Initiez-vous aux autoencodeurs
Dans ce chapitre, nous allons comprendre l’architecture et quelques applications des autoencodeurs. Ensuite nous allons apprendre à différencier un réseau standard et un réseau profond. Finalement, nous allons identifier les contraintes liées aux réseaux profonds et savoir utiliser des AE pour les construire.
Dans cette partie, nous allons observer un type de réseaux adaptés à une tâche d'apprentissage non supervisée.
Nous sommes en apprentissage non supervisé ; nous ne traiterons donc que des caractéristiques d'un exemple, et nous n'avons pas accès à son étiquette si elle existe.
Nous allons essayer de faire de la réduction de dimension, c'est-à-dire projeter une base d'exemples de grande dimension dans un espace de plus petite dimension. Par exemple, pour en faire une visualisation.
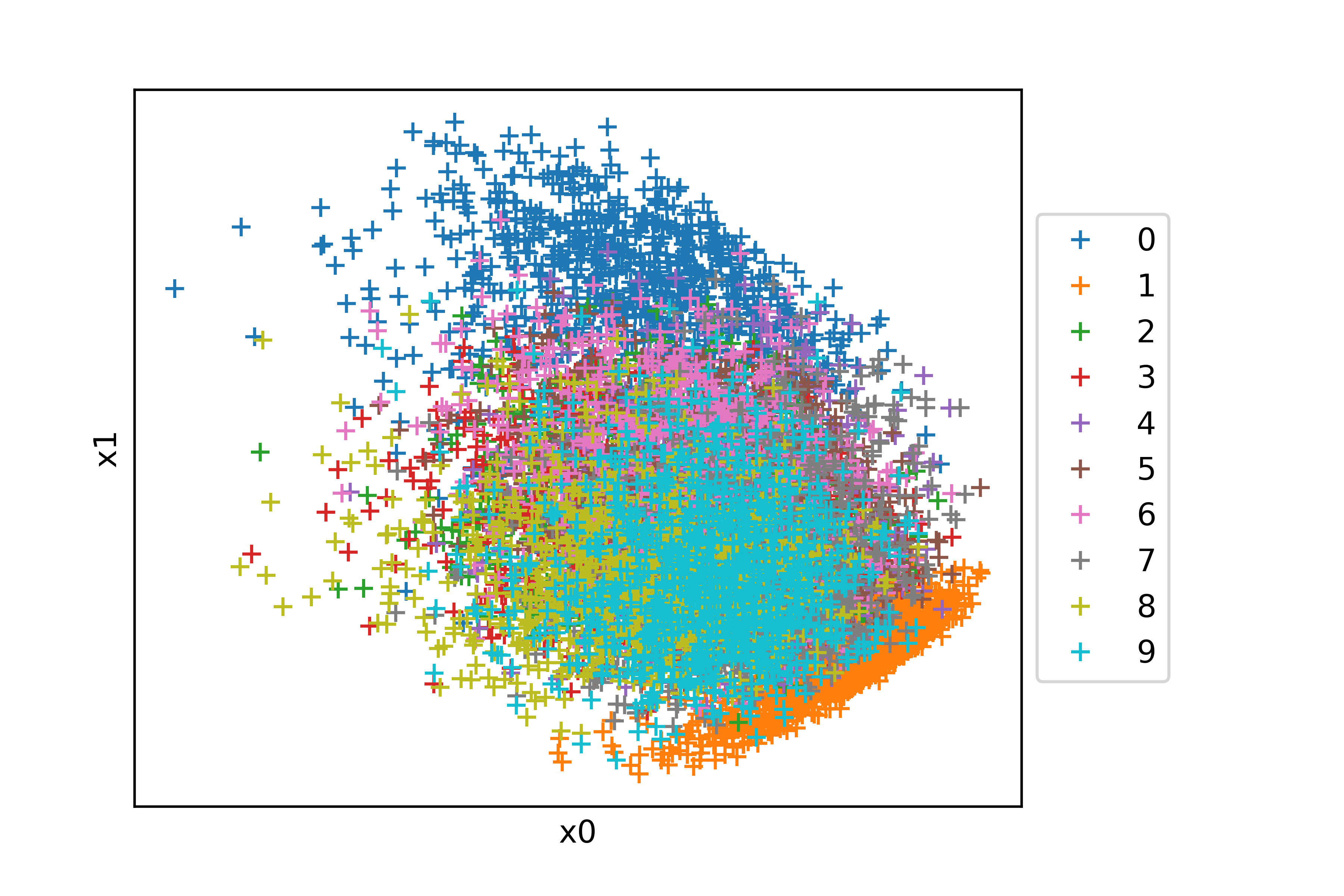
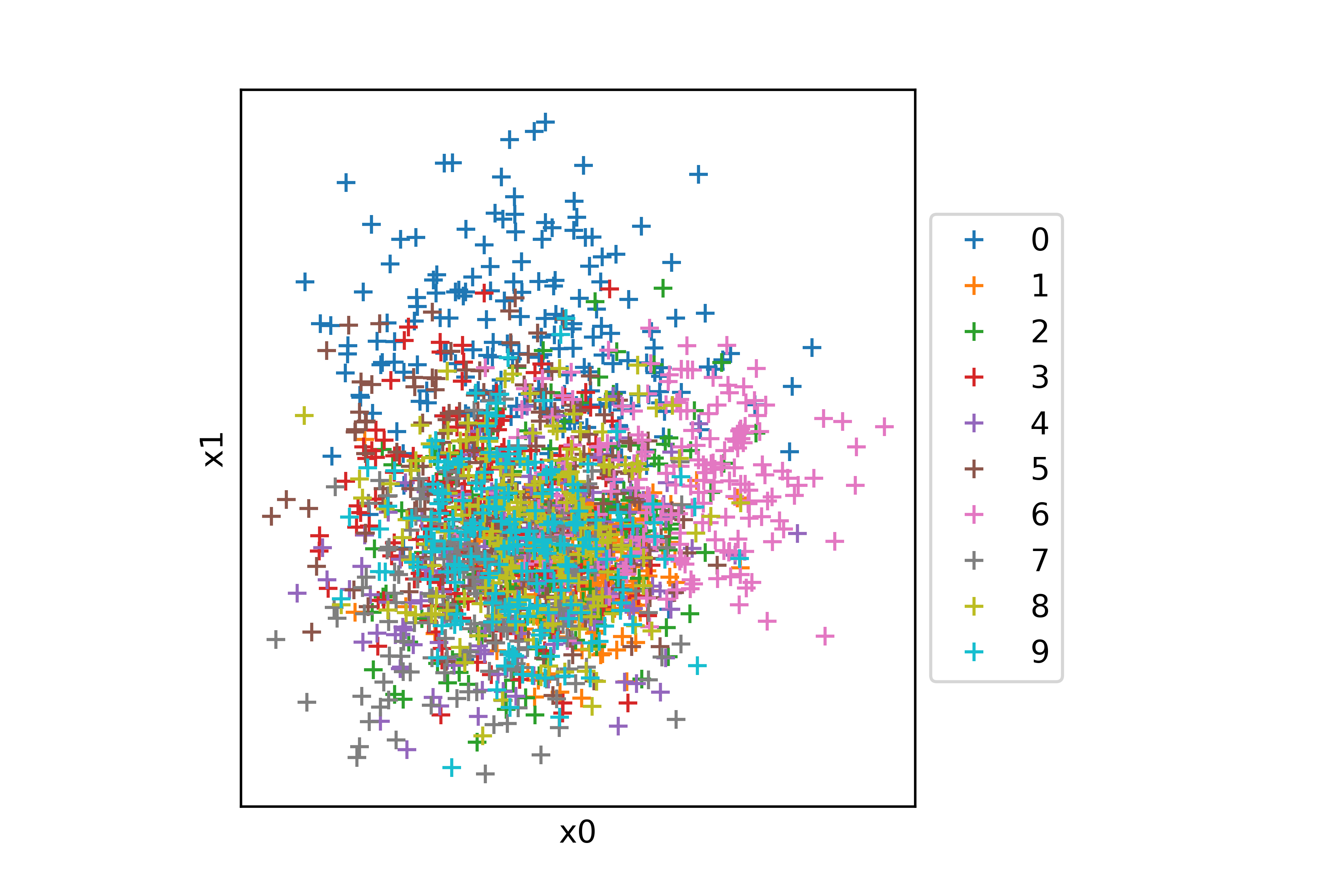
Prenons comme illustration les imagettes de chiffres de la base MNIST.
Dans le SPOC d'Initiation au Machine Learning, vous avez vu comment les représenter en 2D grâce à de l'analyse en composante principale (ACP). Voilà ce que cela donne sur MNIST :
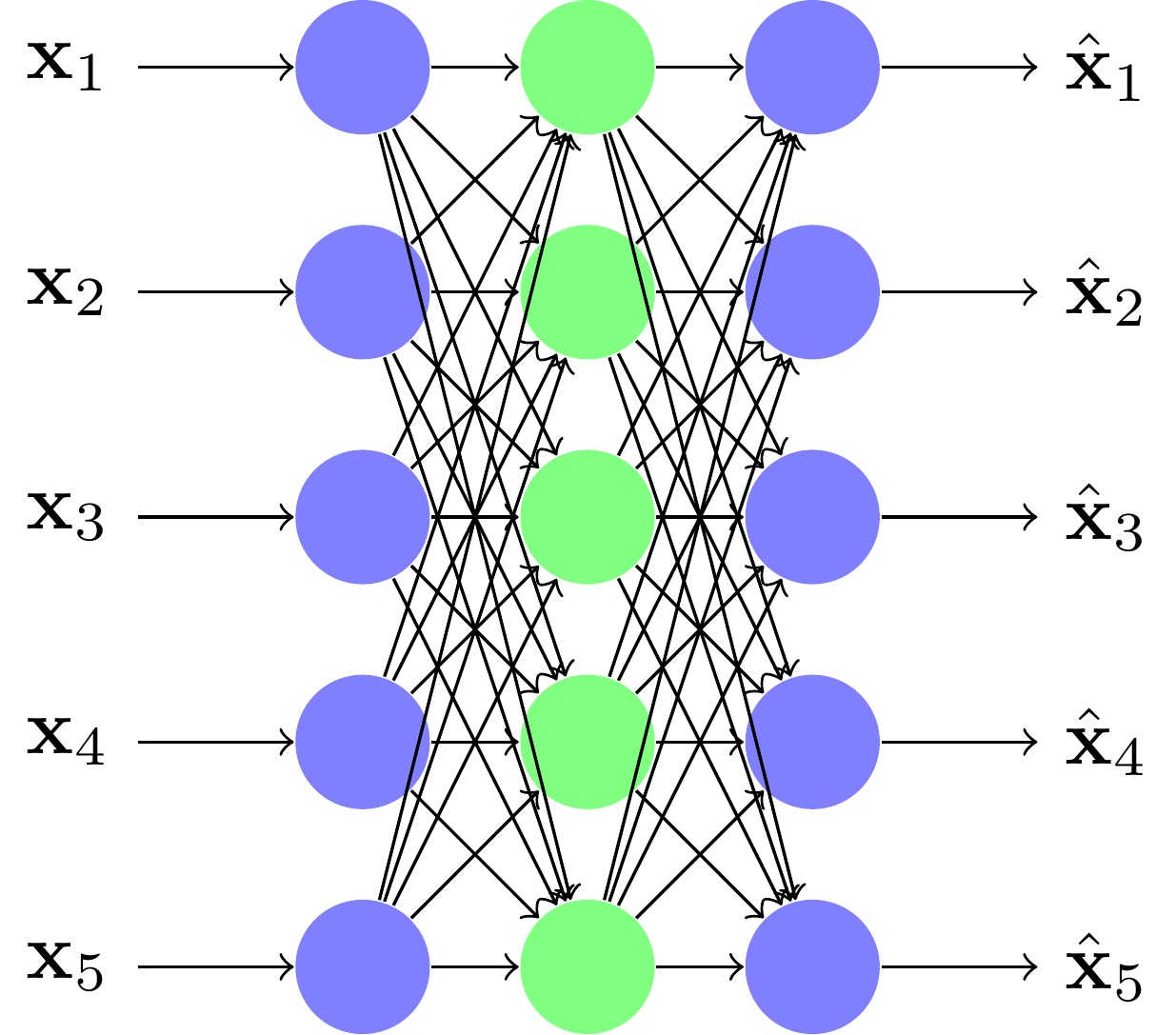
Architecture diabolo
Pour ce faire, nous pouvons utiliser l'architecture suivante :
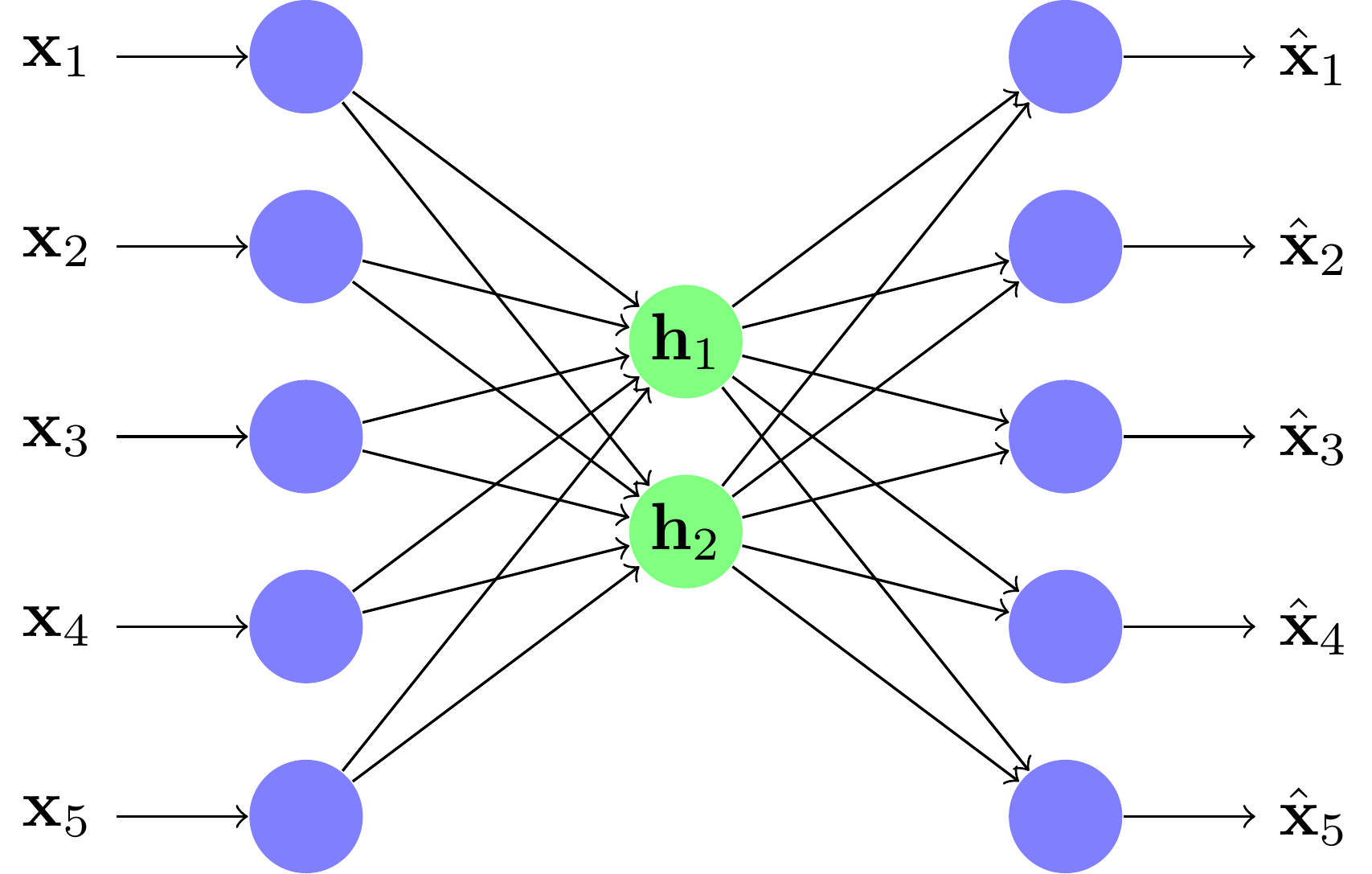
On appelle cela une architecture diabolo, car elle prend la forme de l'instrument de jonglage dit diabolo. En effet, elle possède un centre resserré, avec des entrées et des sorties élargies.
Compression/décompression de données
Cette architecture peut être décomposée en deux parties :
un encodeur qui prend les données en grande dimension et les compresse vers une plus petite dimension :
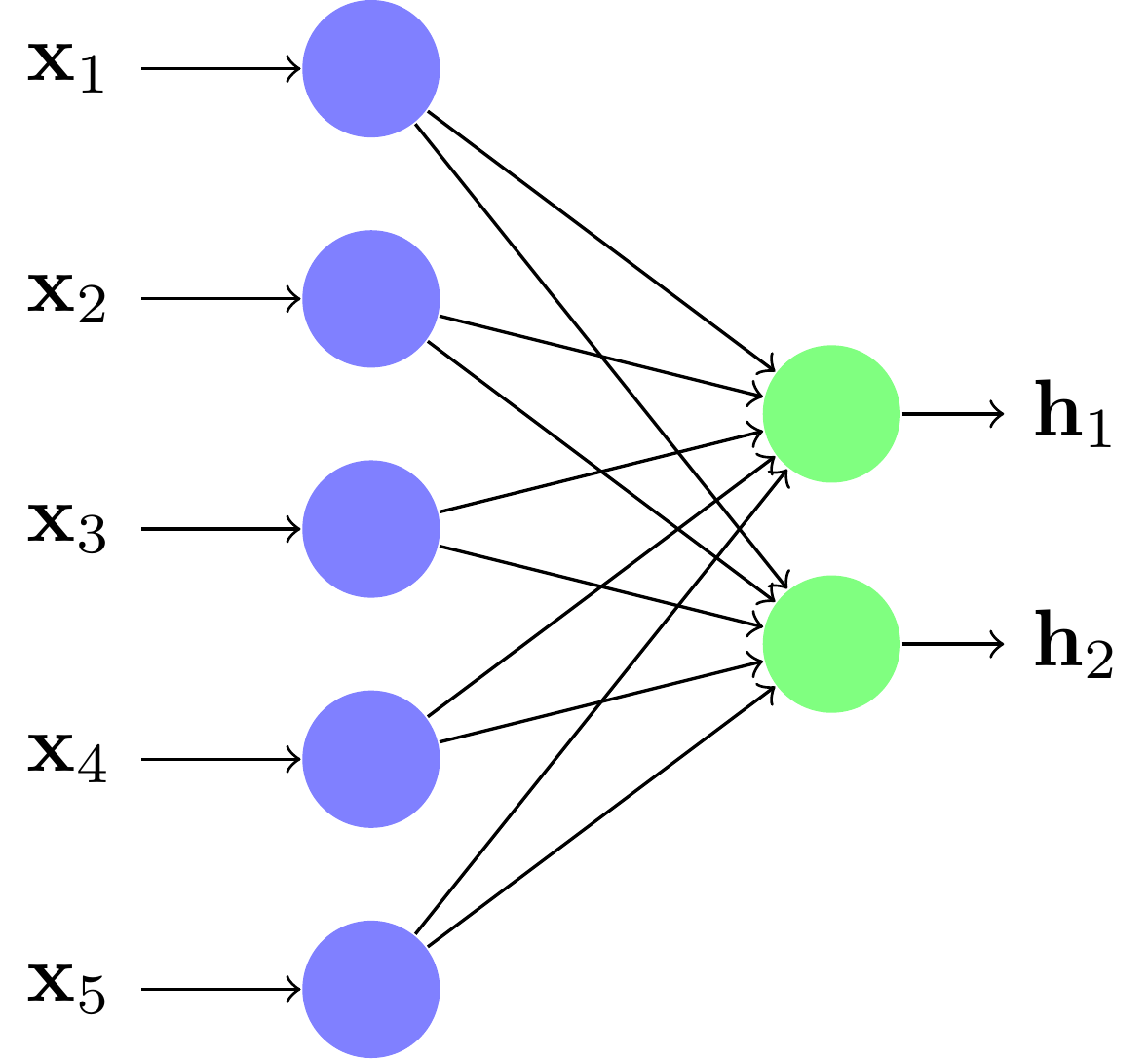
un décodeur qui prend les données en petite dimension et les rétroprojette vers la plus grande dimension :
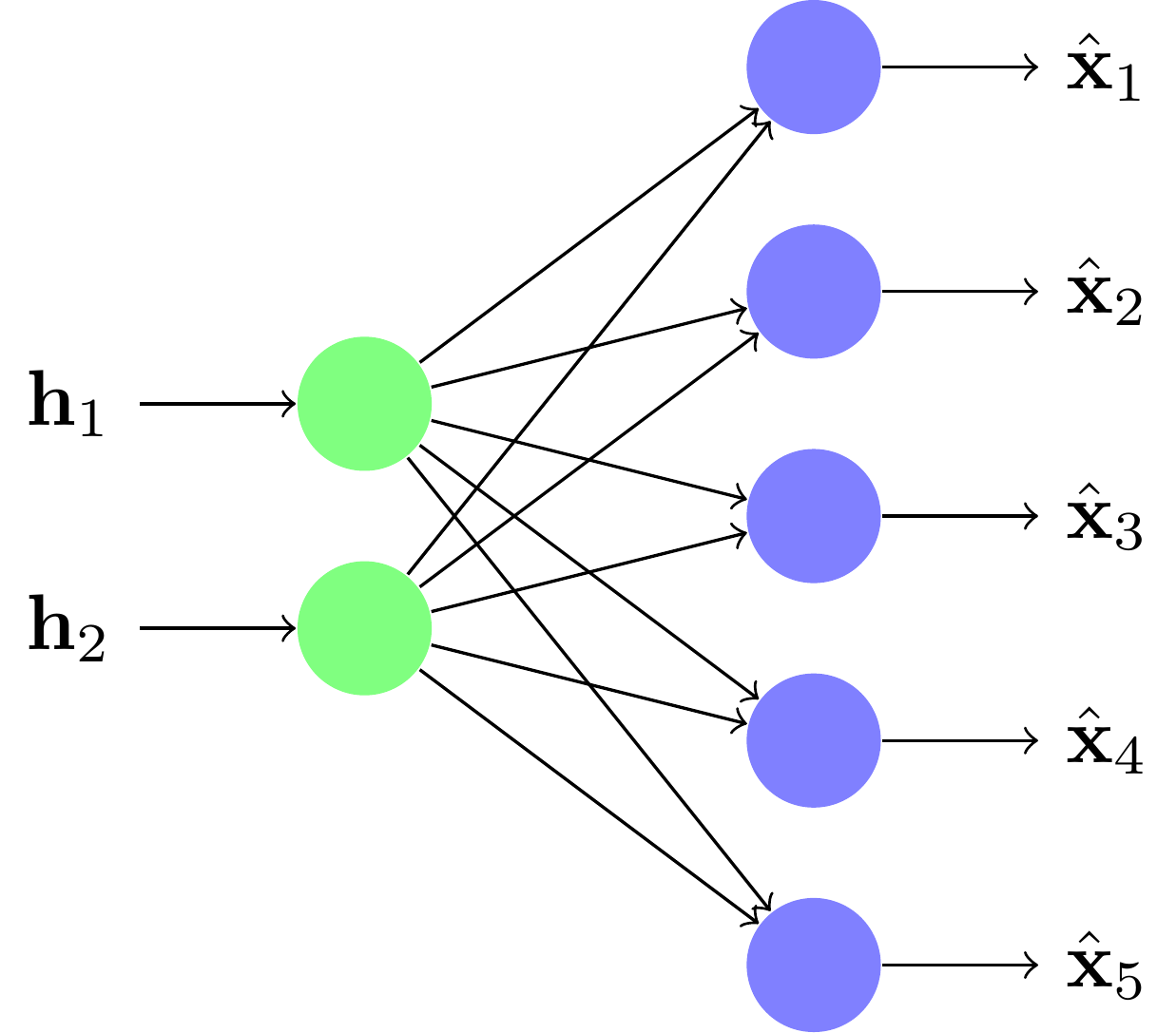
La valeur centrale est appelée le code ; elle est censée contenir l'information de l'entrée de manière compressée. Ainsi, on appelle aussi un diabolo un auto encodeur (AE). Pour simplifier les illustrations, nous ne montrons ici que des réseaux diabolos à deux couches : une pour l'encodeur, une pour le décodeur. Cependant, chacune de ces parties peut avoir un nombre de couches quelconque.
Apprentissage autoencoder
L'apprentissage de l'autoencodeur (autoencoder en anglais) se fait par rétropropagation du gradient. Il s'agit tout simplement d'un réseau dont la cible est l'entrée elle-même.
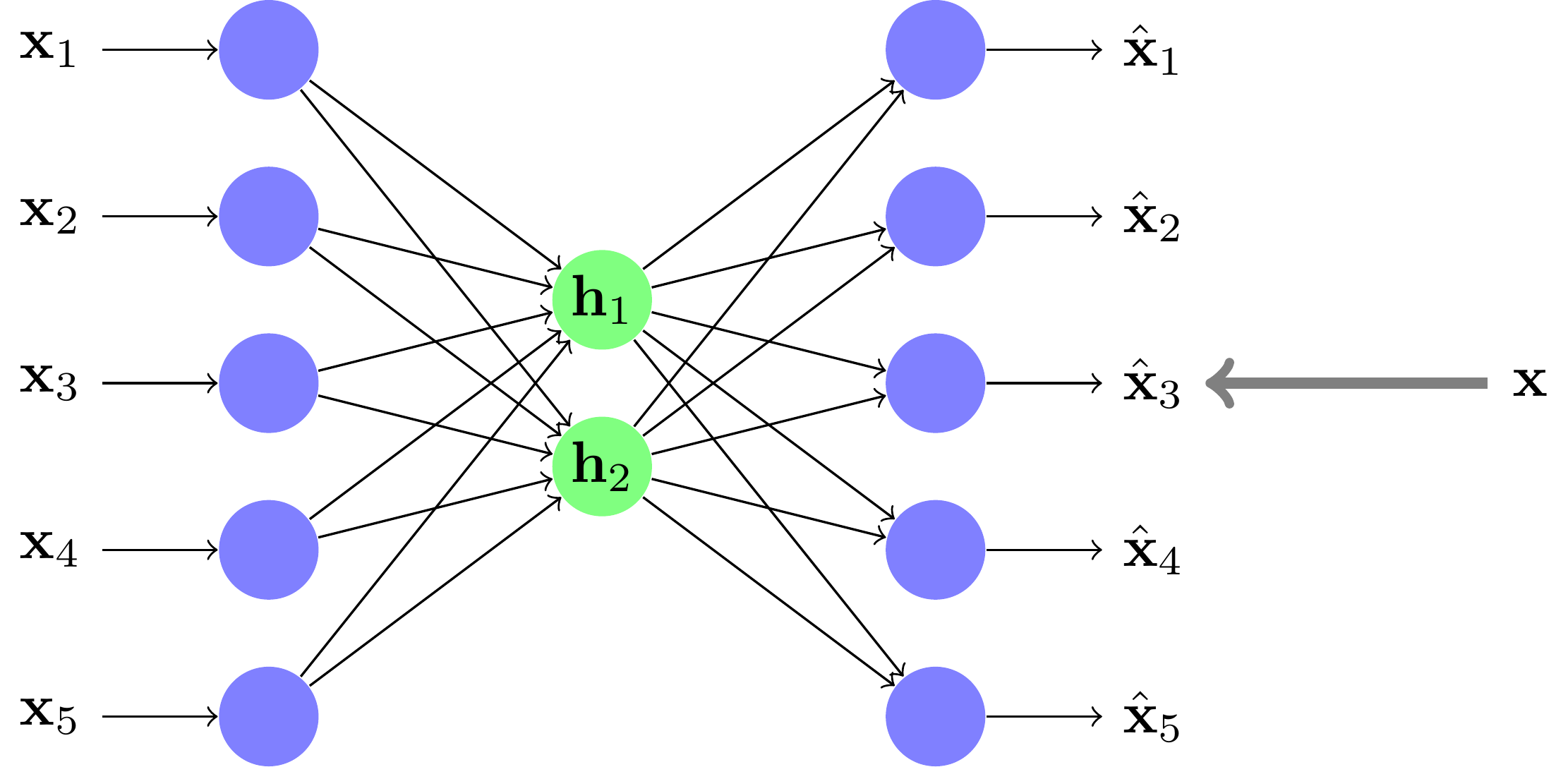
Under/over complete
En fait, il existe deux types d'autoencodeur :
les under-complete sont ceux dont les unités centrales sont en plus petit nombre que les unités d'entrée ; ils effectuent une réduction de dimension, comme vu précédemment ;
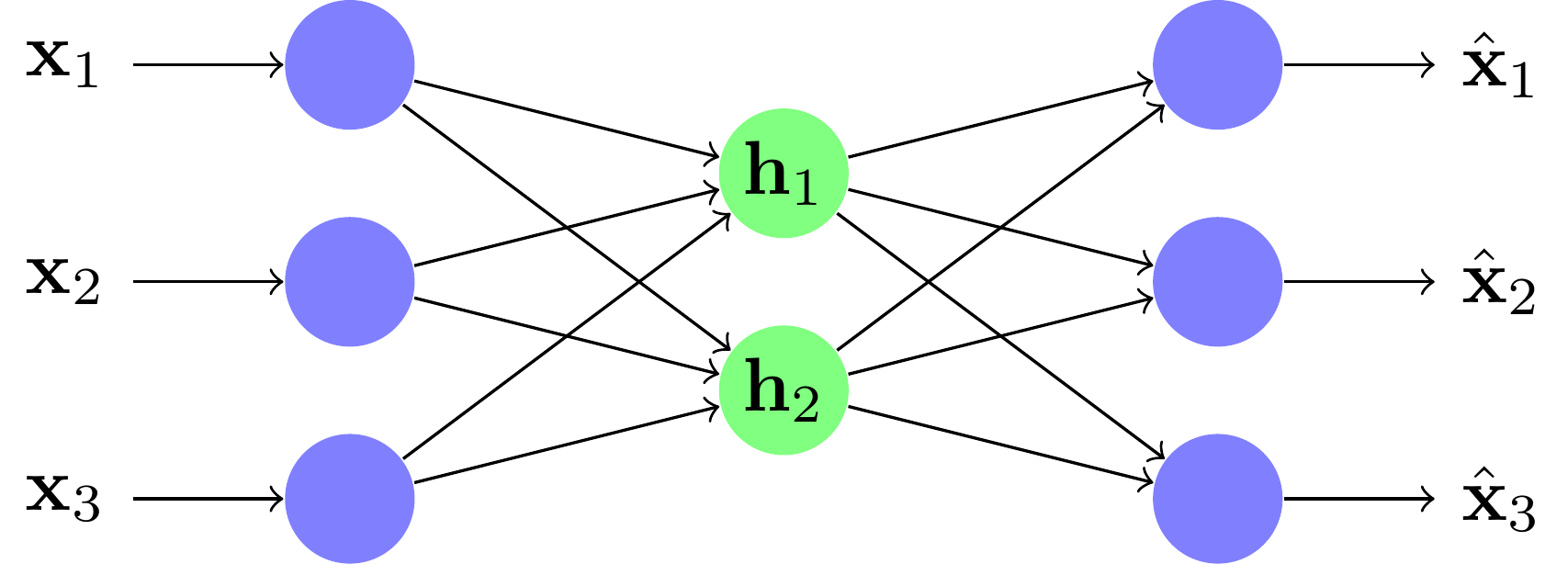
Un exemple de réseau under-complete les over-complete sont ceux dont les unités centrales sont en plus grand nombre que les unités d'entrée ; ils cherchent, eux, une meilleure représentation des données pour un traitement ultérieur (cela correspond à la projection dans une plus grande dimension des SVM) .
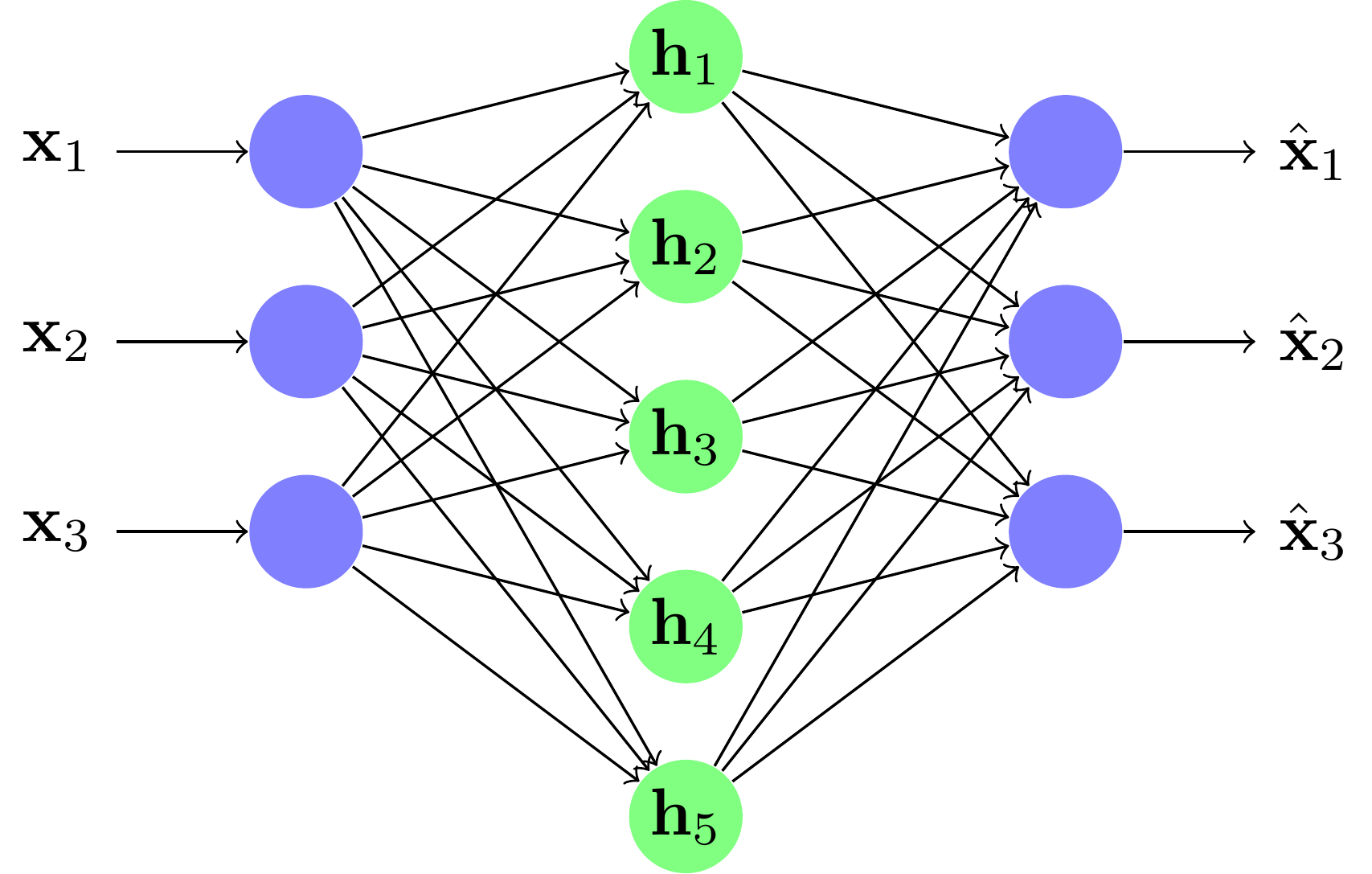
Un exemple de réseau over-complete
Nous constatons que chacun a ses particularités d'apprentissage.
Débruitage avec les autoencodeurs (under-complete)
On peut améliorer l'apprentissage des AE under-complete en rajoutant des perturbations à l'entrée (comme du bruit, mais aussi comme des transformations).
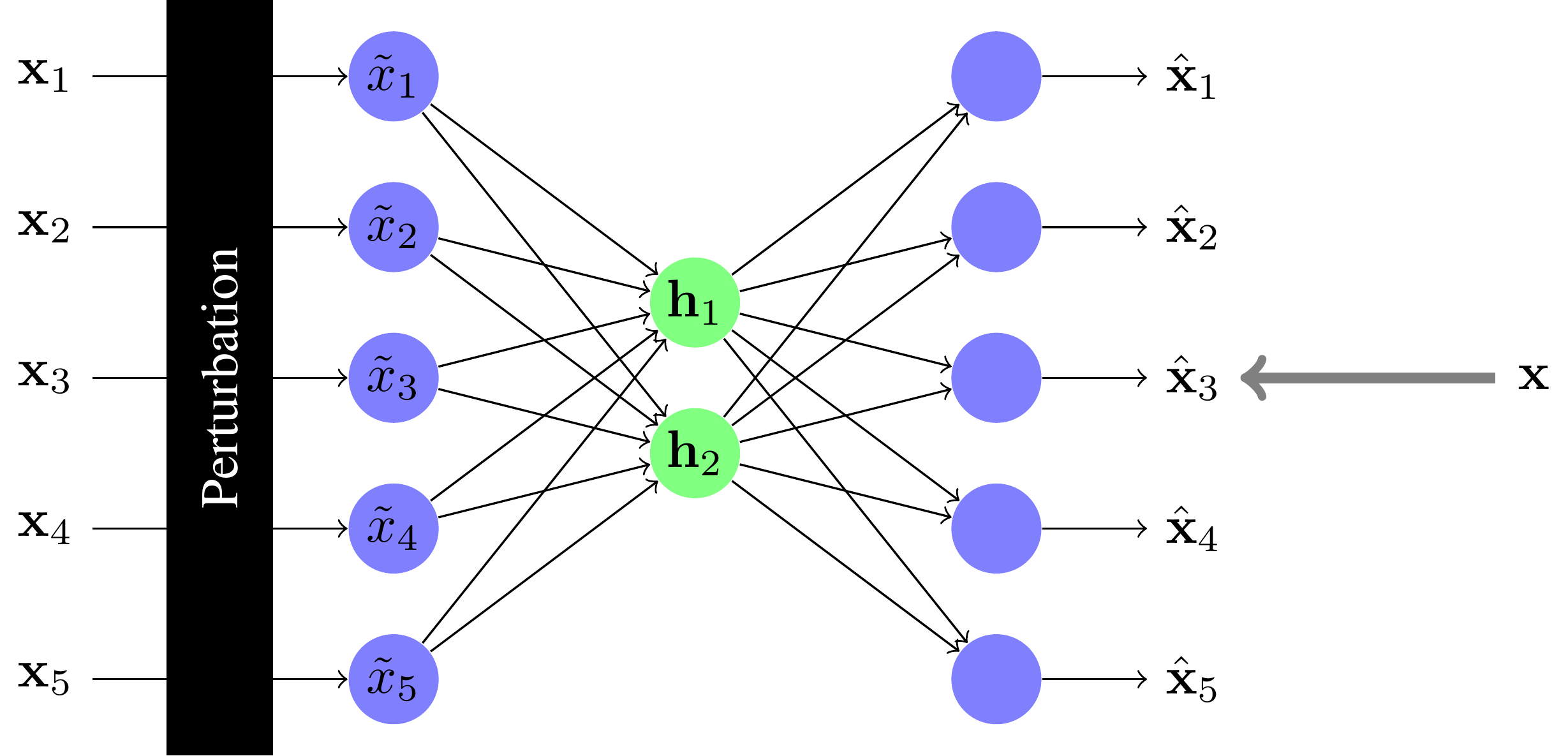
En fait, cela revient à faire de la régularisation.
Prévenir la coadaptation sur les autoencodeurs (over-complete)
Pour les autoencodeurs over-complete, l'apprentissage est plus complexe. On peut vite tomber sur des solutions triviales où le réseau se contente de recopier l'information de couche en couche. Pour éviter cela, on va déconnecter aléatoirement des neurones de la représentation intermédiaire.
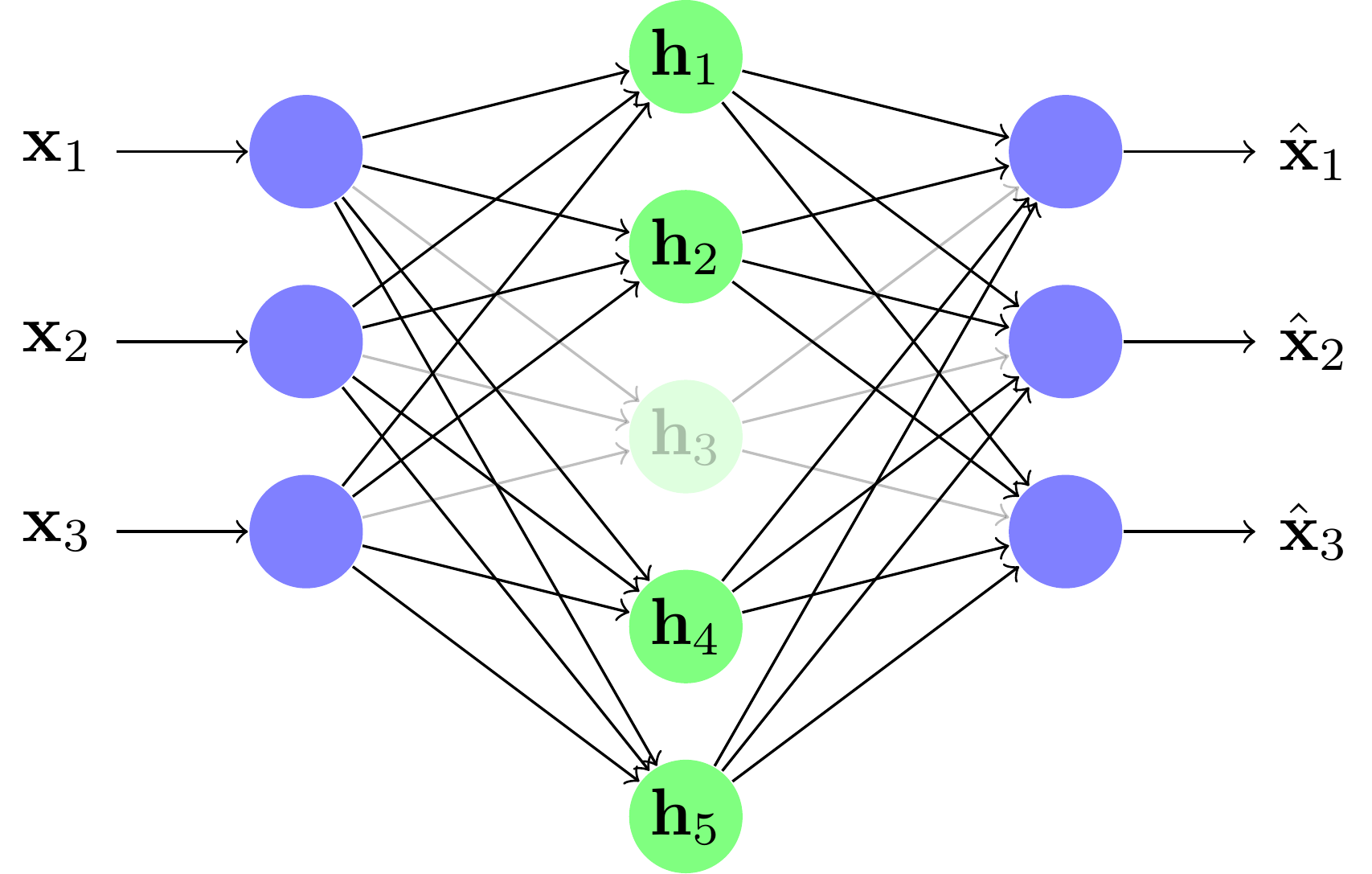
Exemple sur une base de caractères
Voici un exemple sur la base de caractères MNIST :
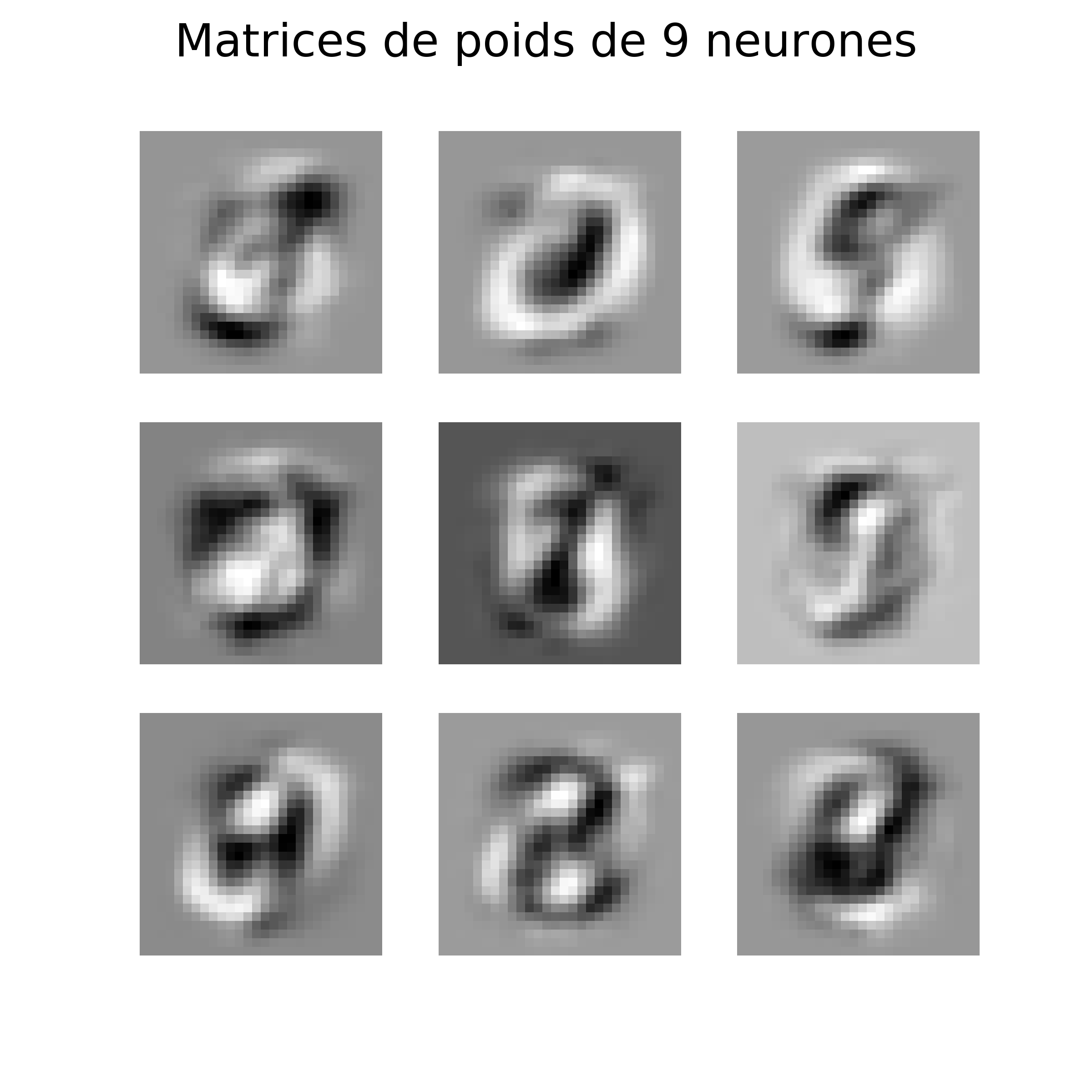
Que voit-on ?
Le réseau a appris des filtres typiques pour qualifier les caractères.
Ce qui correspond à de l'extraction de caractéristiques. Cependant, cette extraction n'a pas été fixée à la main à l'avance par des connaissances a priori, mais apprise/adaptée à la base fournie grâce à l'apprentissage de l'AE.
Ne serait-il pas intéressant d'utiliser cette propriété aussi pour l'apprentissage supervisé ?
Cela s'appelle l'apprentissage profond, ou deep learning en anglais.
Réseaux profonds (données brutes vs caractéristiques)
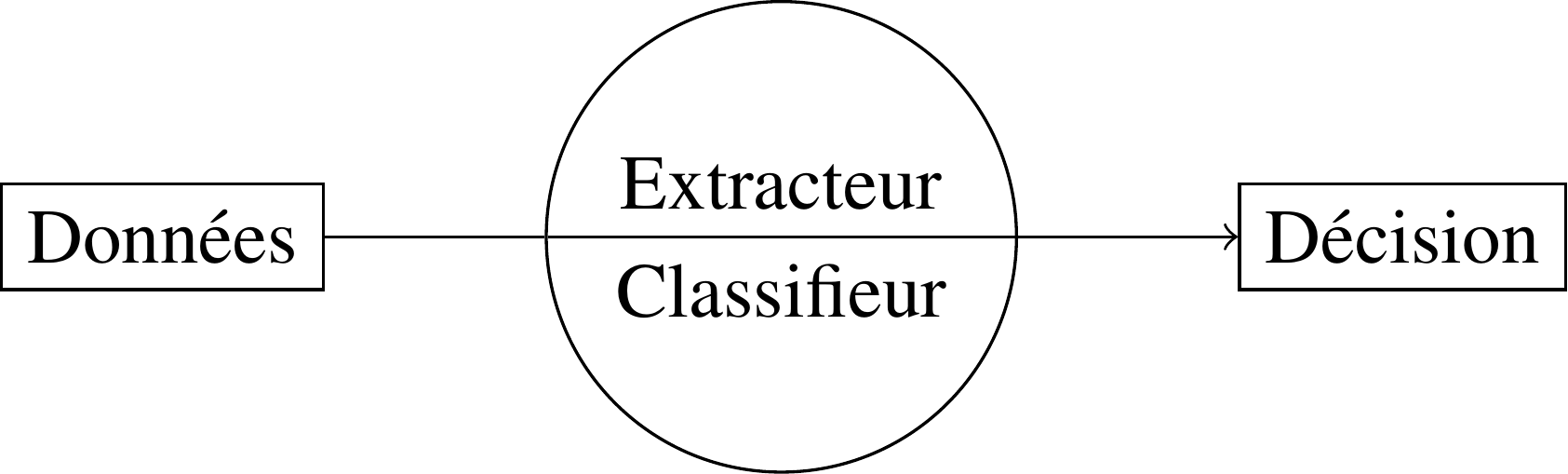
Dans un apprentissage supervisé classique, on extrait d'abord des caractéristiques des données brutes (comme par exemple un histogramme sur une image), puis on passe ces caractéristiques à un classifieur :

Seule la dernière phase est apprise de façon supervisée ; l'extraction de caractéristiques est statique.
Dans un apprentissage profond, on va directement travailler sur les données brutes. La phase d'extraction des caractéristiques est elle aussi apprise, et n'est plus statique.
Exemple de construction de réseaux profonds grâce aux autoencodeurs
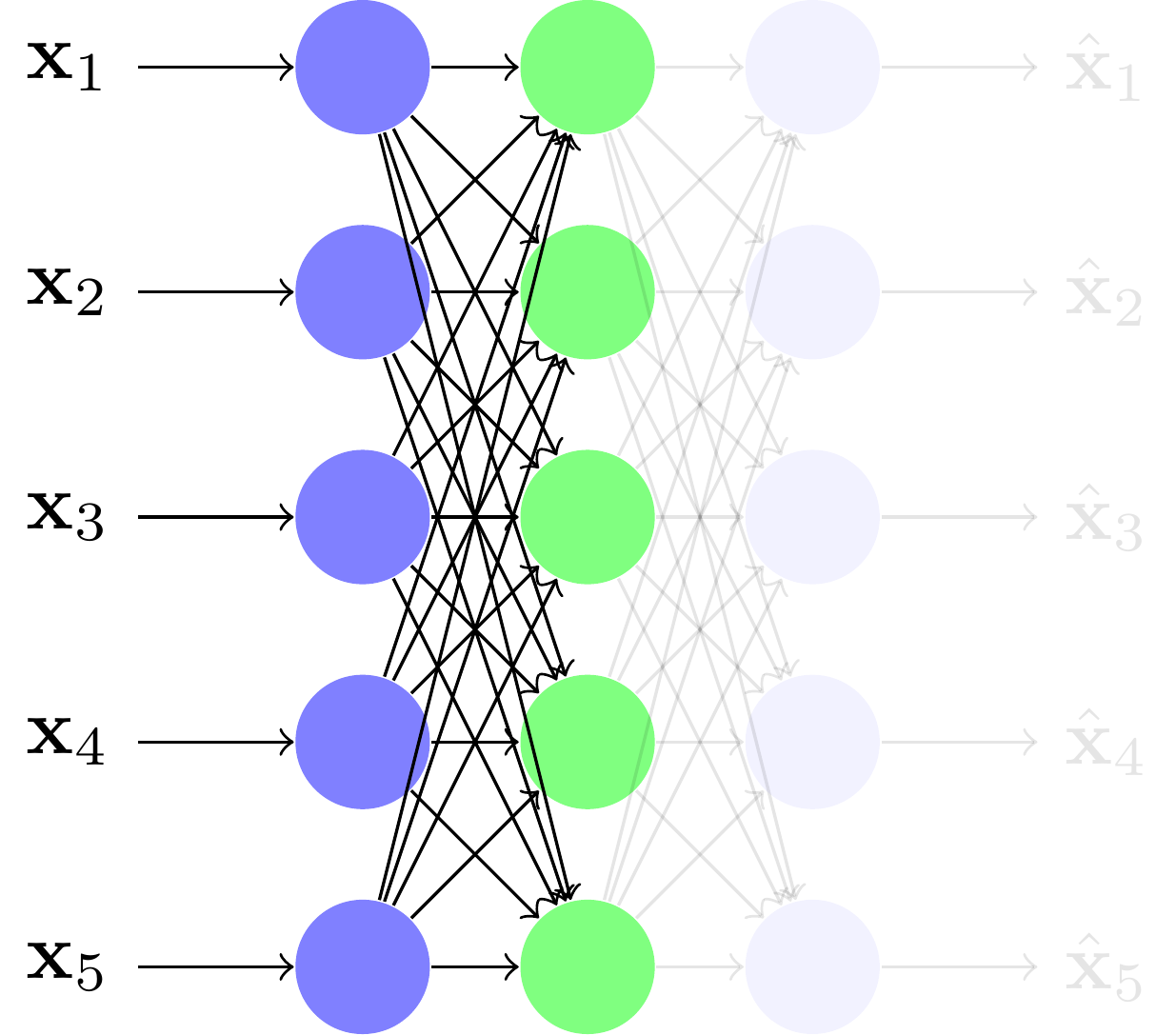
On peut d'abord apprendre un autoencodeur sur une base de caractères.
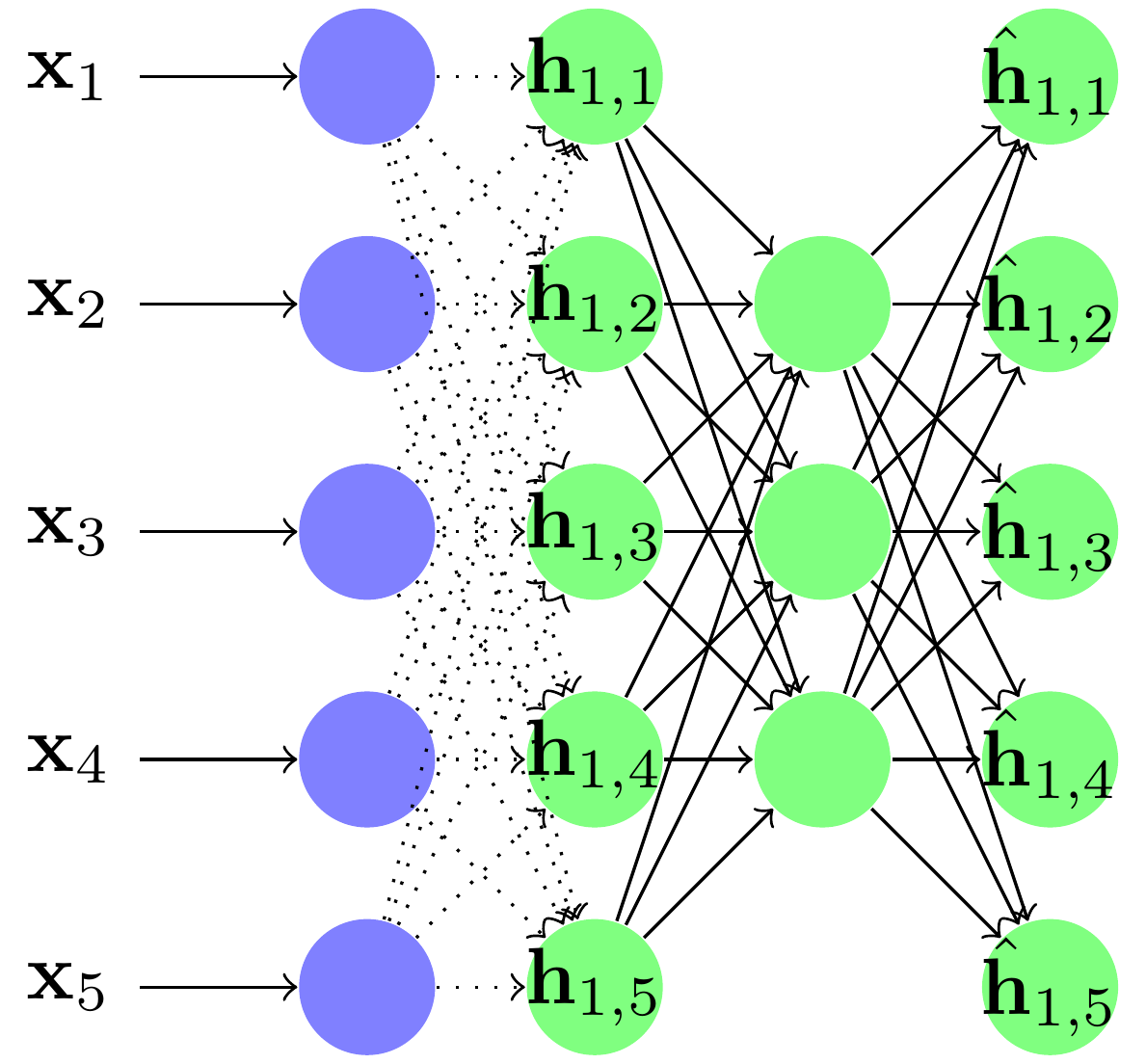
On garde l'encodeur comme première couche d'un réseau PMC classique, et on fixe ses paramètres.
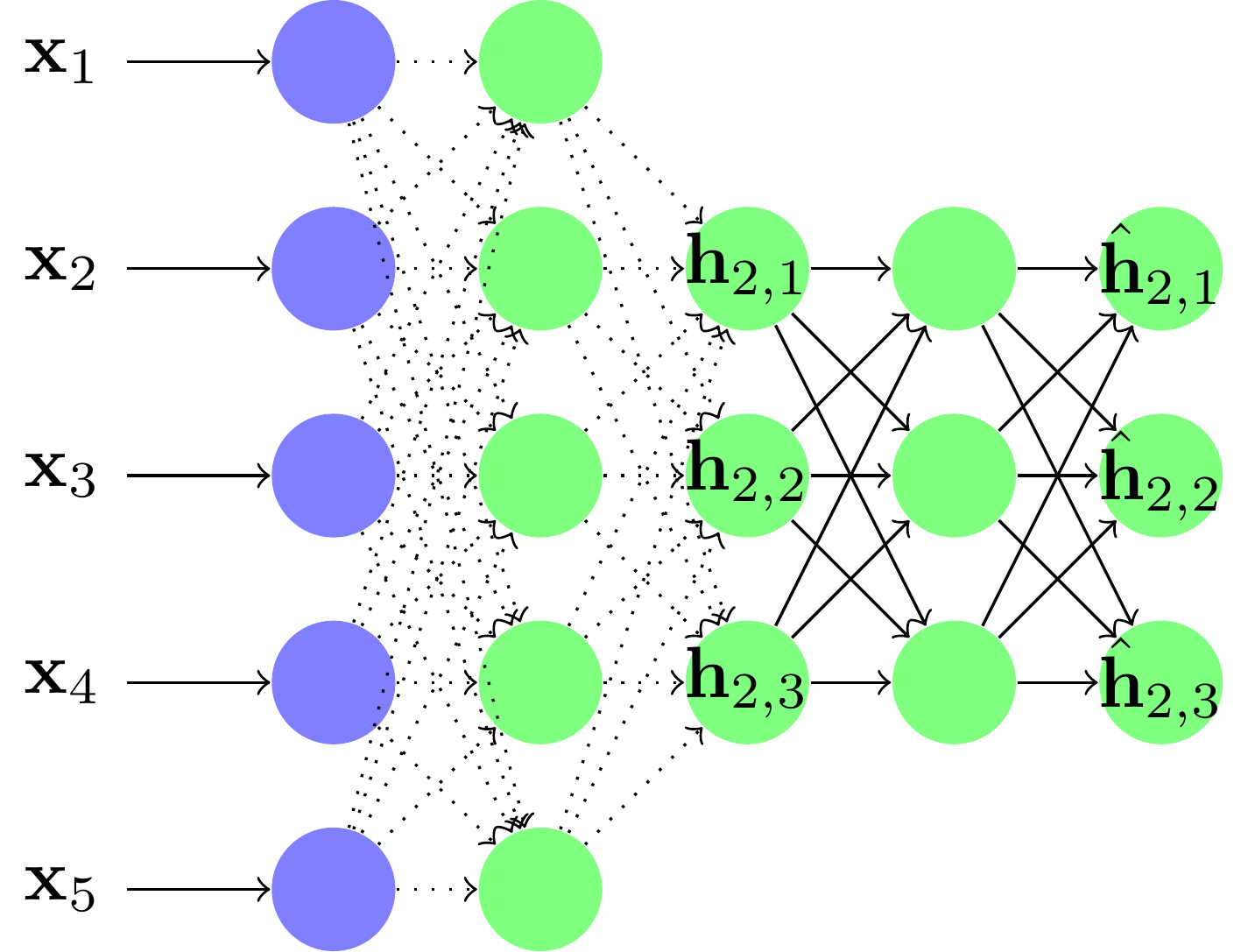
On dit que la première couche du réseau a été préentraînée de manière non supervisée. On prend la sortie de l'encodeur et on l'apprend dans un nouvel autoencodeur.
Et ainsi de suite...
On finit l'apprentissage de toutes les couches (y compris la première) par un apprentissage supervisé classique appelé fine-tuning.
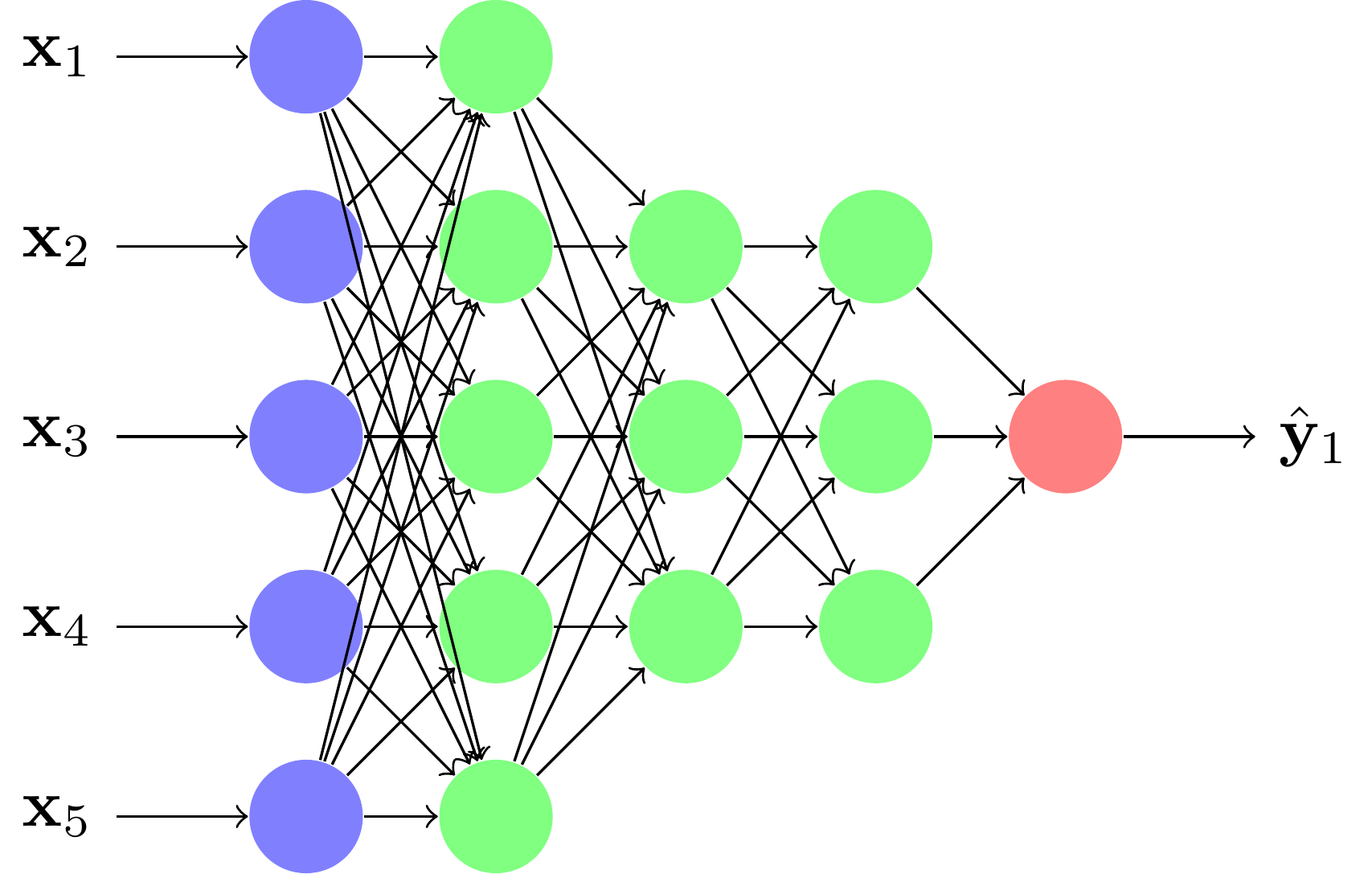
On peut multiplier les couches préapprises et les couches du PMC pour des problèmes de grandes dimensions. On appelle alors le réseau de neurones un réseau de neurones profond ou Deep Neural Network (DNN).
Problématique du gradient évanescent liée aux réseaux profonds
En effet, lorsque les unités des couches supérieures sont saturées, peu de gradient est transmis aux couches précédentes. Par exemple, pour la fonction tanh en dessous de -4 et au-dessus de +4, le gradient est très faible :
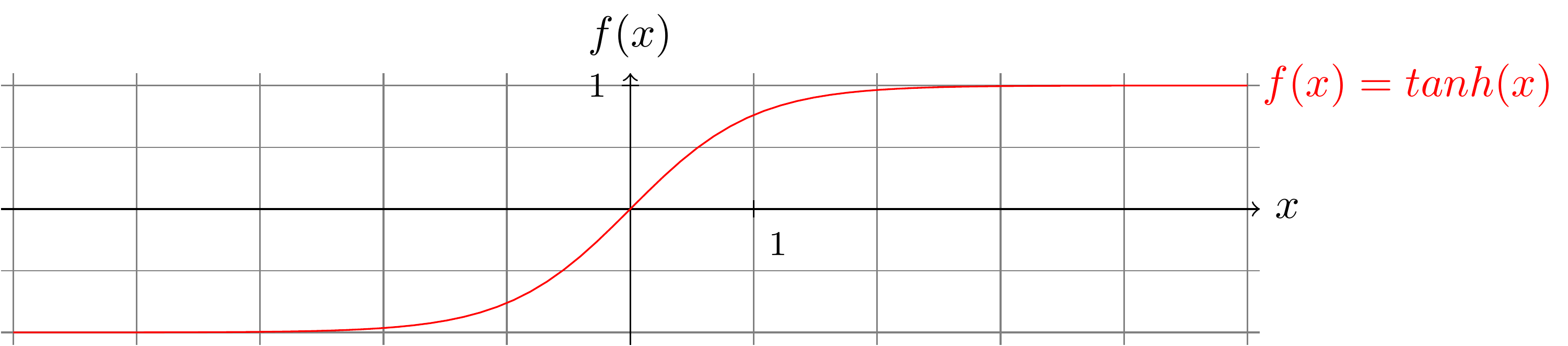
Plus il y a de couches, plus ce phénomène, appelé gradient évanescent ou vanishing gradient, est problématique.
Comment passer outre ? notamment dans le cadre du traitement des images ?
Nous allons le voir au prochain chapitre.
Allez plus loin
LeCun, Y., Bottou, L., Bengio, Y., & Haffner, P. (1998). Gradient-based learning applied to document recognition. Proceedings of the IEEE, 86(11), 2278-2324.
Bourlard, H., & Kamp, Y. (1988). Auto-association by multilayer perceptrons and singular value decomposition. Biological cybernetics, 59(4-5), 291-294.
Vincent, P., Larochelle, H., Lajoie, I., Bengio, Y., & Manzagol, P. A. (2010). Stacked denoising autoencoders: Learning useful representations in a deep network with a local denoising criterion. Journal of machine learning research, 11(Dec), 3371-3408.
En résumé
Nous avons vu dans ce chapitre une forme spéciale de réseau de neurones en couches appelée autoencodeur, ou réseau diabolo. Elle est premièrement adaptée à une tâche d'apprentissage non supervisé, comme la réduction de dimension. Cependant, elle effectue ainsi une extraction de caractéristiques. Nous utilisons cette propriété dans l'apprentissage profond, un type d'apprentissage où le réseau de neurones attaque directement les données brutes et réalise lui-même l'extraction de caractéristiques. Cependant, il est difficile d'apprendre un tel réseau à cause du gradient évanescent.
