Recherchez une bonne partition
Dans la partie précédente, nous avons travaillé à synthétiser les variables, c'est-à-dire à réduire le nombre de colonnes de notre tableau de données.
Dans cette 3e partie, nous allons regrouper les lignes, c'est-à-dire que nous allons créer des groupes d'individus : nous allons partitionner les données !
Partitionnez vos données
Voici un petit exemple. Nous souhaitons regrouper les individus en 3 groupes.
À l’œil, on voit ces 3 groupes : l'un est très distinct, et les 2 autres se superposent un peu :
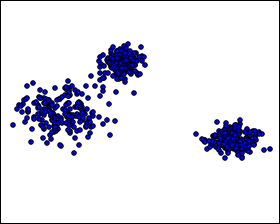
Déterminer des groupes peut être l'objectif premier, mais on peut aussi vouloir réduire la taille de notre jeu de données en regroupant certaines lignes.
Dans l'échantillon ci-dessus, on a 150 individus répartis en 3 groupes différents. Chaque individu est caractérisé par variables. Au sein d'un même groupe, les individus sont à peu près similaires, car ils sont proches dans l'espace.
Comme les individus d'un même groupe sont similaires, on peut parfois se contenter d'étudier les caractéristiques du groupe plutôt que d'étudier chacun des individus qui le composent.
Autrement dit, cela revient à étudier les caractéristiques de "l'individu moyen" de chaque groupe.
Ainsi, on peut se ramener à un tableau à colonnes (les variables) et à 3 lignes. Chaque ligne correspond à l'individu moyen des 3 groupes.
Le challenge sera donc de trouver des méthodes qui font perdre le moins d'information possible ! Il nous faut donc un critère pour évaluer la qualité d'une partition.
Évaluez la qualité d'une partition
Reprenons nos données, et déterminons 2 partitions différentes, chacune en 2 classes (une classe bleue et une classe rouge) :
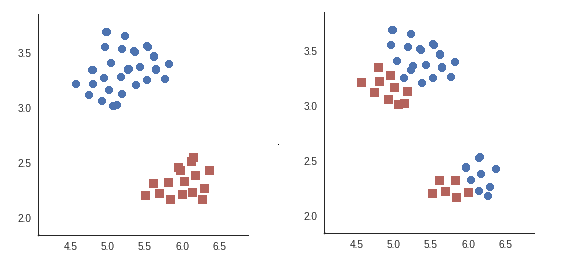
Qu'en pensez-vous ? La partition de gauche paraît meilleure que celle de droite, n'est-ce pas ? Pourquoi ? Parce que, sur l'image de droite, les points des groupes bleu et rouge sont pour chacun très étalés. De plus, les groupes bleu et rouge sont très proches l'un de l'autre.
Au contraire, sur l'image de gauche, le groupe rouge et le groupe bleu sont chacun peu étalés, et ils sont loin l'un de l'autre.
Je pense que, maintenant, vous avez le réflexe : dès que je parle de points "étalés", vous pensez inertie !
Bingo ! En fait, on ne va pas mesurer l'inertie du nuage de points tout entier, mais celle des différents nuages correspondant à chaque groupe.
Rappelons-nous la formule de l'inertie d'un nuage de points, que nous avons vue précédemment :
où est le nombre d'individus, et la distance entre le point et le centre de gravité du nuage.
On peut calculer cette quantité pour chaque groupe, puis les additionner (en leur donnant un poids proportionnel au nombre d'individus qu'ils contiennent). On obtient ainsi l'inertie intraclasse :
où est le nombre de clusters, le nombre d'individus dans le cluster , et le centre de gravité du cluster .
L’inertie intraclasse est aussi appelée variance intraclasse ou variation intraclasse.
Par cet indicateur, on cherche à répondre à la question “À quel point nos clusters sont homogènes ?” ou autrement dit, sont "resserrés" ?
Ensuite, pour voir si les groupes sont éloignés les uns des autres, on s'imagine un nouveau nuage de points qui est composé uniquement des centres de gravité des différents groupes. Si ces groupes sont éloignés, alors leurs centres de gravité respectifs le seront aussi. L’inertie de ce nouveau nuage imaginaire sera donc grande. On l'appelle inertie interclasse, et elle est donnée par :
où est l'effectif de la classe , le centre de gravité du cluster , et le centre de gravité du nuage tout entier.
L’inertie interclasse est aussi appelée variance interclasse ou variation interclasse.
Par cet indicateur on cherche à répondre à la question “À quel point nos clusters sont éloignés les uns des autres ?”.
Que de mots, que de termes techniques...
On pourrait pas en rajouter un pour le plaisir ?
Si, si, si, bien volontiers! On peut rajouter le terme centroïde !
Le centroïde, c’est le centre de gravité du cluster. C’est en fait l’individu théorique moyen du cluster. Il est théorique car il n’existe pas vraiment, et il est moyen car il se calcule en prenant la moyenne des différentes composantes des individus du cluster…
Des termes techniques et complexes, mais toujours pour des concepts simples !
Effectivement... Beaucoup de termes techniques, beaucoup de "jargon" mais au final, en relisant tout cela au calme, et avec un peu de logique, vous verrez qu'il n'y a vraiment rien de difficile ni de complexe.
On peut toutefois faire un petit récapitulatif avant de passer à la suite.
Rappelons-nous les critères d'une bonne partition. On veut que les groupes (aussi appelés clusters) soient :
Resserrés sur eux-mêmes : deux points qui sont proches devraient appartenir au même groupe.
Loin les uns des autres, c'est-à-dire qu'ils soient fortement différenciés.
Le premier critère correspond à une inertie intraclasse faible, et le second critère correspond à une inertie interclasse forte.
Cela est dû au fait que : inertie totale = inertie intraclasse + inertie interclasse.
Or, quelle que soit la partition, l'inertie totale est constante. Minimiser l'inertie intraclasse est donc équivalent à maximiser l'inertie interclasse ! Cette formule est appelée théorème de Huygens ou équation d'analyse de la variance.
Certains d’entre vous qui ont déjà fait de l’apprentissage supervisé, comme de la classification ou de la régression, ont peut-être un sentiment…
Il est plus simple de calculer la performance de son "travail" en apprentissage supervisé qu’en apprentissage non supervisé. C’est vrai !
Il nous faut nous tourner vers des notions plus abstraites. Même si ces notions ne sont, au final, pas si complexes que cela !
Et au fait, existe-t-il d’autres scores pour juger d’un bon clustering ?
Oui ! Même si nous n’allons pas insister dessus. Retenez qu'il existe plusieurs "scores" pour évaluer un bon clustering comme, par exemple :
l'indice de Davies Bouldin qui prend en compte la variance intraclasse et interclasse ;
le Silhouette Score qui prend en compte l'appartenance de chaque individu au plus proche cluster.
En résumé
Quand on cherche à synthétiser les lignes, on fait du clustering. C’est une forme d’apprentissage dite non supervisée.
On peut regrouper une très grande quantité d’individus derrière un nombre très restreint de clusters.
Pour chaque cluster on peut calculer le centroïde, c’est-à-dire l’individu théorique moyen.
Un bon clustering peut s’analyser sous 2 aspects. D’une part les groupes sont resserrés sur eux-même, d’autre part les clusters sont éloignés les uns des autres.
Ces deux notions ont un terme spécifique, on parle de variance intraclasse et de variance interclasse.
On cherche à minimiser la variance intraclasse et à maximiser la variance interclasse.
Il existe d’autres indicateurs plus complexes, comme l’indice de Davies Bouldin et le Silhouette Score.
Maintenant que vous savez partionner vos données, découvrons les algorithmes k-means. Allons-y !
