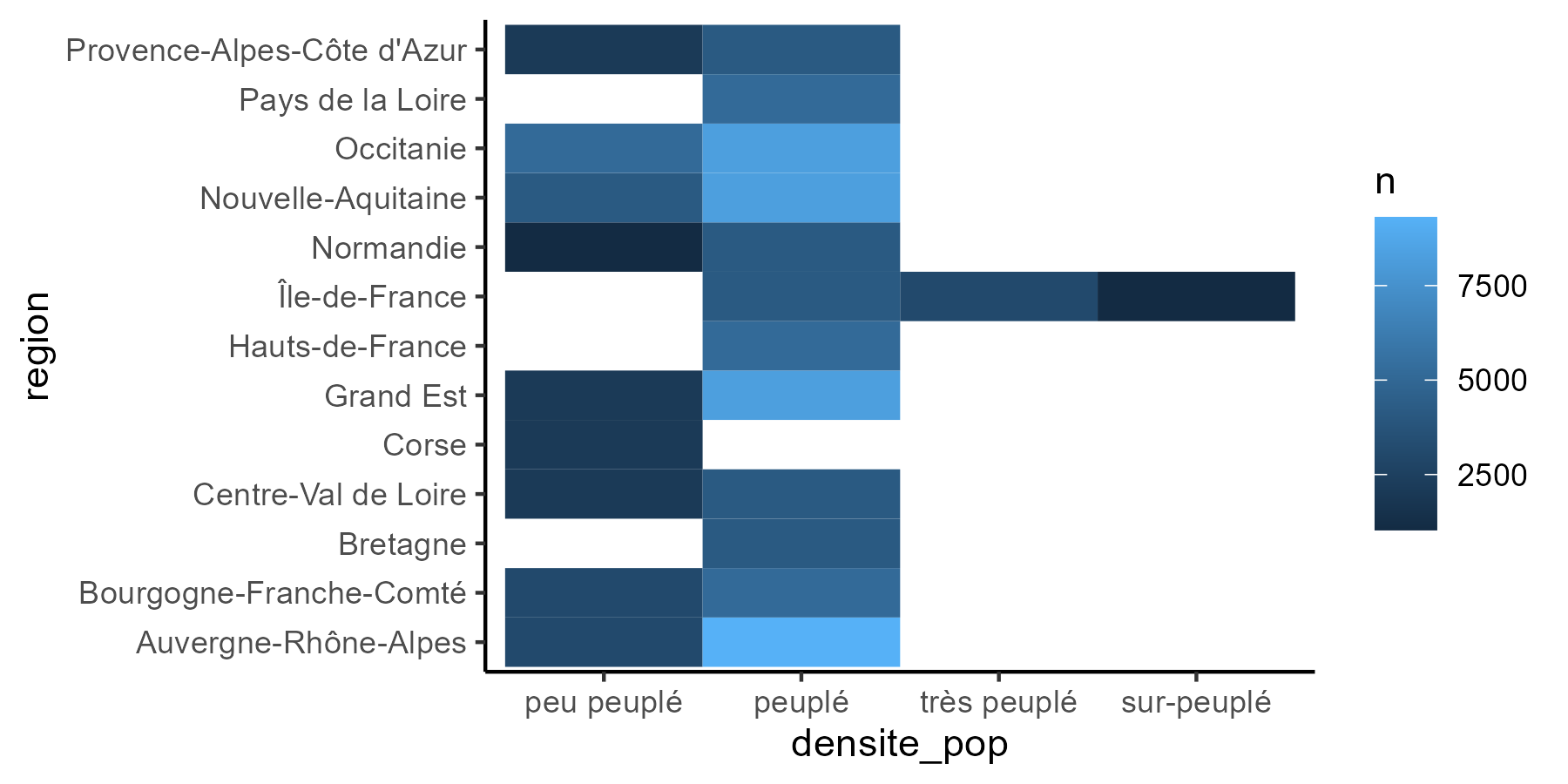
D’un coup d'œil, la carte des points chauds permet de voir que l’île-de-France est une région particulière et que quatre régions ont une densité de population homogène : trois (Bretagne, Hauts-de-France et Pays de la Loire) où tous les départements sont peuplé et un, la Corse, où les départements sont peu peuplé .
Vérifiez l’existence du lien
La différence que l’on peut détecter visuellement entre les sous-groupes n’est pas une preuve. Il est conseillé de réaliser des tests d’hypothèse pour confirmer ou infirmer cette différence.
Un test couramment utilisé pour savoir si au moins un des sous-groupes est différent des autres est celui du Khi-deux d’homogénéité. Dans ce cas, l’hypothèse :
nulle est que tous les groupes sont similaires ;
alternative est qu’au moins un des groupes est différent des autres.
Dans le cas d’un test d’hypothèse comme celui-ci, il y a deux possibilités :
Le test est significatif, comprenez que la p-valeur est inférieure à = 0,05. L’hypothèse nulle est rejetée au profit de l’hypothèse alternative -> Au moins un des groupes est différent des autres.
Le test n’est pas significatif, c’est-à-dire que la p-valeur est supérieure à = 0,05. Dans ce cas, l’hypothèse nulle n’est pas rejetée ; cela signifie qu’à priori, aucun groupe n’est différent des autres.
Dans R, le test du Khi-deux est réalisé grâce à la fonction chisq.test() du package {stats} . Cette fonction peut prendre :
un vecteur pour le comparer à une distribution attendue ;
deux vecteurs pour les comparer entre eux ;
une matrice pour analyser les sous-groupes. Comme ici grâce à l’utilisation de la fonction
table():
table(donnees_temperature$region, donnees_temperature$densite_pop) |>
chisq.test()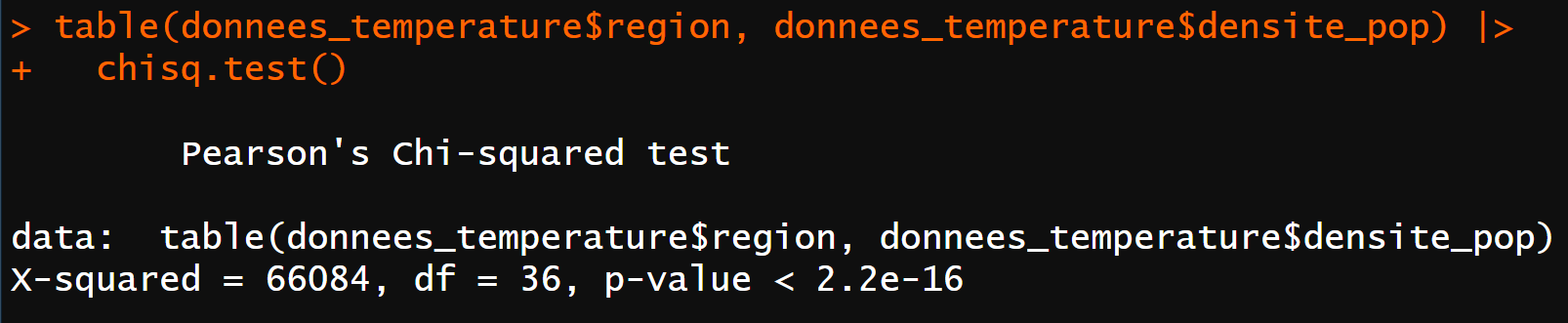
La sortie du modèle montre que :
Le nombre de degrés de liberté,
df = 36, est bien celui que l’on attendait (13 régions - 1) * (4 niveaux de densité - 1) = 12 * 3 = 36.Le test est significatif,
p-value < 2.2e-16car la p-valeur < 0,05 -> au moins un des sous-groupes créés est différent des autres.
Que signifie X-squared = 66084 ?
C’est la statistique de test, c'est-à-dire une valeur calculée par le test qui est comparée à des tables de référence. Elle sert à calculer la p-valeur que vous utilisez pour trancher si un modèle est significatif ou non.
À vous de jouer

Contexte
Antoine revient vers vous.
Il est content de ce que vous avez fait pour l’analyse de densité de population en fonction de la région, mais il aurait besoin que vous la fassiez à nouveau en excluant l’Île-de-France afin de se concentrer sur les différences en province.
Consignes
Vous devez donc :
Créer une table avec seulement les régions concernées.
Visualiser sous forme d’une carte des points chauds.
Utiliser le test adapté pour mesurer les différences entre les régions.
En résumé
Dans le cas de deux variables qualitatives, le lien est analysé en comparant les sous-groupes entre eux.
Le nombre de degrés de liberté est dépendant du nombre de modalités dans chaque variable analysée et non du nombre de sous-groupes créés.
Les nombres d’observations peuvent être visualisés dans un tableau de contingence et dans une carte des points chauds.
Le test de Khi-deux nous permet de savoir si au moins un des sous-groupes est différent des autres, mais pas lequel.
Après avoir exploré les liens entre les paires de variables quantitatives puis qualitatives, vous allez voir l’influence d’une variable qualitative sur une variable quantitative dans le prochain chapitre.
