Représentez vos données dans un espace
La notion d'espace euclidien
Reprenons le graphique de dispersion d'un précédent chapitre :
Observons-le un peu. Sur celui-ci, on représente les individus par des points ayant chacun 2 coordonnées : une abscisse et une ordonnée. On dit donc ici que les données sont représentées dans un espace à 2 dimensions, car pour placer les points, on a sélectionné 2 des variables qui décrivent les individus. En quelque sorte, on a associé la notion de variable à celle de dimension.
Dans un espace euclidien, que veut dire le terme « euclidien » ?
Eh bien c'est très simple et très compliqué à la fois ! Disons pour faire simple qu'un espace euclidien c'est un espace « normal », c'est celui que vous utilisez au quotidien, celui que vous utilisiez quand vous faisiez de la géométrie au collège. C'est un espace dans lequel des droites parallèles ne se croisent pas, la somme des angles d'un triangle fait 180°, etc., etc.
Alors qu'est-ce qu'un espace non euclidien ? Eh bien par analogie, on pourrait dire que c'est un espace courbe, ou un espace « tordu ». Par exemple, si on dessine un triangle à la surface d'une sphère, la somme des angles des triangles ne fait plus 180°.
Rassurez-vous, pas besoin de maîtriser ces notions, mais sachez qu'elles sont utilisées dans des domaines très variés comme la cartographie, la physique, etc.
Vous n'avez pas forcément à savoir ce que c'est, mais retenez juste que c'est un espace dans lequel tous les objets sont des vecteurs.
Sur mon graphique de dispersion, il n’y a pas de vecteurs, il n’y a que des points !
Oui, c’est vrai. Mais on peut en fait considérer que chaque point est équivalent à un vecteur. Pour un point , par exemple, on dira qu’il est équivalent au vecteur , où est l’origine du repère (c'est-à-dire le point de coordonnées (0,0) dans un espace à 2 dimensions). Cette petite astuce nous permet d’utiliser toute la puissance de l’algèbre linéaire en statistiques : vous vous en rendrez rapidement compte dès les prochains chapitres ! Ainsi, dans la suite, on ne fera pas de distinction entre la notion de point et celle de vecteur, et on pourra noter indifféremment, comme ceci : , ou même .
Comment représenter un vecteur ?
Le plus souvent, on représente un vecteur en colonne. Pour le cas du point , qui a deux coordonnées (abscisse x et ordonnée y), on le note comme ceci :
Bon, mais si vecteur et point sont ici équivalents, et que l’on représente un individu par un point, cela veut dire que l’on peut aussi représenter un individu par un vecteur, n’est-ce pas ?
Tout à fait ! Si un individu est décrit par 4 variables, alors on peut le représenter par un vecteur à 4 dimensions.
Vous voyez poindre à l’horizon des espaces à plus de 2 dimensions ; il arrive régulièrement d’avoir des échantillons décrits par beaucoup de variables (parfois 100, 1 000 ou plus !). On préfère donc noter le vecteur X comme ceci :
Voilà, nous avons posé un peu le cadre : nous travaillons dans un espace vectoriel avec un nombre fini de dimensions (2, 4, 100, 1 000 ou beaucoup plus), où chaque individu est représenté par un vecteur, ce vecteur ayant autant de dimensions que l’espace vectoriel en question.
Si maintenant on rajoute la contrainte que chaque composante d’un vecteur doit être un nombre réel, et que l’on associe à cet espace vectoriel un produit scalaire, alors on dit que l’on travaille dans un espace euclidien.
« On associe à cet espace un produit scalaire », cela veut dire quoi ?
Un produit scalaire est une opération algébrique entre 2 vecteurs. Dans notre cas, cette opération associe à 2 vecteurs un nombre réel.
Dire que l’on « associe » un produit scalaire à un espace vectoriel signifie que l’on va souvent utiliser celui-ci dans les calculs que nous effectuerons : c'est ce produit scalaire qui permettra de calculer des distances, des longueurs, des projections et des angles.
La notion de distance
Si je vous demande la distance entre 2 points A et B sur un graphique à 2 dimensions comme celui ci-dessous, qu’allez-vous faire ?
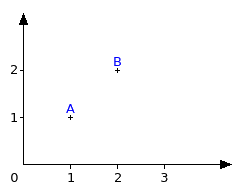
Certains seront allés chercher une règle graduée pour mesurer, d’autres auront été plus aventuriers et auront calculé la distance à partir des coordonnées des 2 points. Mais, dans les 2 cas, vous obtiendrez tous le même résultat (ici, , soit environ 1.41).
La distance euclidienne fait référence, notamment, au fameux théorème de Pythagore. On l'apprend au collège dans un espace à deux dimensions, mais il peut s'appliquer à des espaces à 3, 4... ou 1 000 dimensions !
Retenez que quand on parle de « distance », sans spécifier quelle distance, on parle en général de distance euclidienne.
Tu sous-entends qu’il y a plusieurs types de distances ?
Tout à fait. Mais vous le savez déjà, sans vous en rendre compte. Quand dans une ville, vous demandez à quelle distance se trouve un bâtiment donné, on vous répondra soit avec une distance « à vol d’oiseau », soit avec une distance en suivant les rues (car vous ne pouvez pas voler, je pense). En mathématiques, c’est un peu le même principe : il y a plusieurs types de distances. Pour reprendre l’exemple de la ville, sachez qu’il existe par exemple la distance de Manhattan.
Voici un exemple de distance de Manhattan :
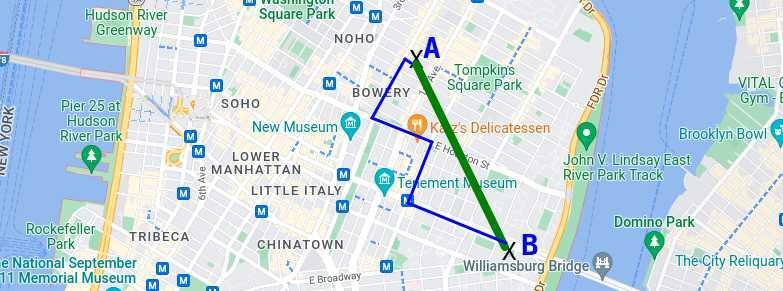
Le plus court chemin entre A et B est bien la distance « à vol d'oiseau » (en vert), mais il n'est possible réellement qu'en hélicoptère... Dans les faits, on se déplace plus souvent à pied, en voiture ou en moto ! Le plus court chemin entre A et B, dans ces conditions, correspond à la distance de Manhattan.
Eh oui, vous utilisez cette distance depuis fort longtemps, sans même le savoir. :)
Il existe aussi une distance qui calcule des proximités entre des mots (plus généralement des chaînes de caractères) : c’est la distance de Levenshtein, selon laquelle la distance entre « Bonjour » et « Bonsoir » est de 2.
La notion de nuage de points
Lorsque l’on représente les individus d’un échantillon par des points dans un espace euclidien, l’ensemble de ces points est appelé nuage de points. Poétique, non ? Comme durant les après-midi d’été, allongés sur l’herbe, où nous regardons les nuages dans le ciel. Vous avez d’ailleurs sûrement déjà joué à ce jeu : essayer de comparer la forme des nuages à des animaux ou à d’autres objets connus.
En statistiques, on fait la même chose, on décrit des nuages de points : Quelle forme ont-ils ? Sont-ils étalés, resserrés, denses, gros, petits ? Quelle est leur position ?
Un nuage étalé dans l’espace traduira par exemple des individus très différents les uns des autres. Peut-être y a-t-il des amas dans un nuage, c’est-à-dire des zones plus denses que d’autres. Dans ce cas, cela signifie qu’il y a des groupes d’individus similaires entre eux, et plutôt différents des autres groupes.
La notion d’inertie
Comme nous étudions la dispersion d’un nuage (étalé ou resserré), nous avons besoin d’une notion qui définit ce concept : c’est la notion d’inertie.
La notion d’inertie est similaire à celle que rencontrent nos amis physiciens lorsqu’ils étudient le mouvement des objets (cette discipline s’appelle la mécanique) : un objet avec une forte inertie est un objet difficile à mettre en mouvement, ou à faire entrer en rotation.
Si vous avez deux objets de même masse, mais pas de même taille, l’objet qui sera plus grand (donc plus étalé dans l’espace) sera plus difficile à faire tourner autour de son centre de gravité.
Nous avons déjà vu ce parallèle en statistique descriptive monodimensionnelle quand nous avons parlé des moments empiriques et des moments d’inertie. L’un des moments que nous avons étudiés était la variance.
Pour une variable donnée, la variance empirique est calculée à partir de la somme des carrés des distances entre les observations et leur moyenne. Cela, c’est pour une variable, c’est-à-dire pour un nuage de points à 1 dimension. La généralisation de ce concept à un nuage de points à dimensions nous donne l’inertie du nuage de points . Ainsi, l’inertie de est la moyenne des carrés des distances entre les points et leur centre de gravité . On note la distance entre le point et comme ceci : .
L'inertie totale de par rapport à est donc égale à :
Plus le nuage sera dispersé (étalé), plus son inertie sera grande. Nous avons déjà vu cette notion de dispersion avec la variance empirique, que nous avons qualifiée d’indicateur de dispersion. D’ailleurs, l’inertie du nuage de points est aussi la somme des variances sur toutes les dimensions :
En pratique
Pour la partie code, c'est très simple, définissons 2 vecteurs :
v1 = [12, 3, 12, 8, 12, 5]
v2 = [-42, 3, 12, 80, 1, 78]Calculons leurs moyennes :
v1_mean = sum(v1)/len(v1)
v2_mean = sum(v2)/len(v2)Calculons les variances :
v1_var = sum([abs(i-v1_mean)**2 for i in v1]) / len(v1)
v2_var = sum([abs(i-v2_mean)**2 for i in v2]) / len(v2)Nous avons :
print(v1_var)
print(v2_var)13.222222222222221 1916.3333333333333
Notons que certaines librairies commenumpy ou pandas peuvent grandement nous aider :
import numpy as np
print(np.var(v1))13.222222222222221
En résumé
Dans un tableau à 8 colonnes, chaque ligne peut être considérée comme un vecteur, et chaque colonne comme une dimension.
Chaque ligne peut donc être assimilée à un point dans un espace. Cet espace peut avoir 1, 2, 3 ou... 10 000 dimensions.
L'espace « classique » que nous connaissons à un nom : espace euclidien.
L'espace euclidien définit un certain nombre d'opérations sur les vecteurs. Ces opérations sont dites « scalaires ».
On peut calculer des distances entres des points mais aussi entre des vecteurs, notamment la distance euclidienne.
La notion d'inertie fait référence à la dispersion des points dans un espace à 1, 2, 3 ou 10 000 dimensions.
Plus l'inertie d'un nuage de points, ou l'inertie d'un groupe de vecteurs est forte, plus il sera « difficile » d'appliquer des transformations sur cet espace.
Cette inertie est en fait très liée au concept de variance.
C'est terminé pour cette première partie du cours ! Passez par le quiz avant de me retrouver en partie 2 !
