Initiez-vous aux problématiques liées au traitement de séquences
Dans ce chapitre, nous allons comprendre les limites des modèles de deep learning basés sur les réseaux en couches simples et découvrir les modèles de deep learning dédiés aux séquences.
Les limites des architectures "feedforward"
Dans la première partie de ce cours, nous avons découvert les réseaux de neurones dits feedforward, dans lesquels l'information transite des entrées vers les sorties. Les perceptrons multicouches (PMC, ou MLP pour MultiLayer Perceptrons, en anglais) et les réseaux convolutionnels (CNN) rentrent dans cette catégorie.
Aujourd'hui, ces modèles sont la référence pour l'apprentissage machine, car ils ont de nombreux avantages :
performances à l'état de l'art ;
rapides en décision (mais longs en apprentissage !) ;
supportent très bien des hautes dimensions en entrée et/ou en sortie ;
capables d'extraire des caractéristiques automatiquement, notamment sur les images avec les CNN ;
existence d'un algorithme efficace d'apprentissage : la rétropropagation du gradient.
Limites liées à la taille des données
Malheureusement, les modèles feedforward ont également une contrainte importante : la taille de l'entrée et la taille de sortie doivent être identiques pour tous les exemples à traiter, aussi bien en apprentissage qu'en décision.
Dans la pratique, dans la plupart des domaines où l'on est susceptible d'utiliser des réseaux de neurones, cette contrainte n'est pas vérifiée. Voici quelques exemples :
reconnaissance de signaux tels que la parole ou l'écriture : ces signaux ne font jamais la même taille ;
classifier automatiquement des avis sur des sites marchands : les avis sont plus ou moins longs ;
traduction automatique : la taille des textes à traduire est variable.
Dans ce dernier exemple, les données sont de taille variable aussi bien en entrée qu'en sortie du modèle. Dans certains problèmes, la taille des données d'entrée peut être différente de la taille des données de sortie. En restant dans l'exemple de la traduction automatique :
"How are you?" -> "Comment vas-tu ?" (3 mots -> 3 mots).
"I am fine, thank you" -> "Je vais bien, merci" (5 mots -> 4 mots).
L'astuce de la fenêtre glissante
Afin de traiter les signaux de taille variable, une astuce très répandue consiste à utiliser une "fenêtre glissante" qui va se déplacer dans le sens de parcours du signal pour l'analyser. À chaque déplacement, le contenu de la fenêtre sera soumis à un classifieur statique, tel qu'un réseau de neurones feedforward.
Prenons l'exemple de la reconnaissance d'écriture manuscrite :
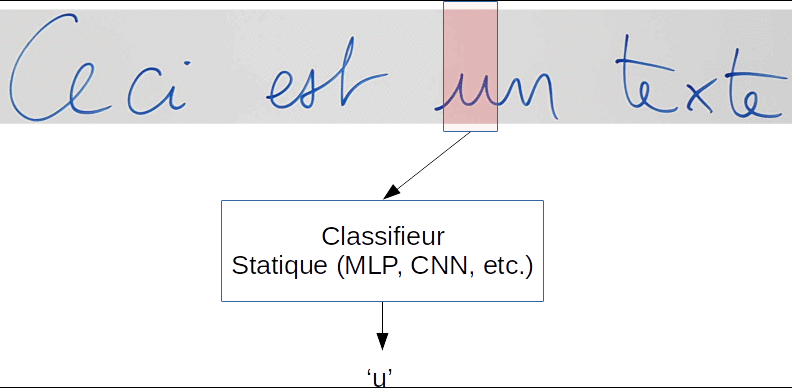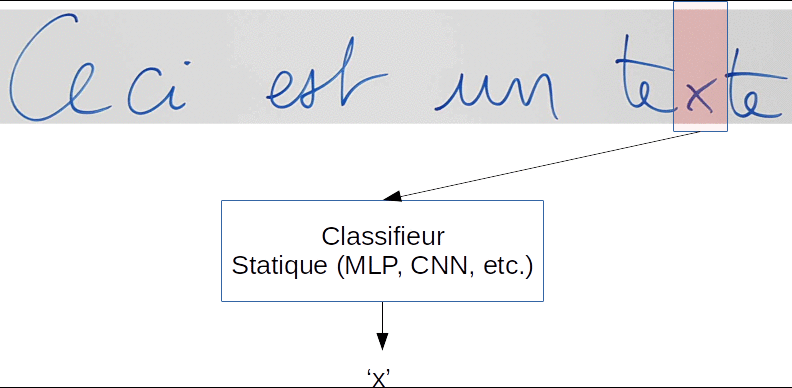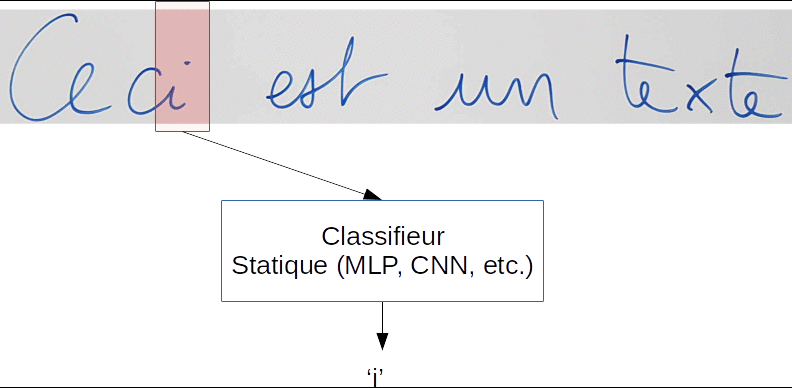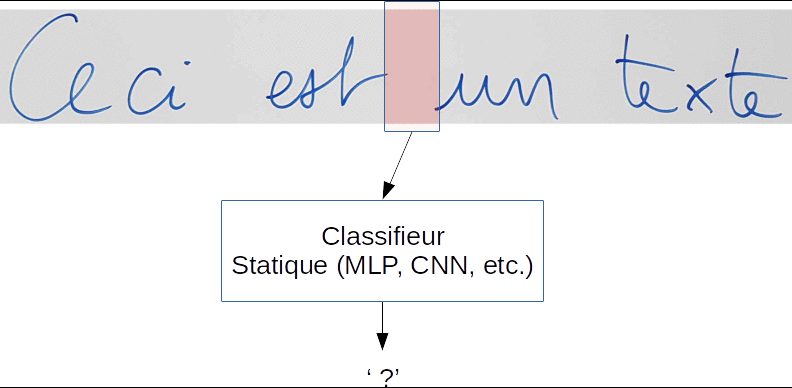
Dans cet exemple, un classifieur statique de type CNN ou MLP entraîné sur des caractères isolés devrait être capable de produire la séquence finale attendue :
"Ceci?est?un?texte"
Vous pouvez noter la présence d'une classe de caractère spécial '?' pour modéliser les espaces, et qui peut également modéliser un doute sur le caractère présent, notamment lorsque le caractère est mal écrit, ou lorsque la fenêtre est à cheval sur plusieurs caractères.
Limites liées aux dépendances entre les données
Par exemple, essayez de reconnaître le signal suivant :

Un deux ___ quatre cinq
Il est facile pour un être humain de reconnaître cette séquence malgré la rature, car nous sommes capables d'analyser le contexte du reste de la phrase. En revanche, pour une machine, la reconnaissance du mot raturé sera beaucoup plus compliquée ! En effet, l'astuce de la fenêtre glissante ci-dessus donnera probablement la séquence suivante :
"un?deux??????quatre?cinq", qui n'est pas la bonne réponse...
Voici un autre exemple : saurez-vous deviner le mot manquant dans cette séquence ?
"En me rasant ce matin, je me suis ____"
Là aussi, c'est très facile pour nous ! Il nous suffit de nous souvenir du début de la phrase pour en deviner la fin. Mais pour un réseau de neurones, comment procéder à la reconnaissance ?
Idéalement, nous aimerions que les réseaux de neurones soient doués de notre faculté de mémoire !
Dans la section suivante, nous allons voir comment les réseaux de neurones feedforward peuvent être modifiés et adaptés au traitement de séquences, c'est-à-dire leur donner la capacité de gérer des signaux de taille variable, tout en leur donnant une mémoire de ce qu'il ont vu auparavant.
Pour cela, nous allons reprendre l'astuce de la fenêtre glissante, mais allons donner au classifieur la possibilité d'avoir une mémoire. C'est le rôle des réseaux de neurones récurrents (ou Recurrent Neural Networks, RNN en anglais).
En résumé
Dans ce chapitre, nous avons constaté que les réseaux de neurones statiques de type CNN ou MLP ne sont pas adaptés au traitement de séquences de taille variable.
L'astuce de la fenêtre glissante permet de s'affranchir de cette limitation, mais ne permet pas au réseau d'avoir une mémoire. Les réseaux récurrents vont solutionner ce problème.
