Construisez des réseaux profonds grâce aux couches convolutionnelles
Dans ce chapitre, nous allons apprendre à construire un réseau profond spécifique de la modalité image, grâce aux couches convolutionnelles.
Problématiques liées aux réseaux profonds
Nous avons vu, dans le chapitre précédent, qu'une des difficultés liées aux réseaux de neurones profonds est le fait que le gradient n'arrive pas suffisamment à atteindre les couches basses pour pouvoir faire l'apprentissage.
Dans l'illustration suivante, nous voyons une implémentation naïve d'un réseau de neurones artificiels (RNA) pour une image.
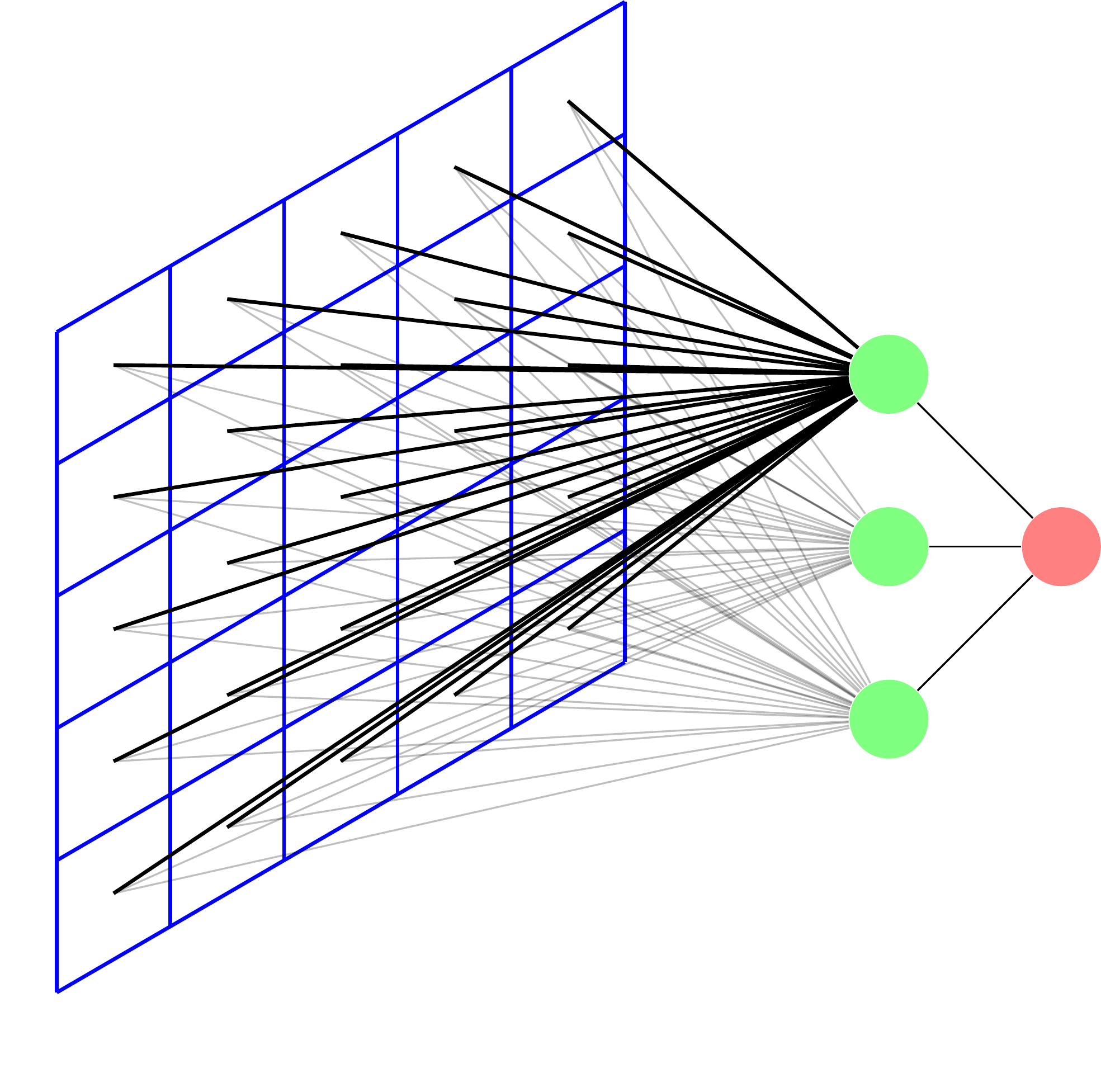
Chaque pixel est relié à toutes les unités de la première couche. On appelle cela une couche complètement connectée (fully connected, en anglais). Il en résulte un nombre très élevé de paramètres, qui sont en outre difficilement modifiables par descente de gradient.
Utilisez la topologie des données
Une solution possible est de tenir compte de la nature et de la topologie des données. Généralement, les caractéristiques issues des images sont calculées grâces à des filtres.
Pourquoi ne pas reprendre l'idée des filtres, mais dans le cadre d'un RNA ?
Regardons tout d'abord le filtre convolutionnel standard suivant :
-1 | 0 | 1 |
-1 | 0 | 1 |
-1 | 0 | 1 |
Il s'agit d'un masque de convolution qui vient calculer une caractéristique en balayant l'image. Le masque est fixe et a été choisi ici à l'avance pour faire de la détection de contours (horizontaux).
Prenons l'image ci-dessous :
| 0 | 0 | 0 | 1 | 1 |
| 0 | 0 | 0 | 1 | 1 |
| 0 | 0 | 0 | 1 | 1 |
1 | 1 | 1 | 1 | 1 |
1 | 1 | 1 | 1 | 1 |
en lui appliquant ce filtre convolutionnel, on obtient l'image suivante :
| 0 | 0 | 1 | 1 | 0 |
| 0 | 0 | 1 | 1 | 0 |
| 0 | 0 | 1 | 1 | 0 |
| 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 |
Les contours horizontaux ont bien été détectés.
Couche convolutionnelle (principe)
En entrée, une couche convolutionnelle prend une image ou une carte de caractéristiques ; en sortie, on trouve une carte de caractéristiques extraite grâce à la convolution.
Passer un masque de convolution sur un signal, cela revient à ne conserver que certains poids d'une couche fully connected d'un RNA. La figure suivante illustre les connections que l'on garde :
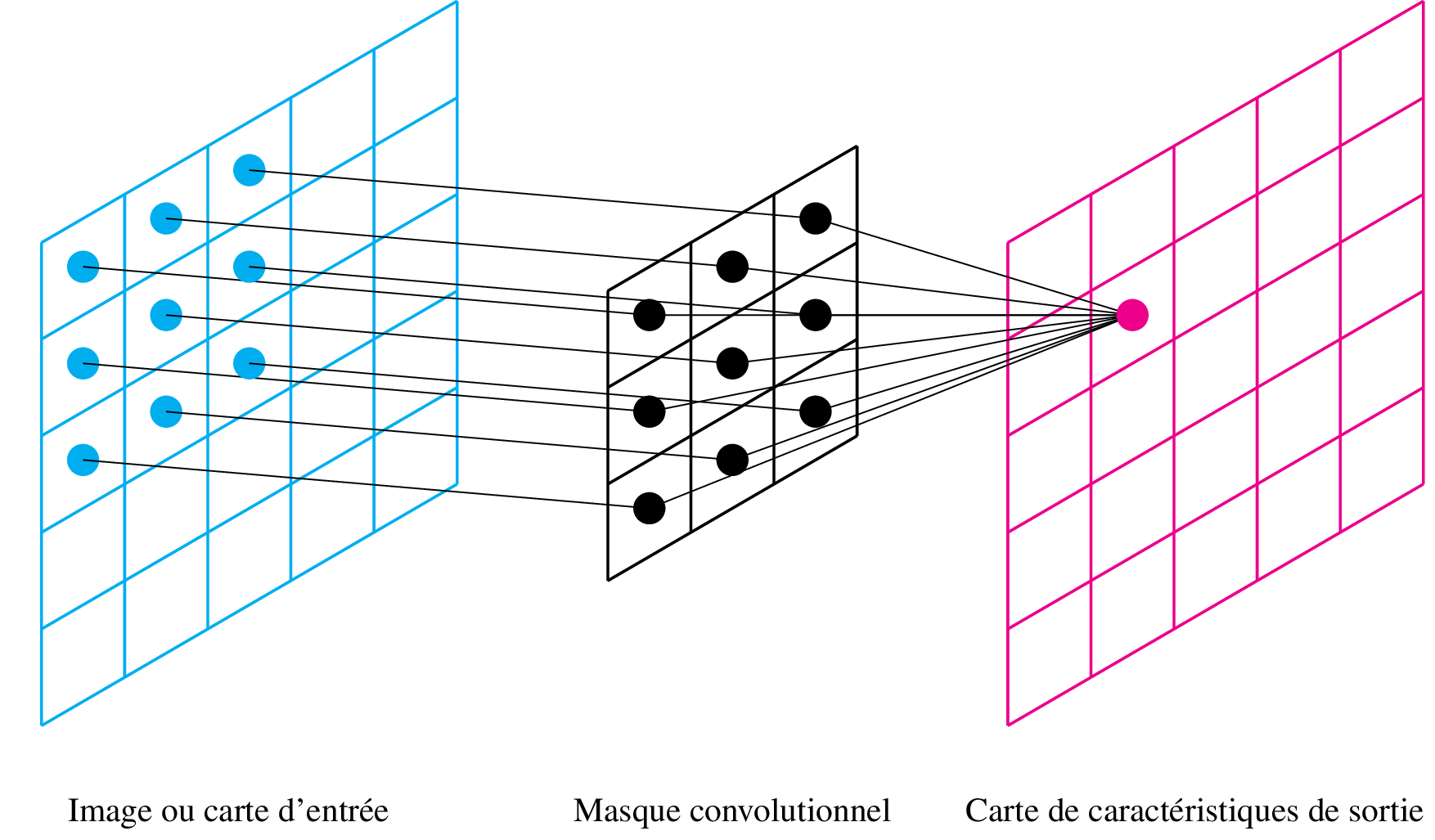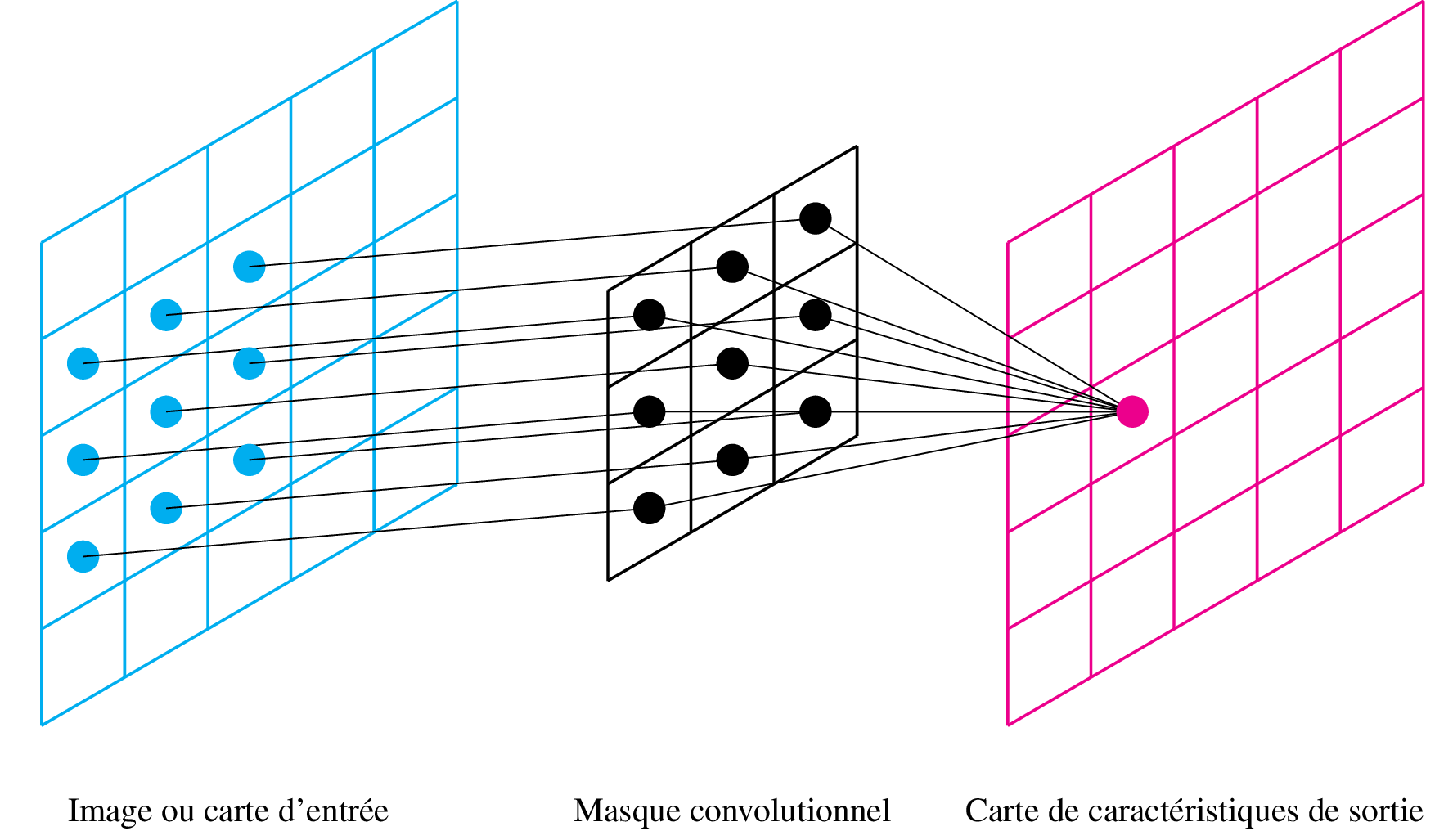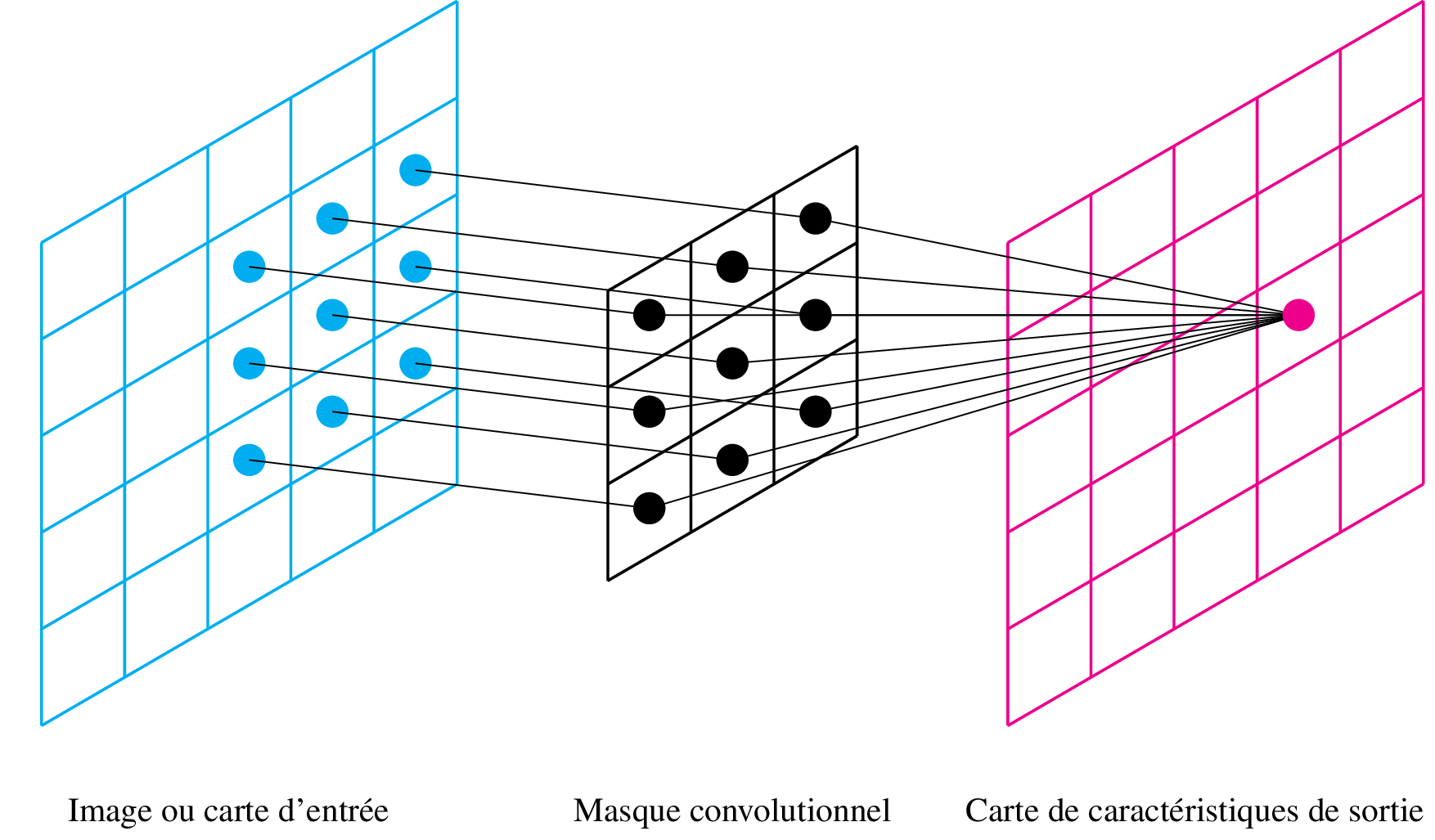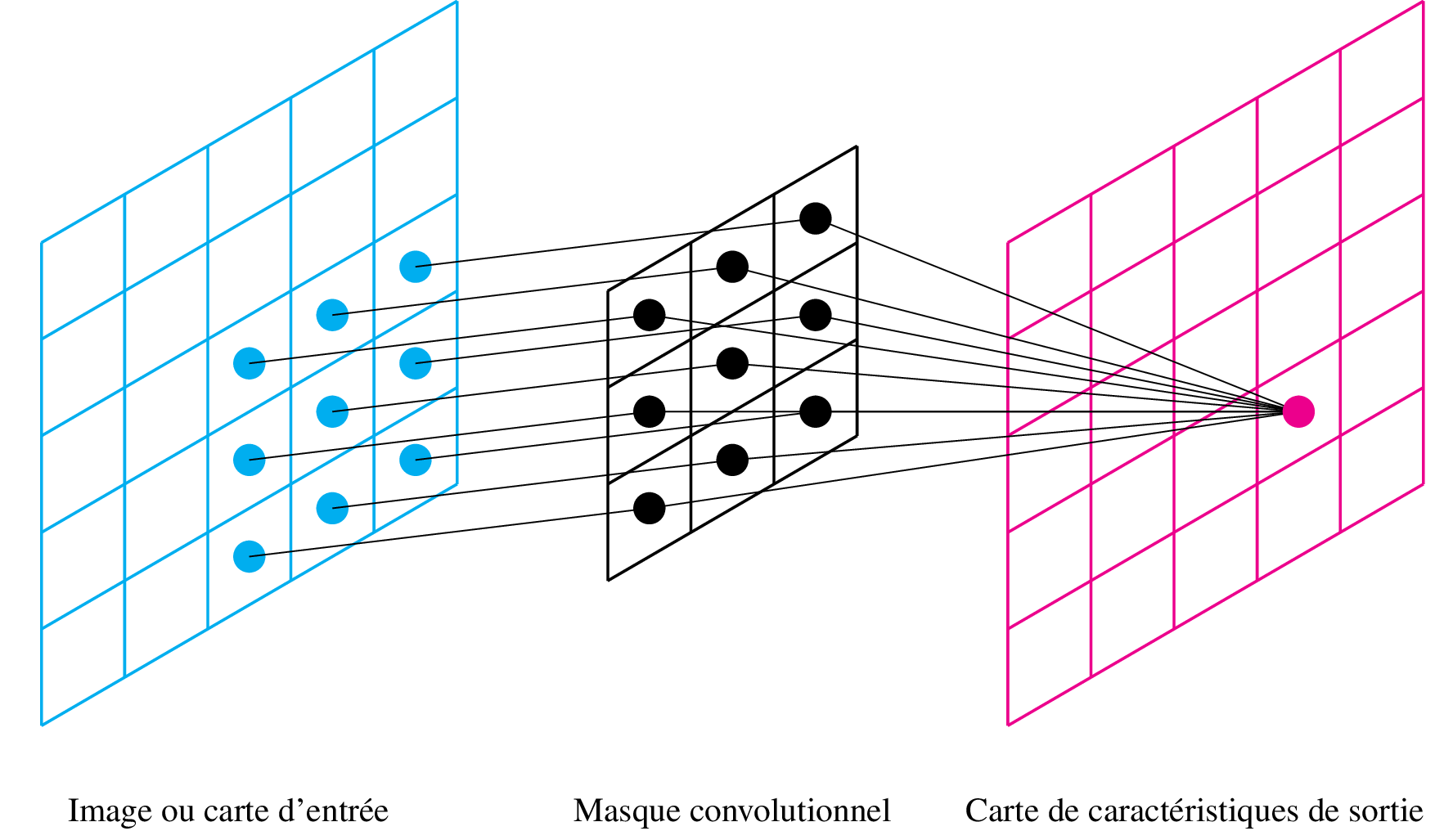
Les poids d'un masque convolutionnel (ici en noir) sont traitables de la même manière qu'une couche complètement connectée par descente de gradient. Ces couches convolutionnelles ont le grand avantage de réduire le nombre de paramètres, et donc de réduire le phénomène de gradient évanescent.
Architecture globale d’un réseau convolutionnel
Les couches convolutionnelles peuvent être empilées pour former un réseau ; elles sont accompagnées de couches dites de pooling qui permettent de réduire la taille des cartes de caractéristiques, et de couches de batch normalization qui effectuent un recentrage et une normalisation des données. Dans le cadre d'une tâche de classification, le DNN se termine par une ou plusieurs couches complètement connectées.
Voici une illustration d'un réseau profond complet :
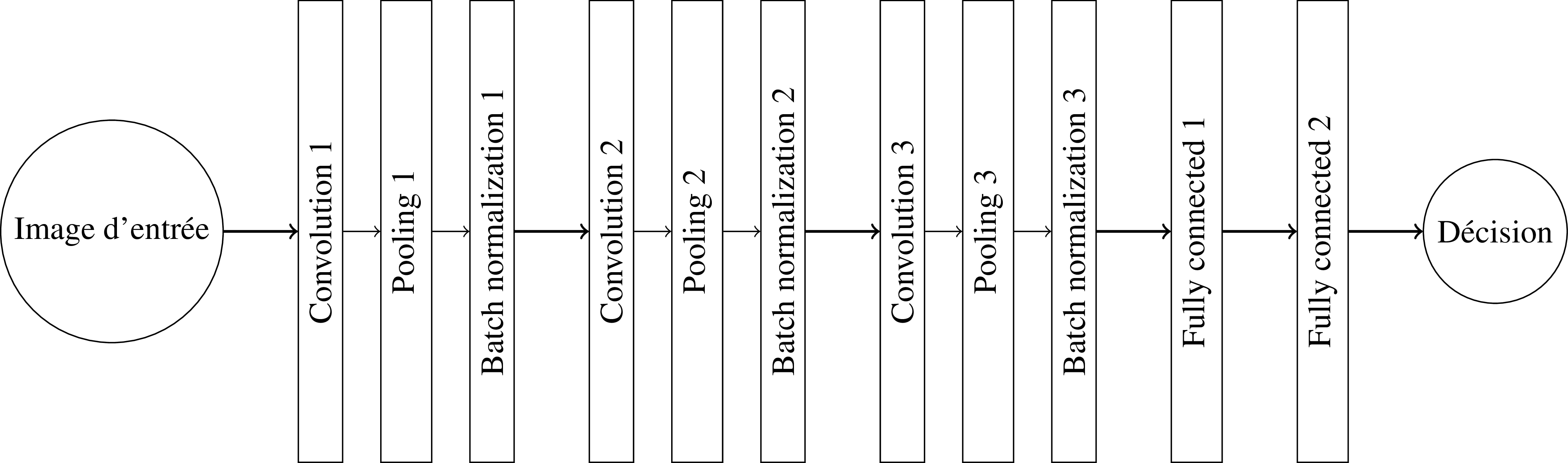
Ce réseau contient 3 séries de couches convolutionnelles, pooling et batch normalization, puis de deux couches fully connected. Nous avons déjà vu les couches fully connected dans les chapitres précédents. Nous allons donner quelques détails supplémentaires à la couche convolutionnelle introduite dans la section précédente, et décrire pooling et batch normalization.
Détails sur les couches convolutionnelles
Fonction d'activation
Afin, d'une part, d'éviter la saturation des unités et d'autre part, de diminuer le phénomène d'évanescence du gradient, on peut utiliser comme fonction d'activation, une fonction qui ne présente pas de palier. Typiquement, c'est la fonction relu ou une approchée dérivable comme la softplus qui seront utilisées pour les couches convolutionnelles.
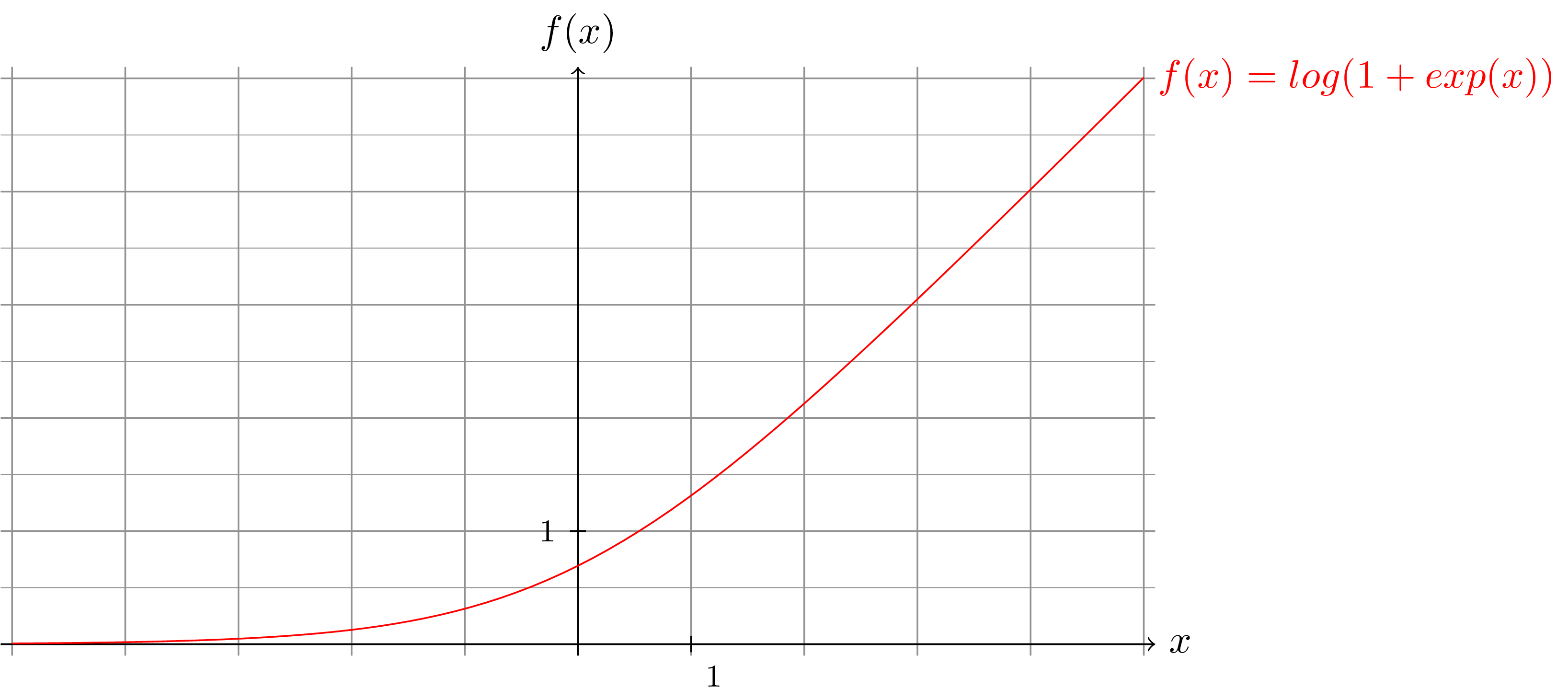
Cette fonction a toujours un gradient suffisamment grand pour des valeurs de positives.
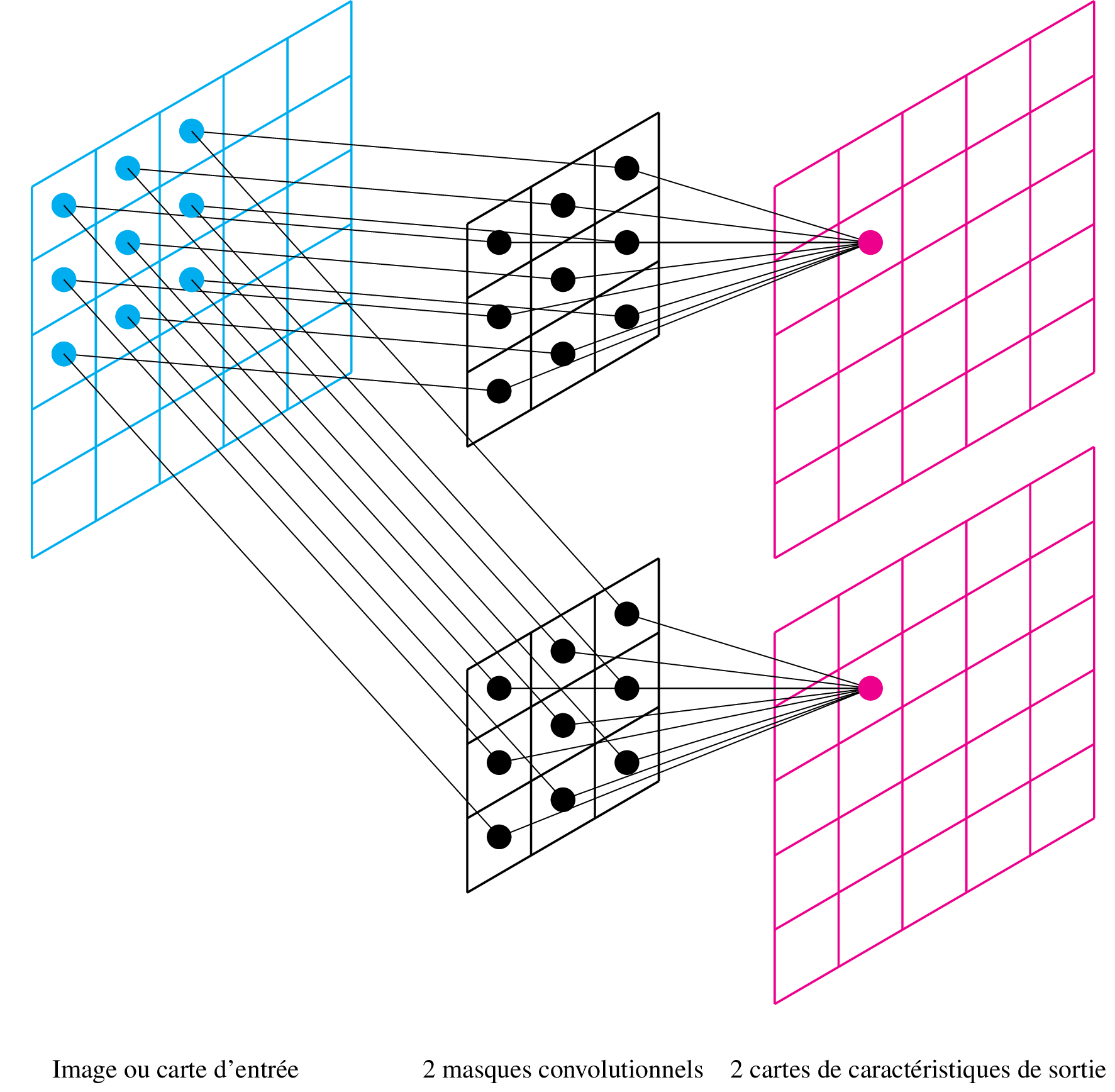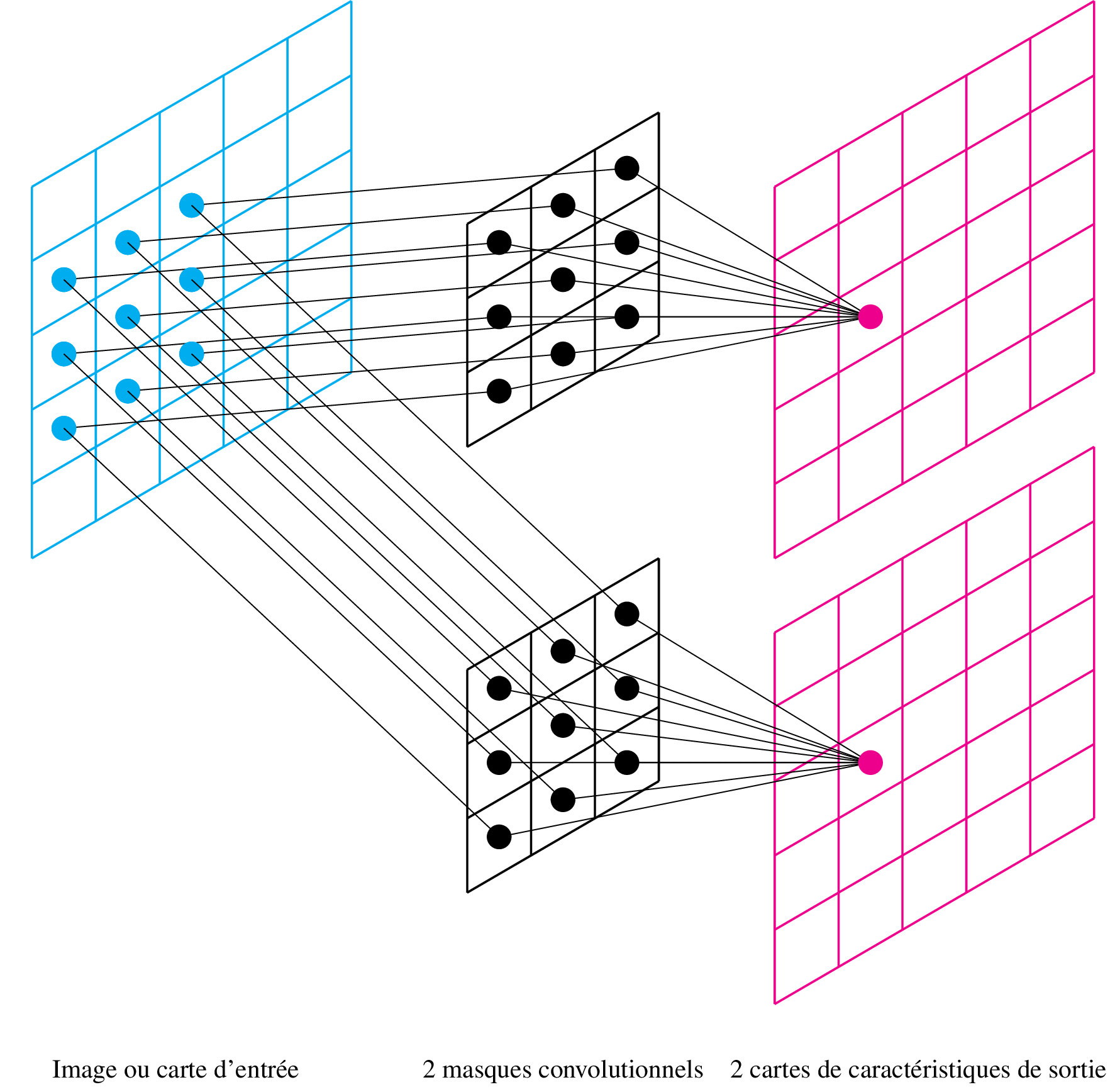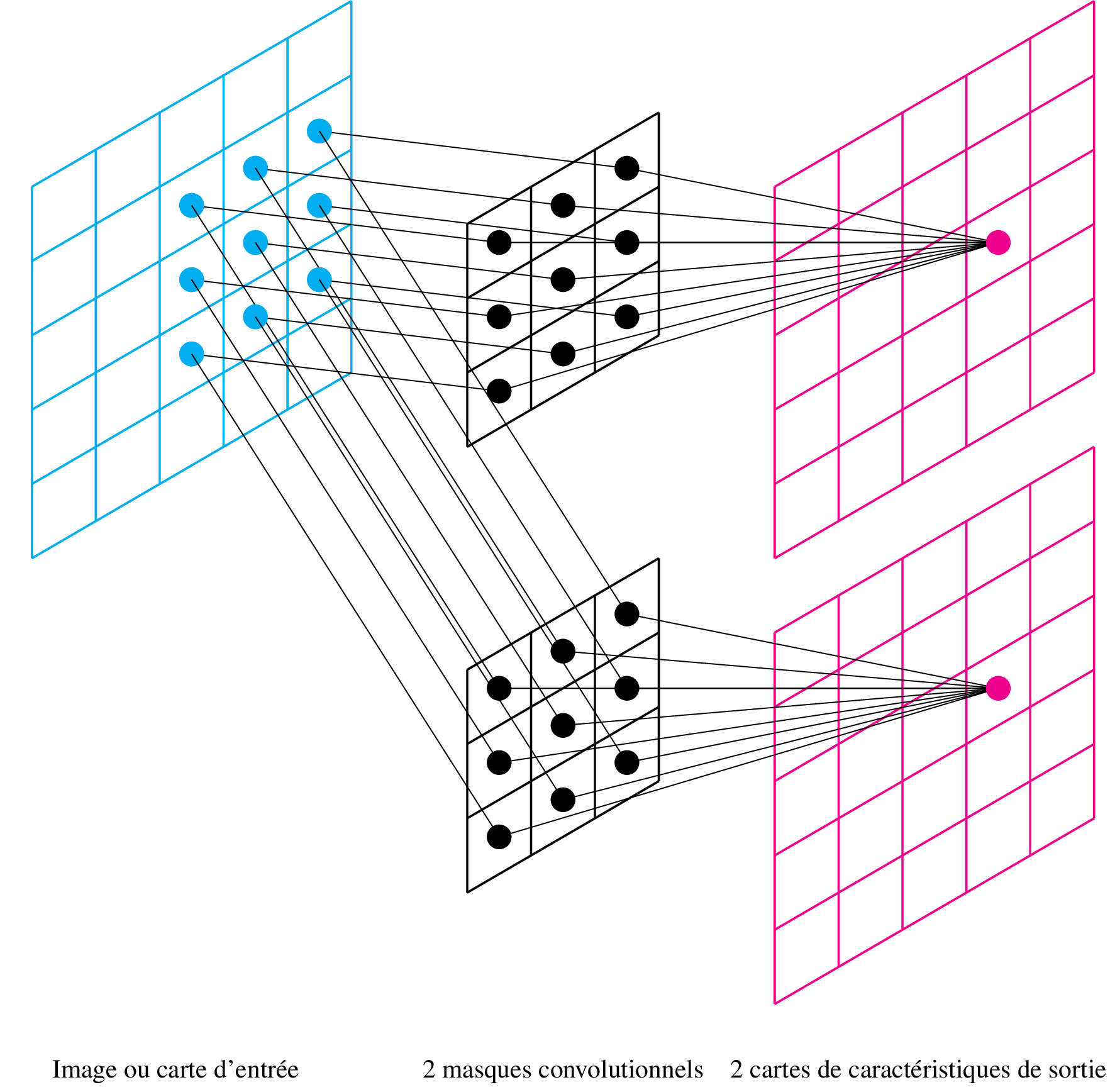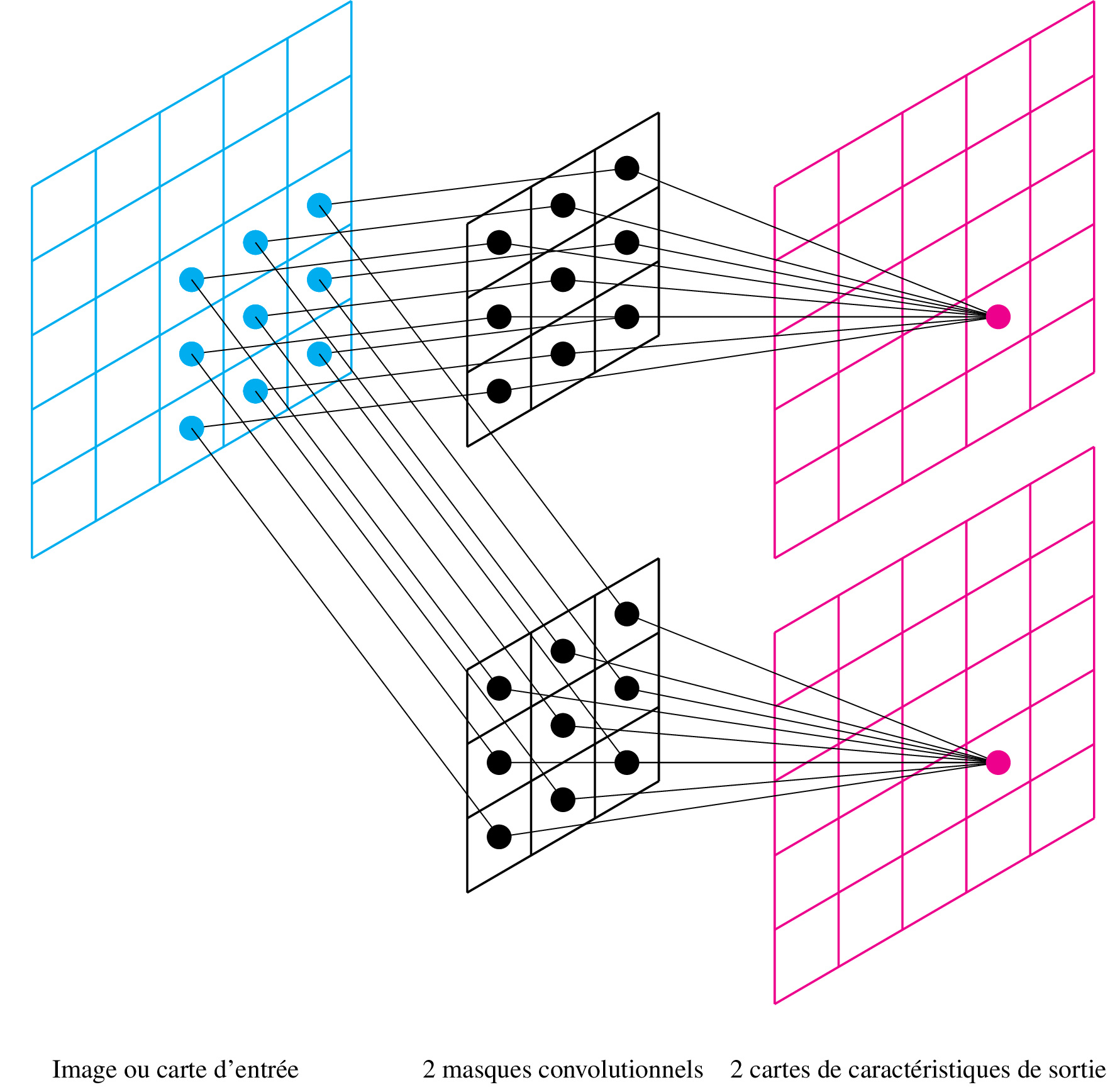
Cartes multiples
Lorsque n filtres sont utilisés dans une même couche, on génère n cartes de sortie en parallèle :
Couche Pooling
La couche de pooling consiste à un rééchantillonnage des données. Celui-ci peut se faire suivant divers opérateurs, comme la moyenne et le max. Dans une tâche de classification, la localisation des caractéristiques étant peu importante, un pooling avec un opérateur max sera préféré.
Observons la carte suivante :
1 | 2 | 1 | 2 | 1 | 2 | 1 | 2 | 1 |
2 | 1 | 2 | 1 | 2 | 1 | 2 | 1 | 2 |
1 | 2 | 1 | 2 | 1 | 2 | 1 | 2 | 1 |
2 | 3 | 2 | 3 | 2 | 3 | 2 | 3 | 2 |
3 | 1 | 3 | 1 | 3 | 2 | 3 | 2 | 3 |
1 | 3 | 1 | 3 | 2 | 3 | 4 | 3 | 4 |
2 | 1 | 2 | 1 | 3 | 2 | 3 | 4 | 3 |
1 | 2 | 1 | 2 | 1 | 3 | 4 | 3 | 4 |
1 | 1 | 1 | 1 | 2 | 2 | 3 | 4 | 3 |
Nous allons appliquer un pooling de taille 3 par 3. Sur les carrés de 3x3 pixels, seul le pixel de valeur maximum est retenu en sortie. On obtient alors la carte suivante :
2 | 2 | 2 |
3 | 3 | 4 |
2 | 3 | 4 |
Couche Batch Normalization
La couche de batch normalization est une autre technique de réduction du phénomène d'évanescence du gradient, lorsque des fonctions du type relu ne sont pas utilisées. Elle permet de maintenir les exemples d'un batch dans la zone non saturée d'une unité. Par exemple, la zone proche de 0 dans la fonction tangente hyperbolique :
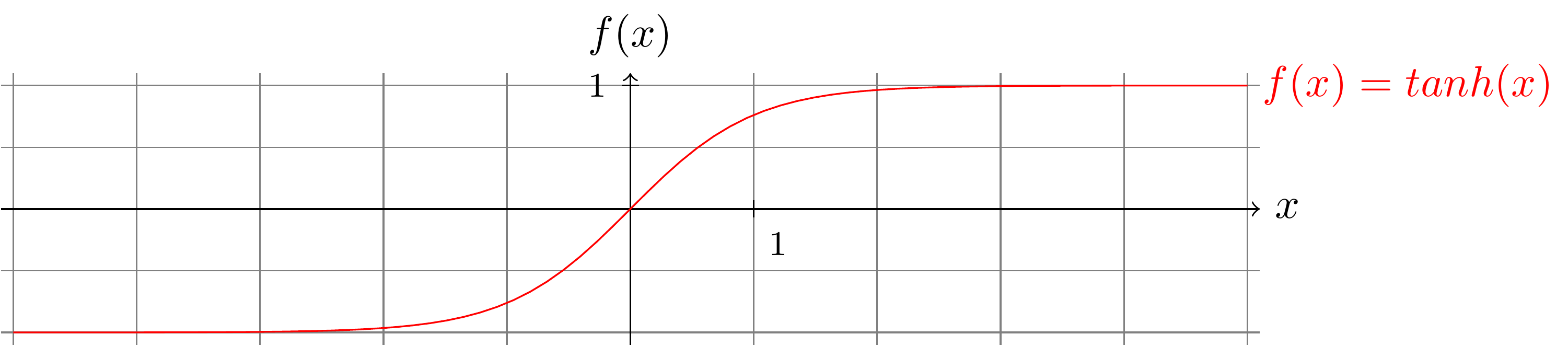
La normalisation est effectuée dimension par dimension, batch par batch.
Ainsi, pas de matrice de covariance, et les moments (moyennes variances) sont ceux du batch courant.
Mais comment calculer la rétropropagation ?
En effet, ce n'est pas linéaire : la moyenne et la variance dépendent de !
Les équations de mise à jour ne sont pas simples ; il faut d'abord calculer le gradient par rapport aux moments, puis par rapport à l'exemple :
où est la taille du batch.
Réseaux disponibles (AlexNet, VGG...)
Il existe de nombreux réseaux préappris sur des bases du type ImageNet (plusieurs millions d'images, plusieurs milliers de catégories) ; cf. l'article Deng, J., Dong, W., Socher, R., Li, L. J., Li, K., & Fei-Fei, L. (2009, June). Imagenet: A large-scale hierarchical image database. In Computer Vision and Pattern Recognition, 2009. CVPR 2009. IEEE Conference on (pp. 248-255). Ieee. [pdf].
On peut citer par exemple les réseaux AlexNet et VGG :
Krizhevsky, A., Sutskever, I., & Hinton, G. E. (2012). Imagenet classification with deep convolutional neural networks. In Advances in neural information processing systems (pp. 1097-1105). [pdf].
K. Simonyan, A. Zisserman. Very Deep Convolutional Networks for Large-Scale Image Recognition arXiv technical report, 2014 [pdf].
Le nombre suivant le nom indique le nombre de couches. Par exemple, dans VGG16, le réseau contient 16 couches !
Transfer Learning
Ces réseaux peuvent être réutilisés comme initialisation (avant réapprentissage), lorsque par exemple le nombre d'exemples n'est pas suffisant pour apprendre un réseau complet.
On parle de transfert d'apprentissage ou transfer learning ; cf. la figure 5 de l'article suivant : Belharbi, S., Chatelain, C., Hérault, R., Adam, S., Thureau, S., Chastan, M., & Modzelewski, R. (2017). Spotting L3 slice in CT scans using deep convolutional network and transfer learning. Computers in biology and medicine, 87, 95-103. [pdf].
Dans l'illustration, les couches basses convolutionnelles d'un réseau appris sur ImageNet comme VGG16 sont utilisées comme couches basses d'un nouveau réseau. On a enlevé les couches fully connected de VGG16 et rajouté de nouvelles couches fully connected adaptées à la problématique courante. Les couches venant de VGG16 ont gardé leur poids ; les nouvelles couches ont des poids tirés au hasard. On réapprend tout le réseau, y compris les couches basses. Cela marche même sur des images non naturelles.
Allez plus loin
LeCun, Y., Bengio, Y., & Hinton, G. (2015). Deep learning. Nature, 521(7553), 436.
En résumé
Nous avons vu précédemment comment un réseau de neurones profond souffrait du gradient évanescent. Ce chapitre montre une méthode permettant de surmonter ce problème, notamment sur la modalité image, grâce aux réseaux convolutionnels. Nous présentons ici les briques de base d'un tel réseau, masque de convolution, fonction d'activation spécifique, pooling et batch normalization.
