Choisissez le nombre de composantes
Depuis le début de ce cours, on parle de composantes principales.
Nous avons vu comment les étudier, mais nous n’avons pas vu combien en étudier : doit-on étudier seulement le premier plan factoriel, ou doit-on aller plus loin ?
Réfléchissons un peu...
Tout d’abord, posons-nous la question suivante :
Combien d’axes d’inertie peut-on trouver ?
Prenons un plan sur lequel vous tracez un axe au hasard. Si vous devez en tracer un deuxième, orthogonal au premier, vous n’avez pas le choix dans la direction : c'est la direction que vous indique votre équerre. Si maintenant on vous demande de tracer un 3e axe orthogonal aux 2 premiers, vous verrez que cette tâche est impossible ! La raison est que, dans un espace à dimensions, vous ne pouvez trouver que axes orthogonaux au maximum.
Mais de combien d’axes a-t-on besoin pour décrire parfaitement individus ?
Plaçons 2 points dans un espace à dimensions. Pour capter 100 % de l’inertie de ce nuage de points, un seul axe suffit : ce sera la droite qui passe par ces 2 points. Donc ici, 1 axe suffit pour 2 points.
De même, prenons 3 points dans un espace en 3D. Pour capter 100 % de l’information, il suffit de faire passer un plan par ces 3 points, et un plan c’est en 2D. Ici, 2 axes suffisent donc pour 3 points. Pour décrire parfaitement individus, on a donc besoin au maximum de axes.
Mais comme nous avons dit tout à l’heure, on ne peut pas trouver plus de axes.
Si l'on assemble ces deux contraintes, on arrive à cette conclusion :
Ainsi, si vous avez un échantillon de 2 000 individus décrits par 1 000 variables, vous trouverez 1 000 composantes.
Mais vous vous doutez qu’il ne faudra pas analyser chacune de ces 1 000 composantes. Non, ce serait trop de travail !
Combien de composantes analyser ?
Alors, combien de composantes analyser ?
Vous savez qu’en ACP, on projette les données sur les axes principaux d’inertie, et que ceux-ci sont ordonnés selon l’inertie du nuage projeté : de la plus grande à la plus petite.
Quand on additionne les inerties associées à tous les axes, on obtient l’inertie totale du nuage des individus.
On peut donc afficher un diagramme qui décrit le pourcentage d’inertie totale associé à chaque axe.
On appelle ce diagramme l’éboulis des valeurs propres. En voici un exemple :
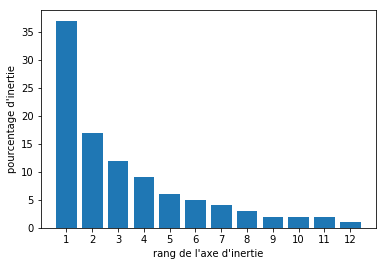
Pourquoi "valeurs propres" ?
Parce que les inerties portées par chaque axe sont égales aux valeurs propres de la matrice de covariance des données. Nous en avons parlé dans la section Allez plus loin de ce chapitre.
On peut également afficher la somme cumulée des inerties, c’est une courbe qui part de l’origine et qui arrive à 100 % après avoir parcouru tous les axes :
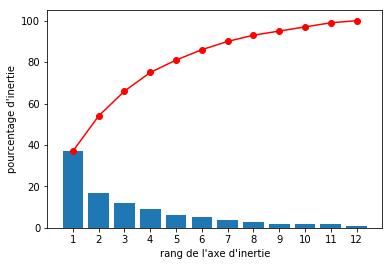
Comment interpréter ces pourcentages d’inertie ?
Les pourcentages d’inertie nous donnent une information sur la « structure » de nos données. Prenons les 2 cas extrêmes : des données sans aucune structure et des données très structurées.
Cas extrême 1
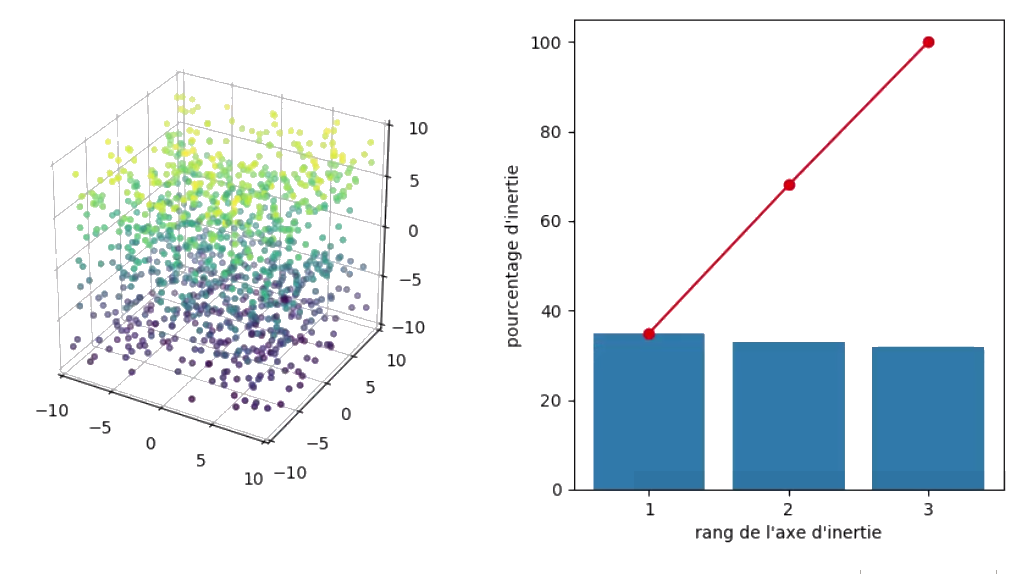
Un échantillon sans aucune structure est un échantillon pour lequel les variables n’ont aucune corrélation entre elles : elles sont toutes indépendantes deux à deux.
Ainsi, pour un individu donné, on ne peut absolument pas se faire une idée de la valeur d’une variable, même en connaissant la valeur de toutes les autres. C’est assez rare, car cela signifie que les caractéristiques (les variables) qui décrivent vos individus ne sont absolument pas liées entre elles ! Dans ce cas, l’inertie totale est équitablement répartie entre les axes, qui sont tous à pour cent de l’inertie totale.
Voici un exemple pour des données en 3 dimensions, où chaque axe est associé à (environ) 100/3 = 33 % de l'inertie totale :
Cas extrême 2
L’extrême inverse serait un échantillon pour lequel toutes les variables sont corrélées deux à deux avec un coefficient de corrélation de 1. Dans ce cas, pour un individu donné, il est possible de connaître avec exactitude la valeur d’une variable rien qu’en connaissant la valeur de n’importe quelle autre variable. C’est le cas où tous les points sont parfaitement alignés. Comme tous les points sont alignés, il n’y a besoin que d’un seul axe pour capter 100 % de l’inertie totale : il suffit de le placer dans l'alignement des points !
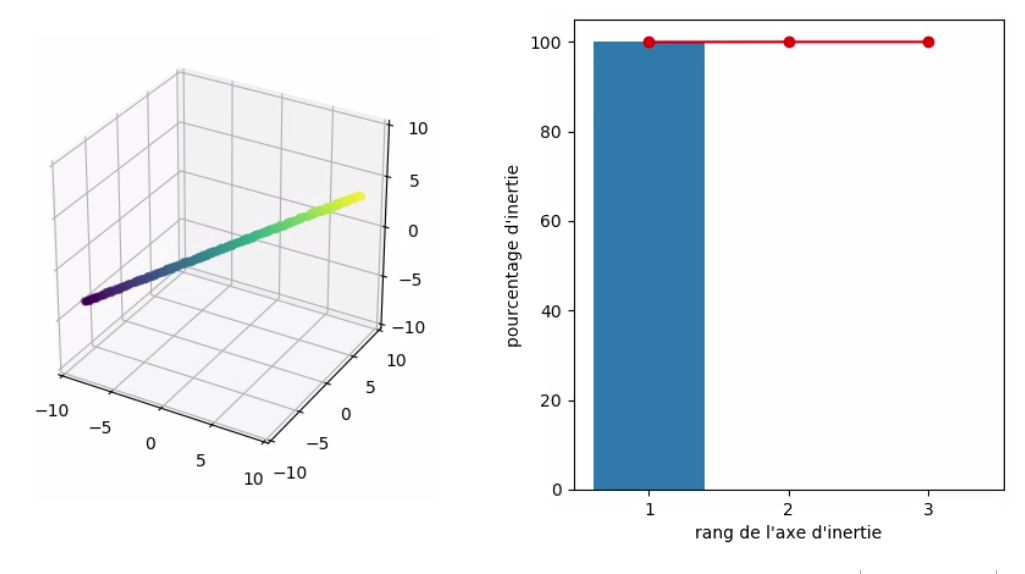
Ce second cas est idéal quand on veut réduire les dimensions, car on peut supprimer toutes nos variables initiales pour les remplacer par… une unique variable, sans perdre aucune information. Le rêve ! :soleil:
Ainsi, projeter le nuage des individus sur le premier plan factoriel, c’est bien, mais encore faut-il savoir si cette projection représente bien les données ou pas. Si 75 % de l’inertie totale sont associés à F1, et 25 % à F2, alors c’est parfait : le premier plan factoriel représente 100 % de l’inertie totale. La représentation est donc parfaite, pas besoin d’afficher F3, F4, etc., car ils ne contiendront aucune information (du coup, ils n’existent même pas).
Si, au contraire, on a des données en 10 dimensions, et que 20 % de l’inertie totale sont associés à F1, et 15 % à F2, le premier plan factoriel ne représente alors que 35 % de l’inertie totale. Si l'on considère que 35 % sont trop peu, alors on peut analyser les composantes suivantes (F3, etc.).
Combien de composantes analyser ?
Eh bien... il n’y a pas de réponse toute faite : tout dépend de vos objectifs et du contexte. Tout dépend jusqu’où vous souhaitez pousser votre analyse.
Cependant, voici quelques pistes.
Tout d’abord, on a tendance à ne pas considérer comme importants les axes dont l’inertie associée est inférieure à , car ils représentent moins de variabilité qu’une seule variable initiale. La valeur de est celle obtenue quand toutes les variables sont indépendantes deux à deux. Ce critère est appelé critère de Kaiser.
Ensuite, il existe la « méthode du coude » qui consiste à repérer l’endroit à partir duquel le pourcentage d’inertie diminue beaucoup plus lentement lorsque l’on parcourt le diagramme des éboulis de gauche à droite.
En pratique, on a plutôt tendance à s’arrêter dès que l’on n’arrive plus à interpréter les axes principaux d’inertie, c’est-à-dire quand on n’arrive plus à dire « le groupe de variables est très corrélé à , et il correspond à la notion de [...] ».
En pratique
Rassurez-vous, nous verrons cela dans le prochain chapitre ! :)
En résumé
Grace à l'ACP, on peut calculer le pourcentage de variance qui est captée par chaque axe.
En additionnant ces pourcentages, on obtient la variance cumulée dont la somme totale est 100 %.
La représentation graphique associée s'appelle l'éboulis des valeurs propres. C'est un graphique indispensable en ACP.
Il n'y a pas de règle générale sur le nombre de plans à analyser.
On applique toutefois souvent la méthode du coude pour établir ce nombre.
Il arrive souvent de n'analyser que les 1, 2 ou 3 premiers plans factoriels.
Passons par un exercice pour mettre tout cela en pratique ! Allez, hop !
