Découvrez le neurone formel
Dans ce chapitre, nous allons découvrir les origines du neurone formel et apprendre à l'utiliser et l'entraîner.
Le neurone biologique
Les réseaux de neurones artificiels ou RNN sont des modèles mathématiques inspirés de la biologie. La brique de base de ces réseaux, le neurone artificiel, était issu au départ d'une volonté de modélisation du fonctionnement d'un neurone biologique. Regardons donc comment fonctionne un neurone in vivo.
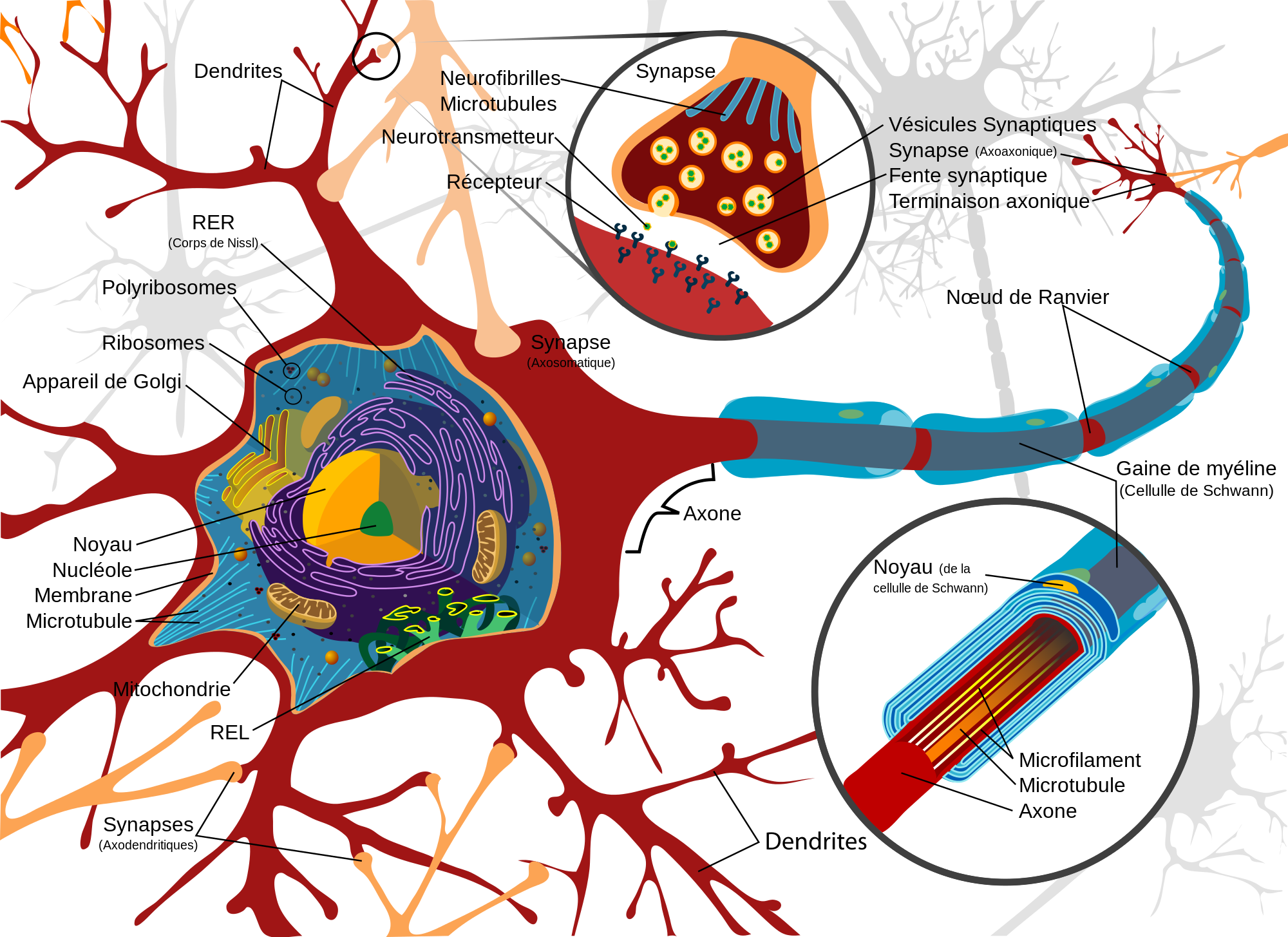
Schématiquement, on peut décomposer le neurone en 3 grandes entités :
un corps cellulaire, appelé péricaryon ;
un ensemble de dendrites (de l'ordre de 7 000) ;
un axone.
Lorsque l'excitation du corps cellulaire dépasse un certain seuil, un afflux nerveux est émis le long de l'axone de façon centrifuge, c'est-à-dire du corps cellulaire à l'extrémité de l'axone. La quantification de l'excitation se fait par modulation de fréquence. Plus le neurone est excité, plus rapprochées sont les impulsions dans l'axone.
L'extrémité de l'axone peut être en contact avec une dendrite d'un autre neurone. La zone de contact est appelée synapse. Elle permet la transmission de l'information d'un neurone à un autre.
Un réseau est ainsi formé.
Le neurone formel
Le perceptron, encore appelé neurone artificiel ou neurone formel, cherche à reproduire le fonctionnement d'un neurone biologique. Il existe différents niveaux d'abstraction, suivant la précision de la modélisation voulue.
Dans notre cas, nous n'allons pas chercher à reproduire exactement et exhaustivement tous les processus biologiques en œuvre dans un neurone biologique. Il s'agit d'une version simplifiée.
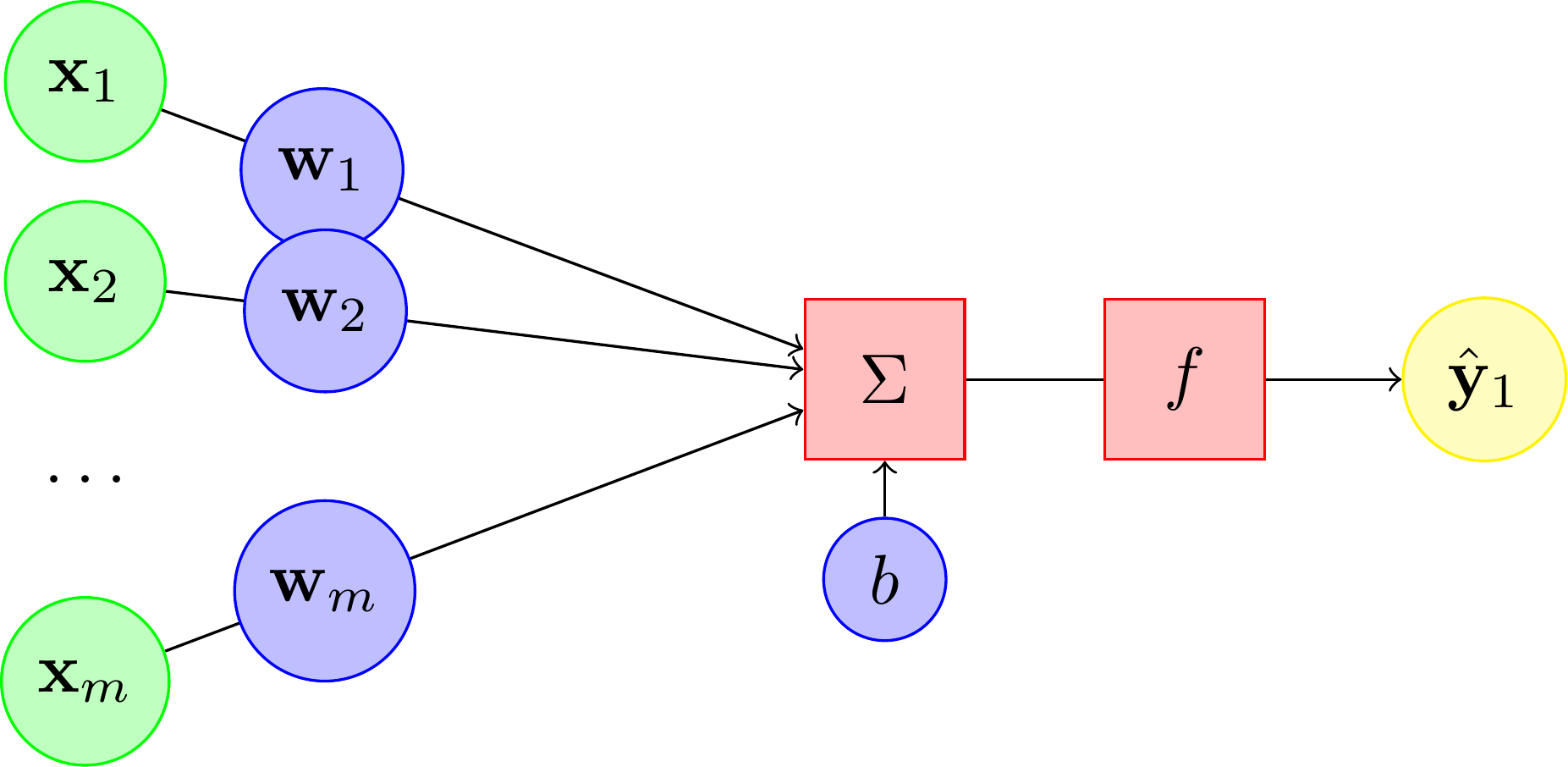
Nous allons considérer les entités suivantes :
des entrées, notées sous formes de vecteurs, représentant les dendrites ;
une sortie, notée , représentant l'axone ;
des paramètres, notés et , influençant le fonctionnement du neurone.
Équation d'un neurone formel :
Cette équation dit comment la sortie est calculée. Chaque entrée est multipliée par un poids, un coefficient . Toutes les entrées sont alors sommées et additionnées à un biais . Le résultat de la somme passe à travers une fonction de transfert (le plus souvent non linéaire). Cette fonction produit alors la sortie voulue.
On le voit, plus les entrées sont grandes en valeur absolue, plus la somme peut être grande en valeur absolue. Nous sommes donc en modulation d'amplitude (et non plus de fréquence, comme dans un neurone biologique).
Exemple sur une séparation linéaire
Regardons ce qu'il se passe pour un exemple simple.
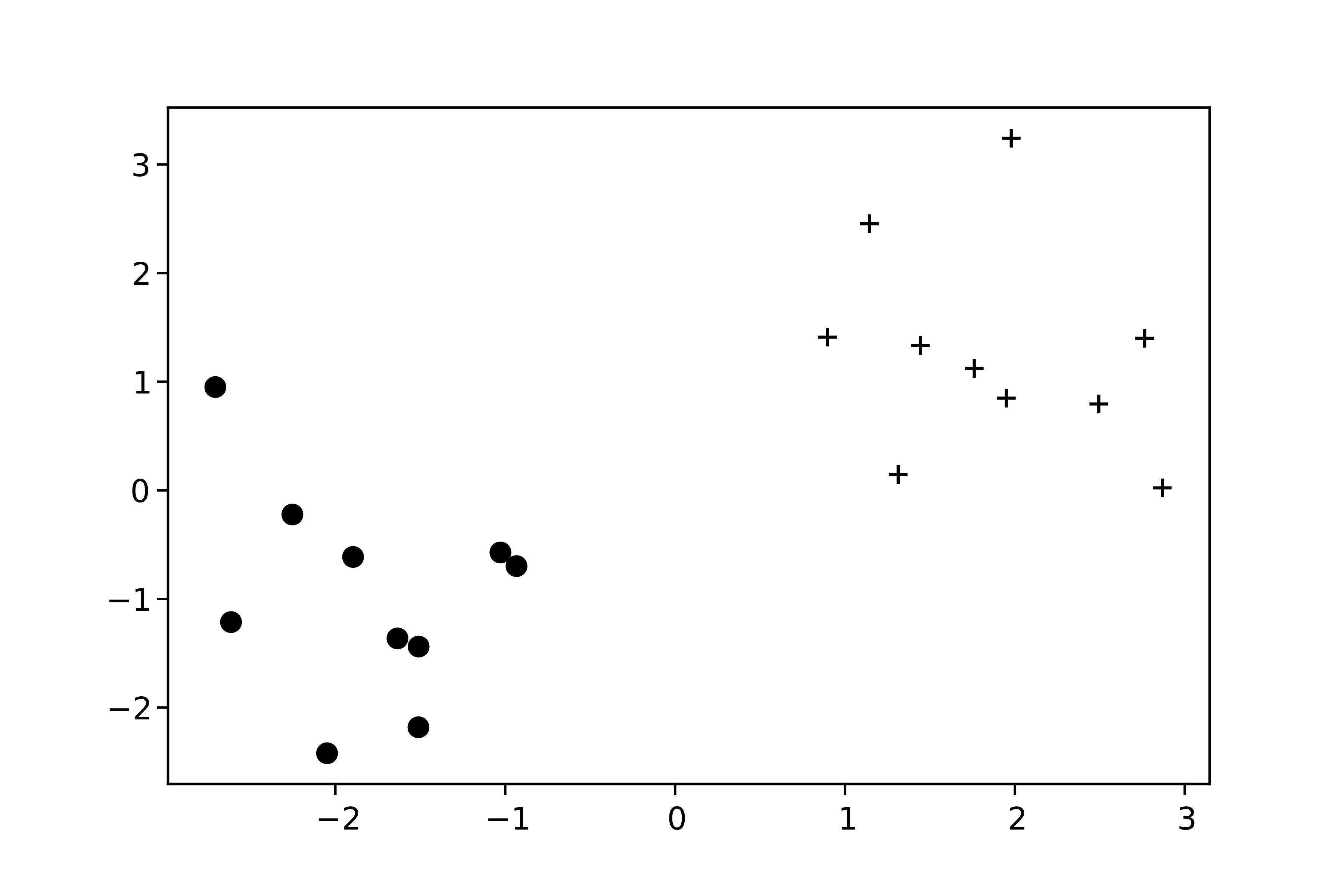
Nous cherchons à classer ces points en deux camps.
Voici les paramètres d'un neurone adapté à ce problème :
Pour
0.985 | 2.186 |
Pour
-0.522 |
On va appliquer l'équation du neurone sur quelques exemples. Les deux premières colonnes du tableau suivant montrent les coordonnées de l'exemple, la dernière colonne montre le résultat de l'application de l'équation du neurone.
|
|
|
0.896 | 1.410 | 3.445 |
-1.509 | -1.438 | -5.155 |
1.443 | 1.333 | 3.816 |
-1.895 | -0.613 | -3.731 |
-2.048 | -2.420 | -7.833 |
Si on trace la droite qui sépare les exemples avec un résultat positif et avec un résultat négatif, on obtient la figure suivante :
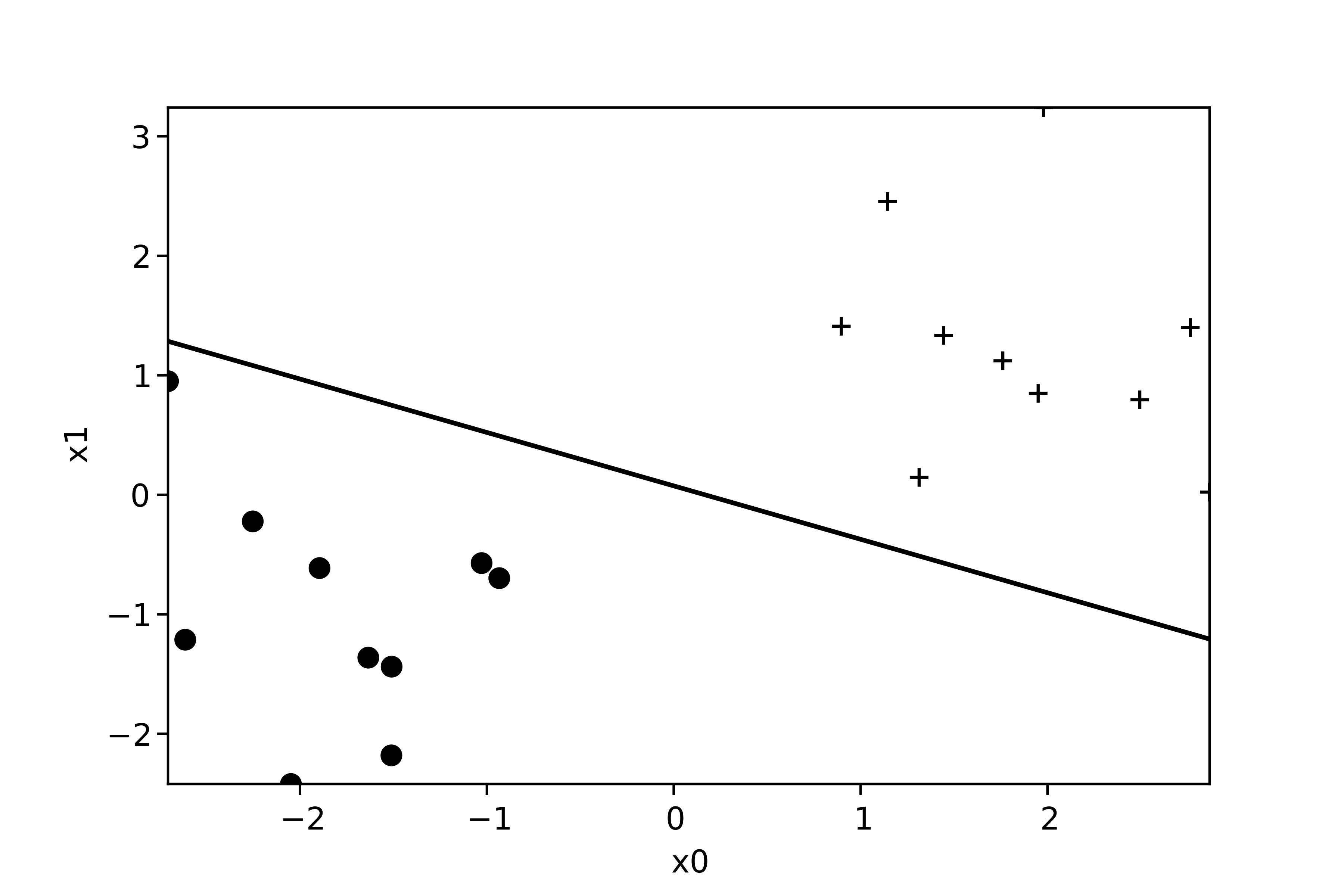
Nous constatons que le neurone a réussi à séparer les exemples en deux camps.
Mais comment trouver les bons paramètres pour être capable de faire cela ?
Cette étape s'appelle l'apprentissage. Nous allons voir comment cela fonctionne pour un neurone simple.
Apprentissage par descente de gradient
L'apprentissage d'un neurone se fait par optimisation d'une fonction de perte. C'est-à-dire que l'on va chercher les paramètres et , qui minimisent la fonction de perte. Dans le cas de la classification, on va utiliser la log-vraisemblance négative.
Quand tout est dérivable, on peut utiliser la descente de gradient.
À chaque étape, les paramètres sont déplacés de la manière suivante :
Voici comment vont évoluer les paramètres pour l'exemple précédent.
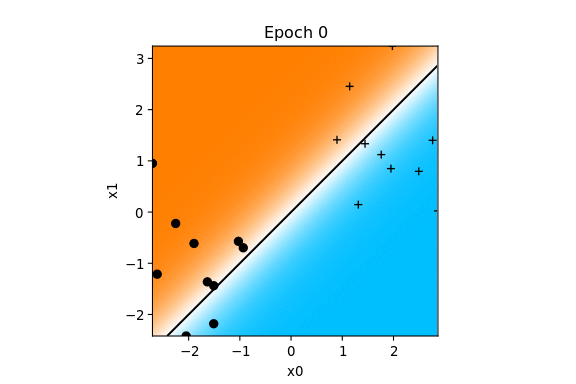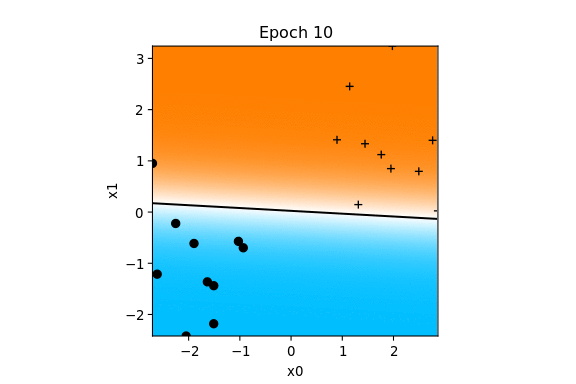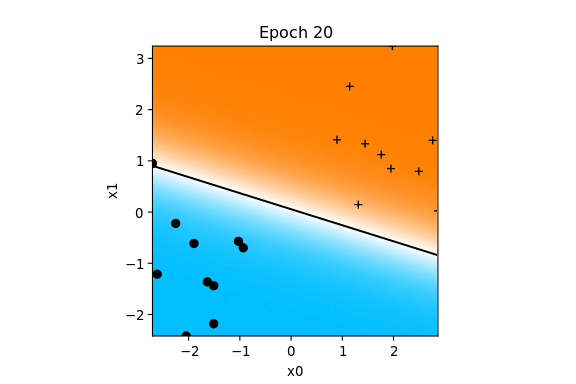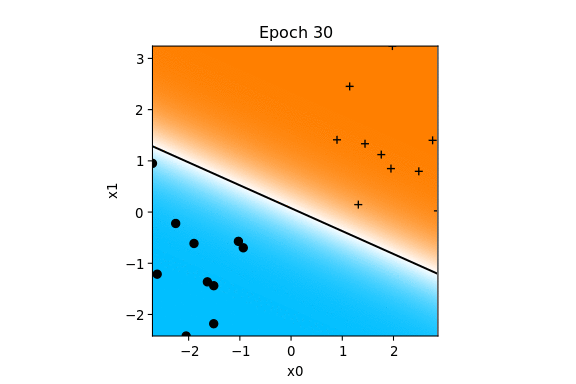
La zone cyan représente la partie négative, la zone magenta la partie positive de la fonction de décision.
Allez plus loin
Article sur le Perceptron.
La Plus Belle Histoire de l'intelligence, Des origines aux neurones artificiels : vers une nouvelle étape de l'évolution. Stanislas DEHAENE, Yann LE CUN, Jacques GIRARDON. Collection : La Plus Belle Histoire. Date de parution : 18/10/2018 chez Robert Laffont.
En résumé
Dans ce chapitre, nous avons vu comment un neurone formel ou neurone artificiel est inspiré d'un neurone biologique. Puis à partir d'un modèle dérivable et d'un ensemble de données linéairement séparables, nous avons vu comment apprendre les paramètres d'un neurone par descente de gradient.
