Déterminez la distribution des données
 Vos données sont collectées et nettoyées, mais comment savoir si elles sont vraiment prêtes pour une analyse plus approfondie ? Avant de plonger dans le choix des tests, vous avez besoin de bien comprendre la structure de vos données pour sélectionner le test statistique qui convient à vos besoins. Nous avons rapidement abordé la notion de “distribution statistique” dans le chapitre “Visualisez les données” mais ici nous allons rentrer dans le détail.
Vos données sont collectées et nettoyées, mais comment savoir si elles sont vraiment prêtes pour une analyse plus approfondie ? Avant de plonger dans le choix des tests, vous avez besoin de bien comprendre la structure de vos données pour sélectionner le test statistique qui convient à vos besoins. Nous avons rapidement abordé la notion de “distribution statistique” dans le chapitre “Visualisez les données” mais ici nous allons rentrer dans le détail.
Comprenez le concept de distribution statistique
La distribution statistique révèle comment les valeurs d'un ensemble de données sont réparties. Elle nous donne une vision globale de nos données. Pour les décrire, nous utilisons deux types de mesures de tendance :
La mesure centrale comme la moyenne ou médiane. Elle donne un centre autour duquel les données sont concentrées.
La mesure de dispersion montre à quel point les données sont étalées ou regroupées. Et pour ça, on utilise la variance et l’écart type.
Supposons que nous ayons un petit ensemble de données : 2, 4, 4, 4, 5, 5, 7, 9. Pour calculer la variance :
Calculez la moyenne
Calculer les écarts par rapport à la moyenne, les élever au carré, puis faire la somme de ces carrés :
Calculer la variance :
Calculer l'écart-type :
Dans cet exemple, la variance est de 4 et l'écart-type est de 2. Cela signifie que les valeurs de notre ensemble de données sont, en moyenne, à une distance de 2 unités de la moyenne.
Pour rendre les choses plus lisibles, regardons ensemble comment les visualiser.
Visualisez une distribution
Il existe plusieurs types de distribution :
Gaussienne ;
Binomiale et
En poisson.
La distribution qu’on appelle gaussienne est la plus célèbre et la plus utilisée des distributions en statistique. En tout cas, c’est celle sur laquelle nous allons nous focaliser. Je suis certain que vous savez à quoi ça ressemble. Elle est définie par sa forme de cloche symétrique et est déterminée par deux paramètres : la moyenne et l'écart type. Les données sont regroupées en bacs (pour l'histogramme) ou lissées en une courbe continue. La symétrie de la distribution autour de sa moyenne est un indicateur clé qui montrerait que les données suivent une distribution normale. Tout ça est à confirmer avec des tests statistiques poussés !
La distribution gaussienne est utilisée dans de nombreux domaines, incluant les tests d'hypothèses où les échantillons sont supposés provenir d'une population normalement distribuée.
Voici un exemple d’histogramme qui analyse le budget annuel des clients de l’agence VertiGo.
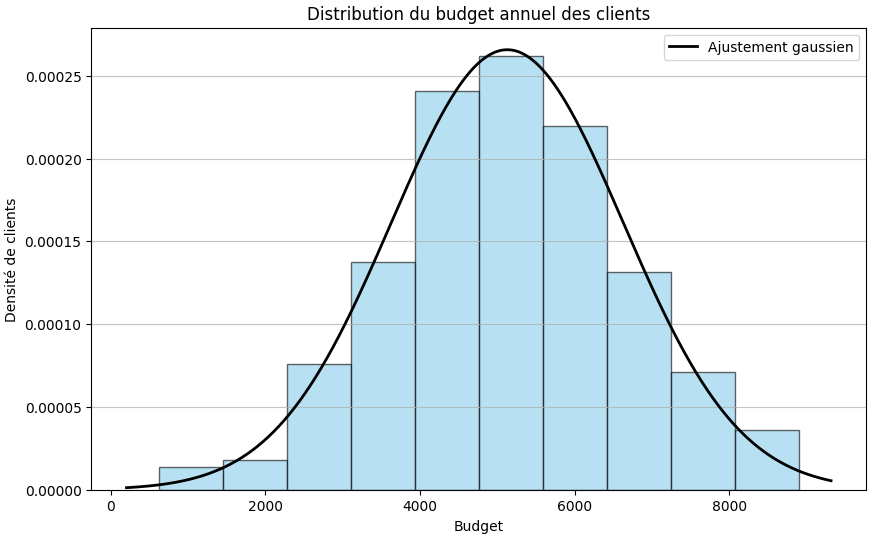
La forme de cloche montre bien que nous sommes sur une distribution gaussienne. La moyenne indique que le budget voyage moyen des clients de VertiGo est de 5126,0 euros. L’écart-type de 1504 euros montre que la plupart des budgets se concentrent autour de la moyenne.
Et voici maintenant comment cet histogramme a été généré en Python.
Ce code charge les données, extrait la colonne des budgets annuels, calcule la moyenne et l'écart type, puis génère l'histogramme avec la courbe gaussienne et affiche les résultats.
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
from scipy.stats import norm
# Charger les données depuis le fichier CSV
file_path = 'chemin/vers/votre/fichier/Données+clients+VertiGo+nettoyées.csv'
data = pd.read_csv(file_path)
# Extraire la colonne 'budget voyage annuel'
budgets = data['budget voyage annuel'].dropna()
# Calculer la moyenne et l'écart type
mean_budget = budgets.mean()
std_budget = budgets.std()
# Afficher les valeurs calculées
print(f"Moyenne du budget annuel : {mean_budget}")
print(f"Écart type du budget annuel : {std_budget}")
# Tracer l'histogramme avec une courbe gaussienne
plt.figure(figsize=(10, 6))
# Histogramme
plt.hist(budgets, bins=10, density=True, color='skyblue', edgecolor='black', alpha=0.6)
# Ajustement gaussien
mu, std = norm.fit(budgets)
xmin, xmax = plt.xlim()
x = np.linspace(xmin, xmax, budgets.count())
p = norm.pdf(x, mu, std)
# Tracer la courbe gaussienne
plt.plot(x, p, 'k', linewidth=2, label='Ajustement Gaussien')
# Ajouter les titres et légendes en français
plt.title('Histogramme du Budget Annuel des clients')
plt.xlabel('Budget)
plt.ylabel('Densité de clients')
plt.legend()
# Afficher le graphique
plt.show()Cette vidéo vous montre comment visualiser la distribution des données.
À vous de jouer
Contexte
À partir de “Données clients VertiGo nettoyées”, votre objectif est de visualiser la distribution de la durée annuelle moyenne à laquelle les clients de VertiGo consacrent leur budget de voyages.
Consignes
Produisez en Python un histogramme pour vérifier si la distribution des données suit une courbe gaussienne.
Calculez la moyenne et l’écart-type.
Interprétez les résultats.
Livrable
Rédigez un script Python et un rapport qui fournit l’interprétation des résultats obtenus.
En résumé
La distribution statistique révèle comment les valeurs d'un ensemble de données sont réparties et nous offre une vision globale des données.
La moyenne et la médiane sont des mesures centrales qui indiquent le centre autour duquel les données se concentrent.
L'écart type et la variance montrent à quel point les données sont étalées ou regroupées par rapport à la moyenne.
La distribution gaussienne, caractérisée par une forme de cloche symétrique, est déterminée par la moyenne et l'écart type, et elle est couramment utilisée pour analyser les données.
Utiliser des histogrammes et des courbes pour visualiser les distributions permet de mieux comprendre la répartition des données et de confirmer si elles suivent une distribution normale.
Vous pouvez presque affirmer que vos données suivent une distribution normale. Mais cette simple visualisation n’est pas suffisante ! Il faut tester la normalité de cette distribution avec plus de précisions, une condition préalable pour de nombreux tests statistiques.
