Découvrez les mesures de tendance centrale
Imaginons la situation suivante : vous devez vous rendre en voiture à un entretien d'embauche, loin de chez vous, dans une autre ville que la vôtre. Vous vous demandez à quelle heure il faut partir pour arriver là-bas à 15 h. Comme vous avez beaucoup de choses à faire le matin, vous ne souhaitez pas partir trop tôt, mais vous voulez quand même être sûr d'être à l'heure.
Le trajet que vous devrez faire, vous le connaissez peu. Mais heureusement, l'un de vos amis le parcourt tous les jours, et il connaît la route par cœur.
Vous lui demandez donc :
Combien de temps dure le trajet entre les deux villes ? Il vous répond : Tout dépend si la circulation est bonne ou pas. La plupart du temps, je mets entre 40 min et 45 min.
Penchons-nous sur cette phrase. Votre ami a l'habitude du trajet : il l'a parcouru peut-être 1 000 fois ! À chaque fois, il a retenu (plus ou moins inconsciemment) le temps de trajet. Nous avons donc ici un échantillon de taille 1 000, avec une variable quantitative continue : le temps de trajet entre les 2 villes.
Même si le temps de ce trajet peut en théorie prendre des valeurs comprises entre 0 et l'infini, vous vous doutez bien qu'elles se concentrent quand même autour d'une certaine valeur. Ce que vous souhaitez savoir ici, c'est avoir un ordre d'idée d'où (sur un axe de 0 à l'infini) se concentrent les valeurs des temps de trajet.
Tu emploies le terme se concentrent. Dans concentrer, il y a le mot centre, non ?
Tout à fait ! Nous arrivons donc à l'objet de ce chapitre : les mesures de tendance centrale. Nous allons en voir 3, et devinez quoi : elles commencent toutes par un M !
Découvrez les mesures de tendance centrale
Le mode
La plupart du temps, je mets entre 40 et 45 min.
Quand votre ami vous dit cela, il vous donne une mesure de tendance centrale qui s'appelle le mode.
Pour les variables qualitatives, ou pour les variables quantitatives discrètes, le mode est la modalité ou la valeur la plus fréquente. Dans notre relevé bancaire, le mode de la variable categ est "Autre", car la modalité "Autre" est présente 212 fois dans l'échantillon, et toutes les autres modalités ("loyer", "courses", etc.) sont présentes moins de fois.
Pour les variables quantitatives continues, on travaille dans le cas agrégé, en regroupant les valeurs par classes. La classe modale est la classe la plus fréquente. Votre ami a découpé sa variable en tranches de 5 minutes, et a déterminé que la tranche la plus fréquente était .
En Python, le calcul du mode tient en une ligne. Voici un exemple avec la variable montant :
data['montant'].mode()Cette méthode renvoie un pd.Series, car une distribution peut avoir plusieurs modes.
La moyenne
Vous répondez donc à votre ami : Oui, mais je ne peux pas me contenter de la durée la plus fréquente : car si la deuxième durée la plus fréquente est de 65 à 70 minutes, il faut que je parte beaucoup plus tôt ! Il répond alors :
Oui, tu as raison. En fait je mets en moyenne 60 minutes par trajet, car il y a souvent des embouteillages.
Cela change tout : heureusement que vous lui avez demandé de préciser, vous seriez arrivé en retard ! Ici, votre ami vous a répondu en termes de moyenne.
La moyenne, vous la connaissez tous. Pour calculer la moyenne de valeurs, on additionne celles-ci, puis on divise le résultat par le nombre de valeurs.
Il est courant d'associer la notion de moyenne à la notion d'équilibre et de centre de gravité. Pourquoi ? Imaginez que vous ayez 10 valeurs numériques. Vous prenez un bâton, que vous graduez. Sur cette graduation, vous marquez au feutre l'emplacement de vos 10 valeurs, puis vous fixez au bâton une balle sur chacune des 10 marques. Après avoir calculé la moyenne des 10 valeurs, vous l'inscrivez également sur votre bâton. Si vous souhaitez faire tenir votre bâton en équilibre, à l'horizontale, il vous faudra trouver son centre de gravité. Vous me voyez venir : le centre de gravité sera pile-poil là où vous aurez placé la moyenne des 10 valeurs !
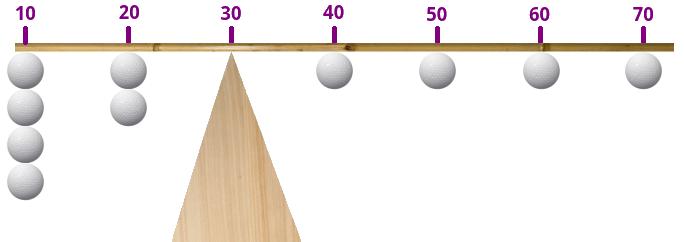
Voici comment calculer la moyenne des montants dépensés :
data['montant'].mean()Oui mais sur notre bâton... si l'une des valeurs est très différente des autres, sa balle sera très éloignée des autres sur le bâton, et ce dernier sera totalement déséquilibré, juste à cause d'une seule valeur !
La médiane
Derrière le problème de bâton déséquilibré, vous aurez reconnu le concept d'outlier. Comme nous venons de le voir, la moyenne est une mesure peu robuste aux outliers.
Alors, à propos de votre trajet à parcourir, vous demandez à votre ami : Quand tu me dis que tu mets en moyenne 60 min, j'imagine que tu considères dans ton calcul les rares fois durant lesquelles il y avait de la neige, et que tu as mis 4 h à faire la route ? Ce sont des outliers, autant ne pas les prendre en compte car c'est l'été, et il n'y aura pas de neige ! Ce à quoi il vous répond :
Oui effectivement. Je vais alors formuler la chose autrement : disons que la moitié des trajets que j'ai effectués ont pris plus de 55 min, et ceux l'autre moitié ont pris moins de 55 min.
Ici, votre ami vous parle en termes de médiane.
La médiane, (notée Med), est la valeur telle que le nombre d’observations supérieures à cette valeur est égal au nombre d’observations inférieures à cette valeur.
En gros, pour trouver la médiane de vos valeurs, il faut commencer par les trier. Une fois triées, on appelle la première valeur, la deuxième valeur, ... , et la dernière valeur. La médiane, c'est la valeur qui sera exactement au milieu du classement, soit :
Ainsi, sur trajets, la médiane est = 55 min.
Votre calcul marche bien car 999 est impair. Mais s'il y a 1 000 trajets, la médiane est-elle la 500e valeur ou la 501e valeur ? Si on choisit la 500e, alors il y a 499 valeurs en dessous et 500 valeurs au-dessus. Mais si on choisit la 501e, alors il y a 500 valeurs en dessous et 499 valeurs au-dessus : dans les 2 cas, c'est déséquilibré !
Effectivement. Dans ce cas, on coupe la poire en deux : on place la médiane au centre de la 500e et de la 501e valeur. Ainsi, s'il y a eu 1 000 trajets, et que la 500e valeur vaut = 54 min 30 sec, et que la 501e vaut = 55 min 30 sec, alors on coupe en deux et on prend 55 min.
Plus formellement, si est pair, la médiane vaut :
Voilà comment calculer la médiane des montants :
data['montant'].median()Observer ces mesures sur un histogramme
Sur un histogramme, le mode est le "point le plus haut" de la distribution, la médiane est la valeur qui divise la surface en deux et la moyenne est le centre de gravité de la distribution, comme sur cette illustration :

À vous de jouer

Analysons un peu plus en détail notre variable montant.
Les montants des opérations sont très hétérogènes : il y a des dépenses (à montant négatif) parfois grosses (les loyers, par exemple), souvent petites (courses, téléphone, etc.), et il y a des rentrées d'argent (à montant positif), peu fréquentes mais grosses. Difficile donc d'interpréter la moyenne (très sensible aux valeurs atypiques) qui vaut ici 2,87 €.
On a le même problème pour la médiane qui vaut -9,6 €. Le fait qu'elle soit négative nous indique cependant qu'il y a plus de dépenses que d'entrées d'argent. Par contre, le mode nous indique que la plupart des opérations tournent autour de -1,6 €. Ici, les 3 mesures sont très éloignées les unes des autres.
Pour avoir des montants d'opérations plus homogènes, il serait intéressant de calculer ces mesures pour chaque catégorie d'opération : les montants devraient être moins éparpillés au sein d'une catégorie puisque les opérations sont de même nature. Je vous laisse le faire en Python. Vous pouvez réaliser cela via une boucle for, qui itérera sur chacune des catégories. Ne vous arrêtez cependant pas uniquement au code, essayez d'en tirer une dimension analytique : quelle interprétation pouvez-vous faire des résultats ?
En résumé
Les mesures de tendance centrale permettent d'avoir une idée de la valeur autour de laquelle se concentrent l'ensemble de nos valeurs.
Le mode est la modalité ou la valeur la plus fréquente dans une variable qualitative ou quantitative discrète. On parlera de classe modale avec une variable quantitative continue.
La moyenne est la valeur correspondant au centre de gravité de l'ensemble des valeurs d'une variable quantitative.
La moyenne, de par son calcul, est une mesure particulièrement sensible aux outliers.
La médiane est la valeur telle que le nombre d’observations supérieures à cette valeur est égal au nombre d’observations inférieures à cette valeur.
Et si les valeurs dans votre analyse sont très écartées ? o_O Dans le prochain chapitre, nous découvrirons les mesures de dispersion !
