Passez d’une problématique business à la mise en production

Prenons un peu de recul avant de clore cette première partie plutôt théorique.
Un projet de Data Science a 3 grandes phases :
Définition.
Prototypage.
Production.
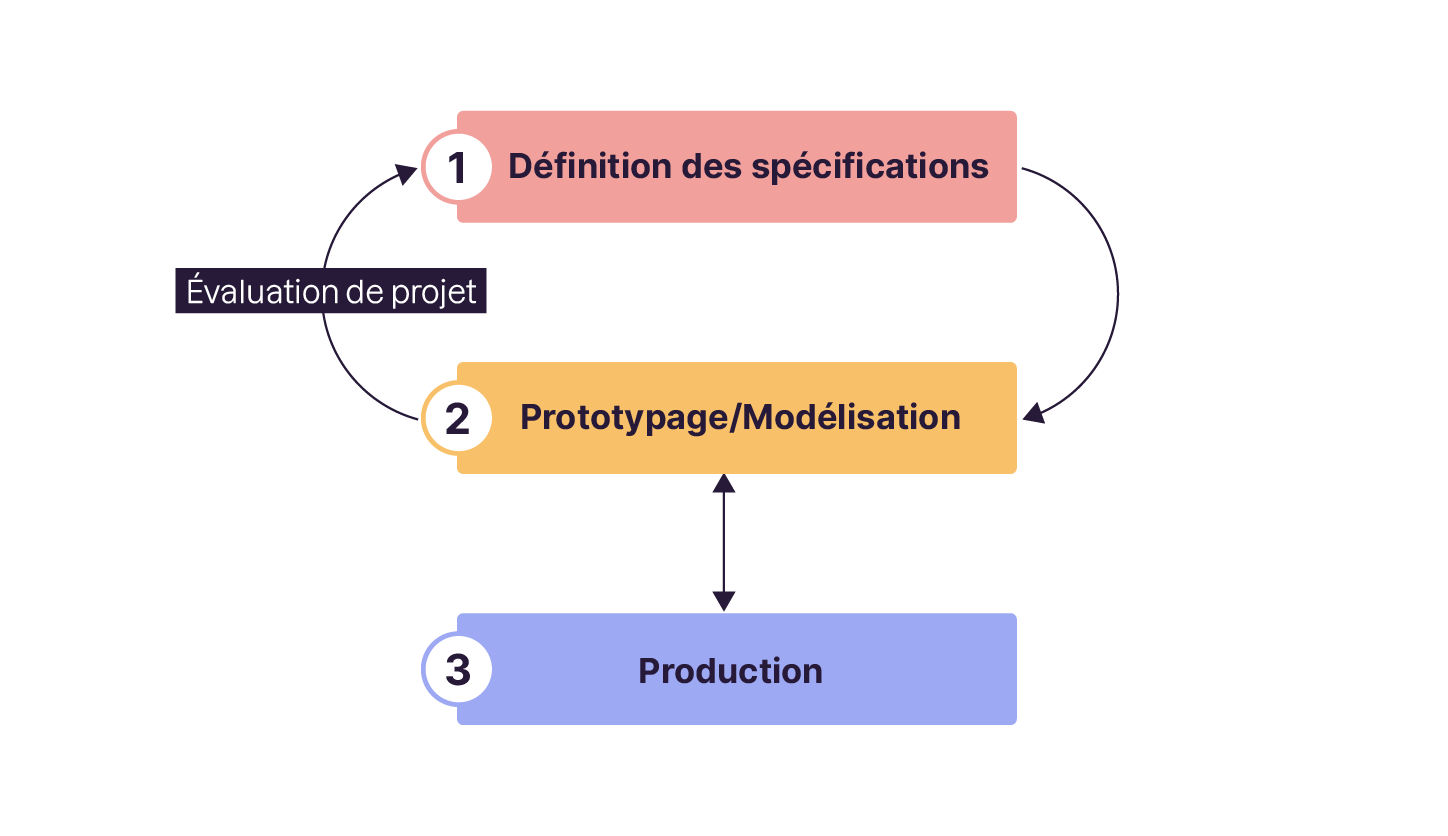
Phase 1 – Définir les spécifications à partir de la problématique business
Cette phase a pour but de traduire une problématique business, un besoin ou un produit en projet Machine Learning. De façon très générique, il faut au minimum :
des données, qui soient pertinentes ;
un sujet ou un produit qui soit proprement défini ;
et montrer qu'il y a un net avantage à exploiter l'approche prédictive plutôt qu'une solution plus simple.
Un projet de Machine Learning est une chose complexe. Avant de se lancer, il faut pouvoir calculer le gain réellement apporté par une telle démarche Machine Learning. Cela nécessite de réaliser en premier lieu une étude de benchmark. Cette étude permet aussi de poser certaines questions importantes.
Comment définir le succès du projet ?
Comment mesurer la performance du système ?
Quelle métrique utiliser pour le scoring du modèle ?
Quel score sera-t-il nécessaire d'obtenir pour réaliser les objectifs du projet ?
Voici quelques exemples de benchmarks :
Prédiction météo : on prédit que le temps du lendemain sera le même que la veille. C'est simple et cela marche souvent bien dans certaines latitudes, mais n'a évidemment que peu de dimension vraiment prédictive.
Prédiction du prix d'une course de taxi : la distance * prix/km donne une bonne approximation du prix final, mais ne prend pas en compte la dimension temps, les aléas du parcours, etc.
L'estimation des ventes d'un produit basée sur la moyenne des 3 derniers mois devrait donner une estimation raisonnable des ventes futures.
Par contre, les projets suivants auront du mal à voir le jour sans une bonne dose de Machine Learning :
prédire la défaillance d'une pièce ou d'un serveur informatique, ou le risque de défaut d'un crédit ;
classer automatiquement de grand volumes de fichiers sons ou images ;
détecter des contenus agressifs ou des fake news sur les réseaux sociaux.
Constituer un jeu de données pertinent n'est pas toujours chose aisée. La collecte préalable des données va permettre de s'assurer de leur disponibilité.
Enfin, une fois ces données collectées, il faut s'assurer qu'elles soient bien exploitables.
Peut-on extraire de l'information des échantillons ? Y a-t-il du signal exploitable ?
Sait-on ce que représentent réellement les variables ?
Quelle est la couleur du cheval blanc d'Henri IV ?
De nombreux obstacles existent donc avant de pouvoir entraîner le moindre modèle. Tout un travail en amont est nécessaire pour pouvoir aboutir enfin à l'étape de modélisation et de Machine Learning.
Phase 2 – Concevoir le prototype et valider la faisabilité du projet
Une fois fixées une version du jeu de données et une indication de benchmark de performance à dépasser, le but de l'étape de Machine Learning est d'obtenir un modèle qui soit :
performant : bon score vis-à-vis de la métrique choisie ;
et robuste : stable face à de nouvelles données.
En fonction du contexte, on pourra privilégier un modèle moins performant mais plus résilient face aux variabilités des données, à un modèle plus performant mais plus sensible aux variations.
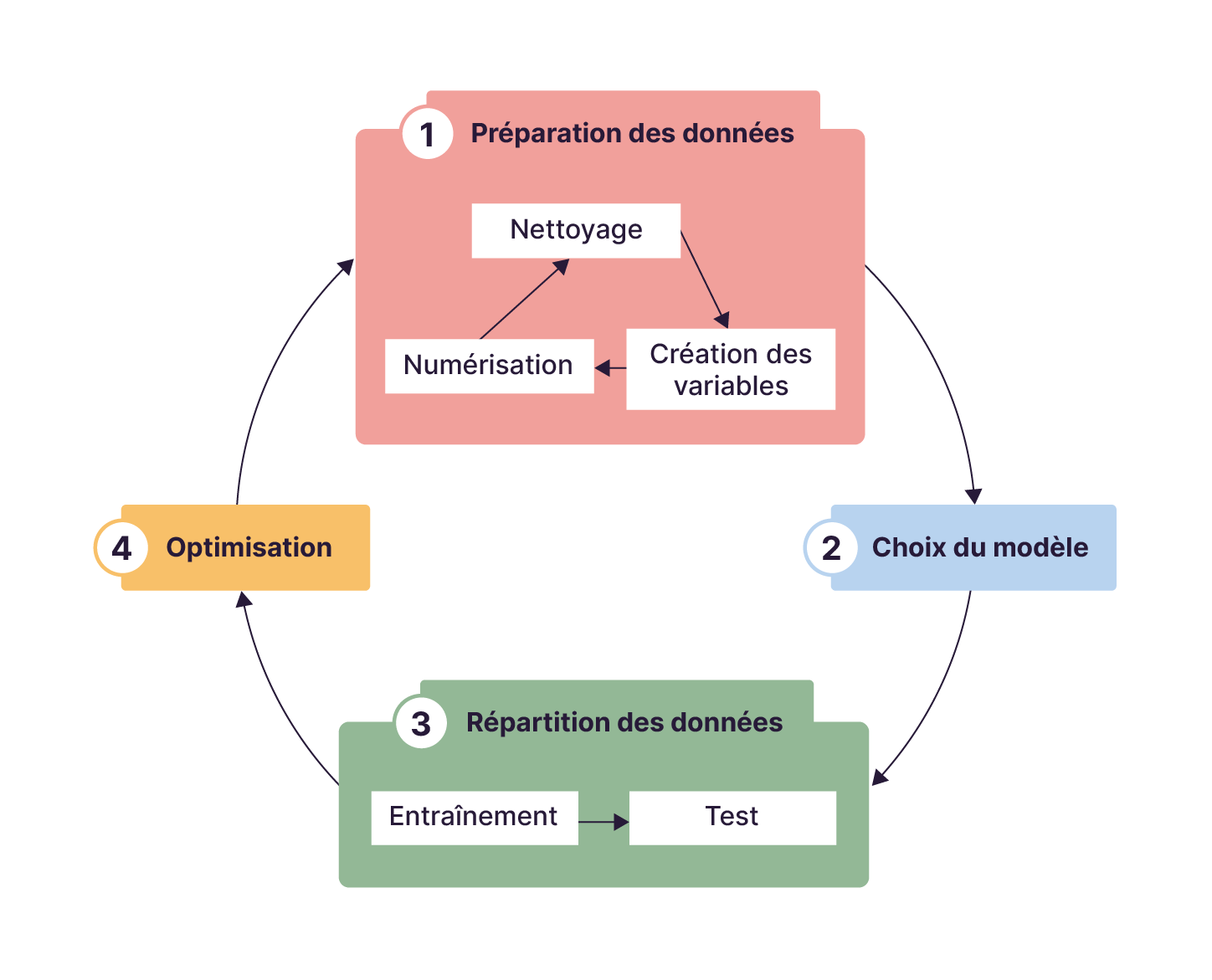
Les étapes de Machine Learning vont constituer en une série d'itérations des étapes suivantes :
étape 1 : mettre en forme des données :
nettoyer les données, c’est-à-dire résoudre les outliers (données aberrantes, en français) et les données manquantes,
créer de nouvelles variables à partir de variables existantes, feature engineering, (prendre le carré ou le long d'un prix),
numériser les données catégoriques, textuelles ou images pour qu'elles soient ingérables par un modèle ;
étape 2 : choisir le type de modèle: GLM, Tree, NN ou autre ;
étape 3 : répartir les données avec une partie réservée pour l'entraînement et l'autre pour la validation ;
étape 4 : optimiser les paramètres du modèle.
Nous reviendrons en détail sur ces différentes étapes dans les prochains chapitres.
Ce processus est itératif avec des va-et-vient réguliers entre les phases de collecte des données et leur qualification, la mise en forme des données, le choix des algorithmes, la mise en production, etc.
Phase 3 – Mettre en production le projet
Le modèle une fois optimisé a vocation à être intégré dans le produit final : on parle de mise en production. C'est alors le travail des MLOps et des DevOps qui vont prendre en charge la mise en production dans le cloud ainsi que la surveillance des modèles.
Pour bien comprendre l'importance de cette étape, pensez à la mise en production de centaines voire de milliers de modèles en parallèle, qui doivent être automatiquement :
mis à jour ;
(ré)entraînés ;
déployés ;
surveillés.
Au-delà des tâches d'intégration et de systématisation, le MLOps va devoir surveiller les modèles en production.
Comme on dit : "rien n'est permanent, sauf le changement". Il est donc probable que les conditions sous-jacentes aux données d'entraînement du modèle ne seront que transitoires. Les modèles risquent à un moment de perdre de leur efficacité et il faudra les réentraîner, les modifier (ajouter de nouvelles variables) et les redéployer.
Pensez aux crises mondiales récentes, crises économiques, guerres, pandémies, bouleversements climatiques, qui ont et qui vont continuer de chambouler de nombreux modèles de prédiction.
En résumé
Un projet de Data Science a 3 grandes phases : conception, modélisation et production.
Définir un benchmark en préalable du projet permet de valider le retour sur investissement de l'approche Machine Learning comparée à une approche plus simple et plus directe.
Un bon modèle prédictif offre de bonnes performances face à des données qu'il n'a pas rencontrées lors de son entraînement. Il sait extrapoler.
Il faut régulièrement ré-entraîner un modèle pour qu'il s'adapte aux évolutions naturelles des données.
Le MLOps est un rôle clé qui a pour responsabilité de mettre les modèles en production et de les surveiller.
Dans la seconde partie de ce cours nous allons rentrer dans le vif du sujet des étapes de développement d'un modèle prédictif.
